Анализ исходных текстов продукта
. Целью данного этапа является поиск потенциальных мест размещения элементов системы защиты, определение оптимального режима её маскировки, выявление возможных слабых мест в коде продукта, определение основных алгоритмов продукта, степени влияния на них системы защиты и возможности их модификации для использования для дополнительной защиты. Кроме этого, определяется язык программирования, на котором реализован программный продукт, а также стиль программирования и основные соглашения по построению исходного кода. В частности, нередко так называемые демонстрационные версии программных продуктов, распространяемые бесплатно, строятся из исходного кода полнофункциональных версий с внесением незначительных изменений, отключающих расширенную функциональность. В этом случае злоумышленники получают возможность, обратив эти изменения, получить аналог полнофункционального продукта. Проводимый анализ позволяет избежать подобных ситуаций.
Анализ предполагаемого протокола передачи ПО пользователю
. На данном этапе уточняется состав организационных мер, связанных с коммерческой реализацией программного продукта: сбор персональных данных о пользователе или сохранение его анонимности, розничная (или наложенным платежом) продажа продукта за наличные либо продажа через глобальную сеть с электронными расчётами, наличие скидок на новые версии для зарегистрированных пользователей либо скидки на «кумулятивное» обновление для пользователей, перешедших с конкурирующих программных продуктов. Все эти данные позволяют оценить реально необходимый уровень стойкости системы защиты: если продукт распространяется индивидуально, то несанкционированное распространение такого «именного» продукта приведёт к уличению соответствующего пользователя (соответственно, уровень технической защиты продукта может быть средним), при распространении ПО через сеть Интернет и анонимности пользователей такая вероятность минимальна (следовательно, СЗПО должна иметь максимальный уровень стойкости).
Анализ возможных и вероятных угроз безопасности ПО
. Этот этап представляет собой процедуру оценки и управления рисками, связанными с защитой программного продукта от несанкционированного использования и распространения []. Данная процедура включает: определение множества возможных угроз; выделение подмножества вероятных угроз; определение потенциального ущерба по каждой угрозе; выработка контрмер; разработку общей стратегии поведения в условиях риска. Среди угроз несанкционированного распространения продукта можно выделить: распространение похищенной у легального пользователя аутентичной информации (пароль, серийный код); подбор этой информации; преодоление системы технической защиты продукта; сетевую атаку на сервер глобальной сети с целью завладения дистрибутивом продукта; похищение дистрибутива у легального пользователя; превращение легального пользователя в злоумышленника; приобретение продукта злоумышленниками «в складчину»; и приобретение продукта по украденной или фальшивой кредитной карте.
Документирование и сопровождение СЗПО
. Завершающим этапом процесса разработки СЗПО является окончательное оформление документации (разработка которой должна вестись на всех перечисленных этапах проектирования и реализации системы защиты) на разработанную систему и переход к сопровождению этой системы. В рамках сопровождения необходимо выполнять работы по внесению усовершенствований в разработанную СЗПО, расширению её функциональности, повышению стойкости и т.п. В результате будет получена корректно спроектированная и реализованная система программно-технической защиты программного обеспечения с заданными параметрами.
По нашему мнению разработка систем защиты программного обеспечения по приведённой схеме (с её упрощением или усложнением в зависимости от конкретной ситуации) позволит получать качественные, надёжные и устойчивые к атакам программные продукты, которые вкупе с законодательными и организационными «антипиратскими» мерами смогут успешно противостоять попыткам несанкционированного использования и распространения.
Доработка спецификаций СЗПО либо приобретение сторонней разработки, удовлетворяющей спецификации
. В случае, если расчётные затраты на разработку СЗПО превышают сумму выигрыша от внедрения защиты, возможны два варианта. Первым вариантом является уточнение и оптимизация требований к СЗПО, в результате проведения которых стоимость системы защиты станет удовлетворительной. Другим вариантом может быть приобретение разработанной другими производителями системы защиты, удовлетворяющей спецификациям и требованиям по стоимости. Как правило, в недорогих программных продуктах используются приобретённые системы защиты (внешнего типа), в программных продуктах с высокой стоимостью часто применяются системы защиты собственной разработки или доработанные приобретённые системы защиты комплексного типа (электронный ключ).
Три последующих этапа (Разработка и оптимизация алгоритма СЗПО, Выбор языка программирования для реализации СЗПО, Программная реализация СЗПО и её тестирование) относятся к реализации системы защиты собственными силами производителя ПО. В целом, разработка программной системы защиты ПО практически не отличается от разработки произвольного программного продукта системного уровня, за исключением специфических требований по надёжности и устойчивости к статическому и динамическому анализу. Что же касается тестирования, то кроме свойственных обычным приложениям тестов, призванных выявить ошибки программирования, СЗПО должна подвергаться серии интенсивных тестов на устойчивость к атакам. Эти тесты основаны на так называемом «диверсионном подходе», который предполагает исследование системы защиты с позиций злоумышленника с использованием соответствующего инструментария [], с целью её преодоления []. Для подобного тестирования СЗПО применяют к тестовой программе (либо написанной самостоятельно, либо стандартной, например, «Блокнот Windows»).
Доработка СЗПО (повышение стойкости к атакам)
. Если уровень защиты не соответствует спецификациям, необходимо произвести доводку системы защиты с целью доведения её устойчивости к атакам до запланированного уровня. Примерами доработки СЗПО могут служить: шифрация текстовых сообщений системы защиты (по которым легко можно локализовать СЗПО), использование стойких криптоалгоритов для шифрования кода ПО, отказ от хранения эталонного пароля в теле программы, использование упаковки объектного кода, использование антиотладочных механизмов, затруднение дизассемблирования объектного кода и т.п. []. После доработки СЗПО должна быть вновь протестирована на предмет побочных эффектов.
Доработка СЗПО (устранение побочных эффектов)
. В случае выявления побочных эффектов, оказывающих значительное влияние на функциональность и потребительские свойства ПО, необходимо выполнить доработку системы защиты, с целью ликвидировать или минимизировать указанные побочные эффекты. Примером негативного влияния СЗПО на качество программного продукта может служить снижение надёжности (повышение вероятности сбоя), повышение системных требований, конфликты с другими (прикладными или системными) программами, замедление работы ПО, необходимость особой настройки системы защиты и т.п. После доработки СЗПО тестирование на побочные эффекты повторяется.
Литература:
Защита программного обеспечения / Под ред. Д. Гроувера: Пер с англ. - М.: Мир, 1992. Семьянов П.В., Зегжда Д.П. Анализ средств противодействия исследованию программного обеспечения и методы их преодоления. // КомпьютерПресс. - 1993. №11. - Режим доступа к электрон. дан.:
http://www.password-crackers.com/publications/research.txt. Расторгуев С.П., Дмитриевский Н.Н. Искусство защиты и раздевания программ. - М.: Совмаркет, 1991. - 94 с. Середа С.А. Анализ средств преодоления систем защиты программного обеспечения. // ИНФОРМОСТ: Радиоэлектроника и Телекоммуникации. - 2002. №4(22). С. 11-16. - Режим доступа к электрон. дан.: . Середа С.А. Оценка эффективности систем защиты программного обеспечения. // КомпьюЛог. - 2000. №2. - Режим доступа к электрон. дан.: . Середа С.А. Управление жизненным циклом программных продуктов как фактор сокращения теневого рынка программного обеспечения: Тез. межд. конф. BiT+ "INFORMATION TECHNOLOGIES - 2003", Кишинёв. 2003. - Режим доступа к электрон. дан.: . Середа С.А. Экономический анализ поведения участников рынка программного обеспечения // ИНФОРМОСТ: Радиоэлектроника и Телекоммуникации. - 2002. №6(24). С. 4-9. - Режим доступа к электрон. дан.: . Середа С.А. Этапы преодоления систем защиты программного обеспечения. // ИНФОРМОСТ: Радиоэлектроника и Телекоммуникации. - 2003. №6(30). С. 26-30. - Режим доступа к электрон. дан.: . Bjones R., Hoeben S. Vulnerabilities in pure software security systems // Utimaco Software AG, 2000. - Режим доступа к электрон. дан.:
http://www.utimaco.com/eng/content_pdf/whitepaper_vulnerabilities.pdf. Devanbu P.T., Stubblebine S. Software Engineering for Security: a Roadmap // ICSE 2000. - Режим доступа к электрон. дан.:
http://www.cs.ucl.ac.uk/staff/A.Finkelstein/fose/finaldevanbu.pdf.
Авторские Права © 2004 Сергей А. Середа, © 2004 Движение ПОтребитель. Все права защищены.
За дополнительной информацией обращайтесь на consumer.cjb.net
Определение соответствующего требованиям уровня защиты
. Требования к уровню защиты можно оценивать двояко: либо определять значения частных критериев устойчивости защиты к атакам и их весовые коэффициенты, чтобы рассчитать комплексный критерий устойчивости []; либо определять временной интервал, в течение которого СЗПО гарантированно будет препятствовать теневому распространению защищаемого продукта []. Эти два вида оценки уровня защиты сильно взаимосвязаны, в то же время, более наглядным, а также более удобным для сопоставления с запланированным уровнем потерь от является второй. Обладая данными о динамике продаж во времени, нетрудно рассчитать необходимый временной интервал живучести СЗПО, который позволит сократить потери до запланированного уровня.
Определение стратегии защиты программного продукта (меры и средства)
. На основе полученных на предыдущих этапах аналитических данных необходимо определить оптимальное для данной ситуации сочетание мер и средств защиты программного продукта. В рамках законодательных мер можно говорить лишь о механизмах повышения раскрываемости нарушений прав производителя продукта, организационные меры определяются оговоренным ранее протоколом передачи продукта пользователю. В рамках же технических мер можно говорить не только о как таковой СЗПО, но и средствах отслеживания фактов появления нелицензионных версий продукта в глобальной сети, технических средствах выявления злоумышленников и т.п. Таким образом, данный этап определяет роль и место СЗПО в комплексе мер по защите продукта.
Первичное тестирование программного продукта
. На данном этапе определяются наиболее важные потребительские характеристики программного продукта, набор его важнейших функций, подлежащие тестированию. Результаты тестов являются эталоном, с которым впоследствии будут сравниваться результаты тестов защищённого программного продукта. Разумеется, первичным это тестирование является для процесса разработки системы защиты ПО. Определённая часть тестов должна проводиться в рамках процесса разработки самого программного продукта. Таким образом, значительная часть этого этапа должна быть уже выполнена ранее.
Следующие три этапа (Оценка общих планируемых затрат на разработку и внедрение СЗПО, Оценка планируемого снижения потерь от «пиратства» и Принятие решения о целесообразности применения проектируемой СЗПО) сильно связаны друг с другом и преследуют цель - оценить реальные затраты на разработку системы защиты и сравнить их с дополнительным доходом, который будет получен в результате её применения. То есть, указанные этапы включают оценку ожидаемой экономической эффективности разрабатываемой СЗПО и принятие решения о применимости системы с найденной расчётной эффективностью. Оценка затрат на разработку СЗПО выполняется по существующим методикам расчёта стоимости разработки системного ПО. Сумма дополнительного дохода от снижения уровня «пиратства» рассчитывается на основе данных о разнице между текущим и планируемым процентом потерь. Решение же о целесообразности применения спроектированной СЗПО принимается исходя из общепринятого в экономике предположения о рациональном поведении экономических агентов, т.е. применение системы принимается целесообразным, если затраты на СЗПО не превышают выигрыша от её применения.
Применение СЗПО к продукту и проверка влияния защиты на показатели функциональности защищаемого ПО
. На этом этапе выполняются проверки на побочные эффекты применения системы защиты к реальному защищаемому продукту. В данном случае должны быть повторены все тесты, выполненные на этапе первичного тестирования программного продукта. Затем, результаты повторных тестов должны сравниваться с результатами первичных тестов с анализом выявленных расхождений. В идеальном случае расхождений быть не должно. При наличии подобных расхождений необходимо провести оценку их влияния на потребительские свойства программного продукта. Анализ побочных эффектов системы защиты очень важен, так как в результате его проведения оценивается влияние защиты на конкурентоспособность продукта на рынке.
Процедура разработки систем программно-технической защиты программного обеспечения
,
Впервые опубликовано в сборнике
Инновации в процессе обучения: Сборник научных трудов Академического Совета МЭСИ. - М. 2004. - 212 с. С. 160-173.
В статье описывается краткая история проблемы теневого оборота программных продуктов, а также приводится обобщённая процедура проектирования и разработки систем программно-технической защиты программного обеспечения. Предложенная процедура является реализацией технологического подхода к разработке систем защиты, позволяющей спроектировать и программно реализовать систему защиты с заранее заданными характеристиками и минимальными побочными эффектами.
Проблема несанкционированного использования и распространения программного обеспечения (ПО) стала объектом исследований ещё в конце 70-х годов XX столетия и не теряет своей актуальности до сих пор. Причиной этому послужило стремительное развитие рынка персональных ЭВМ и, в особенности, признание IBM-совместимых компьютеров стандартом de facto для пользователей ПЭВМ. Таким образом, была разрешена проблема аппаратной и программной совместимости в рамках парка персональных компьютеров, что стимулировало появление программных продуктов "широкого пользования", которые стали разрабатываться и распространяться в отрыве от конкретных систем автоматизированной обработки данных. Подобные продукты были, фактически, реализацией типовых программных решений в наиболее популярных областях автоматизации обработки данных (обработка текстов, создание расчётных таблиц, работа с базами данных, редактирование графических изображений, компьютерные игры; позднее появились системы трёхмерного моделирования и анимации, мультимедийные приложения, системы распознавания текста и речи и мн.др.). Таким образом, производители программного обеспечения получили возможность перейти от индивидуального проектирования систем обработки данных к типовому, что позволило существенно снизить расходы на разработку ПО, а также распределить расходы на его приобретение между значительным количеством пользователей.
С другой стороны, высокая распространённость микрокомпьютерных систем, персональное пользование программными средствами и фактическая неподконтрольность индивидуальных пользователей создали предпосылки (и техническую возможность) для интенсивного несанкционированного обмена программами между владельцами персональных компьютеров. Этому же способствовало и отсутствие устоявшихся моральных норм в отношении программных продуктов, несовершенство правовой базы, а также инерционное восприятие программного обеспечения как бесплатного компонента (включённого в стоимость) приобретённых аппаратных средств.
Экономические потери производителей программных продуктов, выражающиеся в виде упущенной выгоды и морального ущерба, обусловили необходимость разработки и применения мер, препятствующих теневому обороту программных продуктов. Указанные меры можно условно подразделить на законодательные
(лоббирование законов, регламентирующих ответственность за несанкционированное использование и распространение ПО), организационные (установление контроля над пользователями путём регистрации их персональных данных, персонального режима обновления версий продукта и т.п.) и технические
(использование программно-технических средств, препятствующих несанкционированному использованию и/или копированию программных продуктов).
В силу того, что лоббирование законов возможно лишь для крупных компаний или объединений производителей ПО, а организационные меры требуют значительных затрат на реорганизацию торговой инфраструктуры и могут привести к переходу части клиентов на продукты конкурентов, не применяющих таких мер, самыми популярными стали технические меры противодействия теневому обороту ПО. Таким образом, получили широкое распространение системы программной защиты ПО, основной целью которых было техническое противодействие несанкционированному использованию и распространению программных продуктов. Такое положение дел сохранилось, в целом, и до настоящего времени, не смотря на то, что производителями достаточно активно используются законодательные и организационные меры защиты своих программных продуктов.
По проблемам программно- технической защиты программного обеспечения от несанкционированного введения в хозяйственный оборот было опубликовано очень значительное число работ []. В то же время, в многочисленных публикациях описывается техника, приёмы, но не технология (методология) защиты программных продуктов. Автору до настоящего времени не удалось найти публикации, которые были бы посвящены описанию обобщённой процедуры проектирования и реализации систем защиты программного обеспечения (СЗПО), как это делается, например, в области разработки программного обеспечения или проектирования подсистем защиты информации в системах обработки данных. По нашему мнению, отсутствие подобного описания в значительной мере затрудняет разработку СЗПО отдельными производителями, не имеющими соответствующего опыта, ведёт к многократному дублированию проводимых НИОКР, а также может быть причиной низкой стойкости разрабатываемых систем защиты.
Настоящий материал призван ликвидировать существующее «белое пятно» в исследованиях, посвящённых программно-технической защите программных продуктов.
По нашему мнению, процесс проектирования и разработки СЗПО можно логически разбить на следующие этапы:
Выявление целей и задач, стоящих перед производителем ПО.
Согласование допустимого процента потерь от "пиратства".
Определение соответствующего требованиям уровня защиты.
Выявление функциональной направленности защищаемого продукта.
Анализ предполагаемого протокола передачи ПО пользователю.
Анализ возможных и вероятных угроз безопасности ПО.
Определение стратегии защиты программного продукта (меры и средства).
Анализ исходных текстов продукта.
Выбор оптимального типа СЗПО (внешняя, встраиваемая, комбинированная).
Выбор оптимального вида СЗПО (парольная, шифрующая, с электронным ключом, и т.п.).
Выработка рекомендаций по модификации исходных кодов для соответствия требованиям безопасности.
Первичное тестирование программного продукта.
Оценка общих планируемых затрат на разработку и внедрение СЗПО с учётом влияния защиты на потребительские свойства ПО.
Оценка планируемого снижения потерь от "пиратства".
Принятие решения о целесообразности применения проектируемой СЗПО.
Доработка спецификаций СЗПО с возвратом к п.15 либо приобретение сторонней разработки, удовлетворяющей спецификации, с переходом к п.20.
Разработка и оптимизация алгоритма СЗПО.
Выбор (с обоснованием) языка программирования для реализации СЗПО.
Программная реализация СЗПО и её тестирование.
Применение СЗПО к продукту и проверка влияния защиты на показатели функциональности защищаемого ПО.
Доработка СЗПО с возвратом к п.20.
Тестирование фактического уровня защиты, обеспечиваемого СЗПО.
Доработка СЗПО с возвратом к п.20.
Документирование и сопровождение СЗПО.
Опишем указанные этапы более подробно.
Согласование допустимого процента потерь от «пиратства»
. Данный этап, вкупе с первым, позволяет определить основное направление работы по созданию системы защиты. Как правило, фирма-производитель ПО обладает данными о теневом распространении своих продуктов. Кроме того, производители регулярно проводят маркетинговые исследования, дающие информацию о плановом объёме продаж продукта. Сведения о теневом распространении продукта, а также о разнице между планировавшимся и реальным объёмами продаж позволяют достаточно точно оценивать фактический процент потерь от «пиратства». На указанном же этапе определяется процент потерь, с которым производитель готов смириться (это может быть и 0%) [].
Тестирование фактического уровня защиты, обеспечиваемого СЗПО
. На данном этапе проводится тестирование фактического уровня защиты конкретного программного продукта. Фактически, здесь повторяются тесты, основанные на «диверсионном подходе», которые проводились для тестового защищаемого приложения. Результаты проведённых на этом этапе тестов определяют фактическую стойкость созданной СЗПО (применительно к данному продукту). На их основе можно оценить требуемую квалификацию злоумышленника и инструментарий, требуемые для преодоления системы защиты. Соответственно, у разработчиков появляется возможность оценить затраты времени и средств, которые злоумышленник должен будет понести, преодолевая защиту. Если по итогам тестов полученный уровень стойкости защиты соответствует спецификациям, разработку СЗПО можно считать завершённой.
Выбор оптимального типа СЗПО
. Системы внешнего типа наиболее удобны для производителя ПО, так как легко можно защитить уже полностью готовый и оттестированный продукт. С другой стороны стойкость этих систем достаточно низка (в зависимости от принципа действия СЗПО), так как для обхода защиты достаточно определить точку завершения работы "конверта" защиты и передачи управления защищенной программе. Встраиваемые системы менее удобны для производителя ПО, так как возникает необходимость обучать персонал работе с программным интерфейсом системы защиты с вытекающими отсюда денежными и временными затратами, кроме того, усложняется процесс тестирования ПО и снижается его надежность. Но такие системы являются более стойкими к атакам, потому что здесь исчезает четкая граница между системой защиты и как таковым продуктом. Комбинированные же системы содержат элементы обоих типов [].
Выбор оптимального вида СЗПО
. На данном этапе производится выбор конкретного вида системы защиты. Иными словами, разработчики выбирают: устанавливать систему защиты от копирования («привязка» к ПК пользователя, к дистрибутивному носителю, физической дорожке жёсткого диска пользователя и т.п.) или систему защиты от использования (запрос пароля/серийного кода, ключевого файла, ключевого диска, электронного ключа). Например, львиная доля компьютерных игр использует «привязку» к дистрибутивному носителю (оптический диск), популярные отечественные программы ведения бухгалтерского и финансового учёта, ПО для разработки смет, архитектурного и инженерного проектирования используют защиту с электронным ключом, офисные пакеты используют защиты серийным кодом. Как правило, выбор зависит от большого числа факторов, определённых на более ранних этапах процесса разработки СЗПО. Многое, также, зависит и от соотношения стоимости копии программного продукта и стоимости копии системы его защиты.
Выявление целей и задач, стоящих перед производителем ПО
. На этом этапе необходимо определить начальные условия, исходя из которых будет разрабатываться система защиты ПО. Среди возможных целей, преследуемых производителем ПО, могут быть: максимизация прибыли от продаж программного продукта, минимизация потерь от «пиратства», вытеснение конкурирующих продуктов с сегмента рынка, выход на новый сегмент рынка и др. Задачами же могут являться: защита единичного продукта, защита серии продуктов, создание системы защиты, которую в дальнейшем можно было бы предложить как самостоятельный продукт и др. Информация о целях и задачах определяет весь дальнейший процесс разработки СЗПО.
Выявление функциональной направленности защищаемого продукта
. Данная информация позволяет оценивать нетехнические факторы, связанные с возможностью теневого распространения защищаемого программного продукта. К таким факторам можно отнести: распространённость и популярность продукта, условия использования, вероятность превращения пользователя в злоумышленника, вероятность уличения недобросовестных пользователей, роль документации и поддержки при использовании продукта. В частности, широко распространённый и популярный продукт вызывает у злоумышленников намного больший интерес, нежели продукт, используемый ограниченной группой пользователей, кроме того, для менее популярных продуктов снижается вероятность быстрого попадания продукта в руки злоумышленников; нелегальное использование программного продукта юридическим лицом гораздо легче выявить, чем подобное использование лицом физическим и т.п. Функциональная же направленность продукта во многом определяет озвученные нетехнические факторы. Например, программная система ведения бухгалтерского учёта находится в значительной зависимости от документации и сопровождения, менее популярна, чем текстовые реакторы и табличные процессоры, в то же время, подобные системы относятся к распространённым, наиболее вероятный пользователь - юридическое лицо, место установки - компьютер в офисе и т.д.
Выработка рекомендаций по модификации исходных кодов для соответствия требованиям безопасности
. Принятые ранее решения по типу и виду разрабатываемой СЗПО дают возможность формирования конкретных рекомендаций по видоизменению исходного кода продукта (без изменения функциональности) в соответствии с требованиями системы защиты. При этом изменению могут подлежать не только конструкции языка программирования, но и параметры компиляции исходных текстов. Например, статическое подключение библиотечных модулей вместо динамического или наоборот. Как правило, подобные изменения в исходном коде, кроме касающихся непосредственного размещения элементов системы защиты, связаны с затруднением анализа общей логики работы продукта и маскировкой расположения и проявлений СЗПО [].
Аннотация.
В статье рассматривается метод защиты программного обеспечения от изучения с помощью переноса защищаемого кода в виртуальную среду исполнения. Проводится анализ эффективности, а так же недостатков метода. Предлагается вариант реализации, позволяющий снизить себестоимость разработки.
Методы защиты ПО от изучения
Рассмотрим, какие методы существуют для защиты ПО от изучения:
Запутывание - искусственное усложнение кода, с целью затруднить его читабельность и отладку (перемешивание кода, внедрение ложных процедур, передача лишних параметров в процедуры и т.п.) Мутация - при каждом запуске создаются таблицы соответствия операций, сами операции заменяются на синонимы Компрессия, шифрование - изначально программа упаковывается / шифруется, и производит обратный процесс по мере выполнения Симуляция процессоров - создается виртуальный процессор; защищаемая программа компилируется под него, и выполняется на целевой машине с помощью симулятора
Существуют и другие методы, а так же их комбинации и разновидности, однако, нетрудно заметить, что все они основаны на одной простой идее: избыточности. В самом деле, что такое запутывание, как не избыточное кодирование программы? Лишние переходы, лишние параметры, лишние инструкции - ключевое слово метода "лишние". То же касается любого из перечисленных методов, и, вероятно, было бы естественным объединить все эти методы в одну группу "Методов избыточного кодирования". Чем же так хороша избыточность, ведь интуитивно понятно, что она увеличивает размер программы и снижает скорость ее работы? Дело в том, что во всех этих разновидностях защиты используется понимание "человеческого фактора" - человеку тем сложнее понять логику какого-либо процесса, чем больше ресурсов этот процесс использует. Например, функциональность одной простой инструкции загрузки константы на регистр может быть "размазана" на десятки, а то и сотни инструкций, и проследить связь всех используемых ресурсов (регистров, памяти и др.) в этой последовательности человеку довольно сложно. Метод шифрования с этой точки зрения не является чем-то особенным - так же, как и в других методах, для выполнения простой инструкции (или группы) требуется избыточная последовательность команд - в данном случае это операции расшифровки, плюс операции расшифрованного кода.
Однако то, что автоматически "запутано" или усложнено, может быть так же автоматически приведено в первоначальное состояние - разработчики механизмов запутывания обычно паралельно разрабатывают и "распутыватели", а методы мутации и шифрования и вовсе подразумевают содержание обратного механизма в защищенном коде. Особняком в этой группе методов стоит лишь метод симуляции виртуального процессора, который, во-первых, приводит к высокой и неснижаемой степени запутанности результирующего кода, а, во вторых (при определенном подходе к реализации), защищенный код не содержит в явном виде методов восстановления оригинального кода. Рассмотрим этот метод подробнее.
Реализация метода
Одним из недостатков метода является высокая стоимость его реализации, однако она может быть заметно снижена. В основе системы защиты, реализующей данный метод, мог бы лежать компилятор с языка высокого уровня. Необходимо машинно-зависимая фаза в любом компиляторе всего одна - кодогенерация, от зависимостей в других фазах, как правило, можно избавиться.
Если же компилятор изначально разрабатывается как мультиплатформенный, в нем, как правило, максимально упрощен процесс перенастройки на другую целевую платформу. Например, это может быть достигнуто автоматической генерацией кодогенератора по специальному описанию целевой машины. В этом случае разработчикам для смены платформы достаточно лишь изменить это описание. Но даже если собственного компилятора нет, можно воспользоваться свободнораспространяемыми с открытым кодом, например, GCC.
А чтобы максимально упростить для пользователя работу с описываемой системой защиты, ее можно снабдить механизмами встраивания в популярные среды разработки, такие как MSVC. В этом случае схема работы такого комплекса могла бы выглядеть так, как изображено на .
Соответственно, функционирование защищенного таким способом образом продукта происходило бы по схеме на Рис. 2.

Схема работы защищенного программного
Схема работы защищенного программного продукта
Специфика использования компилятора налагает ряд особых требований к виртуальному процессору, тем не менее все они могут быть легко реализованы. Требований немного - нужно лишь обеспечить возможность доступа к внешней, относительно виртуальной машины, памяти, а так же возможность вызова внешних функций - это необходимо для взаимодействия защищенного и незащищенного кода. В остальном архитектура виртуального процессора может быть совершенно произвольной, и чем запутаннее и оригинальней она будет, тем более высокий уровень защиты будет достигнут.
Сам компилятор, кроме изменения кодогенерационной фазы, нужно доработать для приобретения им возможностей:
Различать обращения к внутренней и внешней памяти относительно виртуального процессора (в том числе и вызовы функций) Создавать для каждой защищаемой функции так называемую оболочку, выполняющуюся на реальном процессоре, с вызовом защищенной функции через симулятор
Последнюю возможность следует описать подробнее. Как было отражено в схеме на Рис. 2, функционал защищенных функций будет реализован через вызов симулятора, с указанием, какую из защищенных функций нужно интерпритировать. Однако, до этого, необходимо выполнить специальный код, подготавливающий для защищенной функции параметры - "переместить" их с реальных регистров и памяти на виртуальные, способом, соответствующим архитектуре виртуального процессора. Всем этим будут заниматься специальные функции, сгенерированные нашим компилятором - "оболочки". Оболочки, в свою очередь, будут использовать специальные функции симулятора для доступа к виртуальным регистрам и памяти. Характерно, что наш компилятор будет генерировать оболочки на языке высокого уровня, которые, в свою очередь, будут компилироваться стандартным компилятором, использующимся пользователем для сборки незащищенной части своего проекта. Итак, вызов защищенной функции из незащищенного модуля может выглядеть так, как изображено на .
Конечно, конкретная реализация метода виртуального процессора может быть несколько отличной от описываемой, как и схема работы защищенного им продукта. Тем не менее, описанный вариант вполне жизнеспособен, и, кроме того, относительно прост.
Сердце защищенного продукта - симулятор. Он будет включаться в любую сборку защищенного продукта. Однако не будем подробно рассматривать его реализацию, т.к. специальных требований к нему практически не предъявляется - он должен лишь симулировать архитектуру нашего виртуального процессора, включая операции доступа к внешней памяти. Стоит, однако, отметить, что с учетом специфики его применения, необходимо максимально автоматизировать процесс перенастройки симулятора на новые виртуальные архитектуры.
Недостатки же метода - следствие его достоинств:
Скорость работы перенесенного в виртуальную среду кода в разы (ориентировочно в 10-50, в зависимости от архитектуры виртуального процессора и симулятора) ниже, чем кода оригинального Объем защищенной программы, как правило, будет несколько выше, чем незащищенной
Впрочем, последний недостаток несущественен, т.к. размер увеличится незначительно, а в некоторых случаях может даже снижаться. Первый же недостаток принципиален, и налагает некоторые очевидные ограничения на использование метода.
Виртуальный процессор в защите ПО
Суть метода такова: некоторые функции, модули, или программа целиком, компилируются под некий виртуальный процессор, с неизвестной потенциальному взломщику системой команд и архитектурой. Выполнение обеспечивает встраиваемый в результирующий код симулятор. Таким образом, задача реинжиниринга защищенных фрагментов сводится к изучению архитектуры симулятора, симулируемого им процессора, созданию дизассемблера для последнего, и, наконец, анализу дизассемблированого кода. Задача эта нетривиальна даже для специалиста, имеющего хорошие знания и опыт в работе с архитектурой целевой машины. Взломщик же не имеет доступа ни к описанию архитектуры виртуального процессора, ни к информации по организации используемого симулятора. Стоимость взлома существенно возрастает.
Почему же, учитывая высокую теоретическую эффективность, данный метод до сих пор не используется повсеместно? Видимо по двум основным причинам. Во-первых, метод имеет особенности, что сужает области его потенциального применения - об этом будет сказано ниже. Во-вторых, и, возможно, это более серьезная причина, сложность (а следовательно и стоимость) реализации метода весьма высока. Если же учесть принципиальную возможность утечки информации о только что созданной системе, которая моментально приведет к ее неэффективности и обесцениванию, становится понятно, почему фирмы-производители защитного ПО не спешат реализовывать этот метод. Стоит, однако, отметить, что с теми или иными вариациями и ограничениями данный метод все же реализован в таких новейших продуктах как StarForce3, NeoGuard, VMProtect и др. Видимо таких продуктов будет становиться все больше и больше, а существующие будут развиваться, т.к. появляющиеся реализации подтверждают высокую эффективность метода, хоть и имеют пока слабые стороны.
Как известно, идеального способа защиты
Как известно, идеального способа защиты программного обеспечения (ПО) не существует, в связи с этим, разработчики защитных систем не стремятся лишить потенциального взломщика самой возможности нейтрализации защиты, но стараются максимально усложнить этот процесс.
Защита может решать одну или комплекс из множества задач, таких как защита от копирования, нелегального использования, модификации и др., но какая бы конечная цель ни стояла перед таким продуктом, разработчикам каждого из них прежде всего необходимо решить общую для всех проблему - качественной защиты от изучения. Какие бы ни применялись алгоритмы защиты ПО, их стойкость к обратной инженерии определяет стойкость всей системы защиты в целом.
Сегодня на рынке существует большое количество коммерческих защит, однако многие из них, в т.ч. до сих пор популярные, давно взломаны. Зачастую их подводит именно слабая защищенность от изучения. После анализа взломщиком алгоритмов работы защиты, серийные ключи генерируются, аппаратные - успешно эмулируются. Ситуацию могла бы исправить разработка эффективного метода защиты ПО от изучения, применяя который к алгоритмам других защит, возможно было бы качественно поднять их уровень.
Рассмотренный метод защиты ПО весьма
Рассмотренный метод защиты ПО весьма эффективен, учитывая то, что затраты на его разработку можно существенно сократить. Однако, особенности метода не позволяют рекомендовать его для защиты программ полностью. Так, метод не может применяться для защиты функций, критичных ко времени выполнения, а так же функций, замедление работы которых может заметно снизить эффективность использования программы пользователем. Тем не менее, аккуратное применение данного метода позволяет добиться очень высокого уровня защиты от изучения. Всвязи с этим, основной областью его применения видится повышение стойкости к изучению отдельных алгоритмов других систем защиты ПО. Кроме того, метод применим для защиты нересурсоемких алгоритмов ноу-хау, а так же для сокрытия содержания в защищаемой программе некоторых специальных данных, например, сведений об авторстве.
Анализ на основе линейных зависимостей
Многие условия корректности операций в программе представляют собой линейные соотношения (равенства либо неравенства) между значениями числовых атрибутов объектов программы. Например, при обращении к массиву проверяется, лежит ли индекс, по которому происходит обращение, в пределах массива. В случае если и длина массива, и значение индекса в широких пределах произвольны, ответить на вопрос о возможности выхода за пределы массива при отсутствии информации о зависимости между индексом и длиной массива невозможно.
Подход, предлагаемый нами к использованию в рамках разрабатываемой системы обнаружения уязвимостей, состоит в поддержании системы линейных неравенств, выполняющихся для числовых атрибутов в данной точке программы.
При потоково-чувствительном анализе потока данных в каждой точке программы (контексте) хранится информация о большом количестве числовых атрибутов. Так как одной из задач разрабатываемой системы являлась возможность анализа программ промышленного масштаба, были применены различные методы, ограничивающие вычислительные издержки, возникающие при учете линейных зависимостей.
Если при анализе требуется определить соотношение между значениями атрибутов (проверить некоторое равенство или неравенство), то переносом всех атрибутов в одну часть соотношения задача сводится к определению множества возможных значений атрибута, равного полученному в этой части выражению. Например, при проверке выхода за пределы массива требуется проверить, меньше ли индекс в массиве x размера массива l, x<l, что эквивалентно z=x-l, z∈(-∞,-1].
Для каждого атрибута одновременно поддерживаются целочисленный интервал значений (интервальная оценка) и системы линейных уравнений и неравенств (система линейных связей). Преобразования для интервальных оценок производятся независимо от преобразований системы линейных связей. Для проверки условий корректности операций программы достаточно получать интервальную оценку значений линейных комбинаций атрибутов. Поэтому линейные связи можно рассматривать как дополнительную информацию, надстройку над анализом на основе интервальных оценок, позволяющую иногда уточнять интервальную оценку.
Граф линейных связей
Введем для дальнейшего рассмотрения ориентированный граф линейных связей (ГЛС). Вершинам этого графа сопоставлены атрибуты, ребро (u,v) присутствует в графе, когда в систему линейных связей атрибута u входит атрибут v.
Структура ГЛС существенно зависит от метода выделения системы линейных связей из многогранного множества, полученного в качестве результата преобразования. Этот вопрос будет раскрыт далее. За счет структуры ГЛС для выделения приемлемого многогранного множества, описывающего данный атрибут, достаточно собрать систему из линейных связей вершин ГЛС, встречающихся при обходе ГЛС в ширину, начиная с описываемого атрибута. Добавление линейных связей прекращается, как только одна из оценок сложности получаемого многогранного множества превышает соответствующее пороговое значение.
Для многогранного множества вводятся две оценки сложности: количество атрибутов и количество существенных ограничений неравенствами.
Предельное количество атрибутов влияет на степень вершин ГЛС. Чрезмерное повышение этого порога приводит к тому, что при обходе в ширину в ГЛС быстро собирается большое количество посторонних линейных связей (поднимая вторую оценку сложности), до того как в строящееся многогранное множество включается достаточное количество связей, важных для описываемого атрибута. Эксперименты на тестовом наборе программ показали, что оптимальным значением является порог порядка 15 атрибутов.
Количество существенных ограничений неравенствами определяет вычислительную сложность операций над многогранным множеством. Для тестового набора программ порог, приводящий к удвоению времени анализа программ при учете линейных связей по сравнению с анализом без учета линейных связей, составляет порядка 20 ограничений.
Будем далее называть операцию выделения многогранного множества из ГЛС для данного атрибута замыканием атрибута.
Использование информации о линейных
Несов В.С., Маликов О.Р., Труды Института системного программирования РАН
Литература
| [1] | H. Le Verge. A note on Chernikova's Algorithm. July 27, 1994. |
| [2] | P. Cousot and N. Halbwachs. Automatic discovery of linear restraints among variables of a program. In 5th ACM Symposium on Principles of Programming Languages , POPL'78 , Tucon (Arizona), January 1978. |
| [3] | N. Halbwacht, Y.E. Proy, and P. Roumanoff. Verification of real-time systems using linear relation analysis. Formal Methods in System Design , 11(2):157-185, 1997. |
| [4] | Бирюков С.И. Оптимизация. Элементы теории. Численные методы. МЗ-Пресс, 2003. |
Многогранное множество
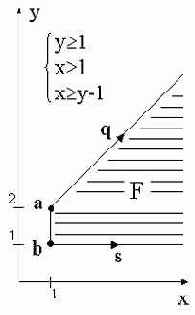
Многогранным называется множество, задаваемое системой линейных неравенств. Каждое многогранное множество может быть представлено двумя способами: в виде системы неравенств, либо в виде множества образующих вершин и лучей (геометрическое представление). В геометрическом представлении многогранное множество равно сумме выпуклого замыкания множества вершин и конического замыкания множества лучей. На рисунке {a,b} - множество вершин, {q,s} - множество лучей.
Наличие обоих представлений и возможность перехода между ними позволяет производить различные преобразования многогранных множеств при помощи простых алгоритмов. Например, пересечение многогранных множеств задается объединением систем неравенств. Выпуклая оболочка объединения многогранных множеств задается объединением соответствующих множеств геометрического представления.
Для перехода между представлениями многогранного множества используется алгоритм Черниковой с оптимизацией Ле Вержа (H. Le Verge) [].
Сложность различных операций над многогранными множествами не позволяет применять их к многогранному множеству, описываемому всей системой линейных связей контекста. Поэтому для применения операций, требующих представления в виде многогранного множества, необходимо выделять подсистему линейных связей.
и значения атрибутов при проведении
В приведен код примера и значения атрибутов при проведении итераций статического анализа. Для каждой строки кода для данной итерации приведены ограничения, справедливые на выходе из инструкций строки, либо, в случае ветвления, ограничения на входе и выходе из инструкции. Например, в приведенном примере контекст на входе в инструкции строки 4 получается в результате объединения контекстов на выходе из инструкций строк 3 и 6.
В примере имя атрибута s.len ссылается на атрибут длина строки s. Выписываются не все ограничения, а лишь важные для окончательных выводов.
Как видно, в результате анализа данного примера определяются оценки значений атрибутов, позволяющие исключить ошибки переполнения массивов. При анализе на основе интервальных оценок такие ошибки исключены не были бы.
Примеры устраненных ложных предупреждений
bftpd, mystring.c, строка 16: void cutto(char *str, int len) { memmove(str, str + len, strlen(str) - len + 1); }
При корректных вызовах функции переполнения буфера не возникает. Требуемое условие в данном случае str.size>str.len-len, где str.size и str.len - соответственно атрибуты массива str, отражающие его длину и длину хранящейся в нем строки.
popclient, socket.c, строка 112: int SockWrite(socket,buf,len) int socket; char *buf; int len; { int n; while (len) { n = write(socket, buf, len); if (n <= 0) return -1; len -= n; buf += n; } return 0; }
В данном случае при вызове функции всегда len<=buf.size, при изменении len и buf на одну и ту же величину соотношение не нарушается. Так как возвращаемое значение функции write n<=len, так же сохраняется условие len>=0 (уточняемое условием цикла до len>0). За счет выполнения этих соотношений вызов функции write происходит корректно.
Результаты
На тестовом наборе из 7 программ с открытым исходным кодом были получены следующие результаты. В таблице 2 указано количество истинных и ложных предупреждений, выдающихся системой обнаружения уязвимостей до и после использования учета линейных зависимостей между атрибутами.
и значения атрибутов при проведении
Код примера и значения атрибутов при проведении итераций статического анализа
Результаты тестирования
| bftpd | 54 | 20 | 34 | 7 |
| lhttpd | 22 | 5 | 17 | 0 |
| muh | 47 | 12 | 35 | 2 |
| pgp4pine | 45 | 16 | 29 | 3 |
| popclient | 34 | 7 | 27 | 12 |
| sharutils | 49 | 11 | 38 | 7 |
| troll-ftpd | 47 | 2 | 45 | 2 |
Одним из методов обнаружения потенциальных
Одним из методов обнаружения потенциальных уязвимостей в программе является статический потоково-чувствительный data-flow анализ. В ходе проведения такого анализа для каждой точки программы собирается информация о различных атрибутах объектов программы, которая затем проверяется на выполнение условий корректности операций с памятью и использования библиотечных функций в различных точках программы.
Серьезной проблемой такого метода обнаружения уязвимостей является большое количество ложных предупреждений. Часто ложные предупреждения вызваны недостаточной точностью определяемой информации об атрибуте - значение некоторой переменной (объекта программы).
Самым простым подходом определения информации о целочисленных значениях является анализ на основе интервальных оценок. Каждому целочисленному атрибуту объектов программы в данной точке программы сопоставляется числовой интервал значений, при этом зависимости между атрибутами не учитываются. Например, если атрибуту x сопоставляется интервал возможных значений [a,b], атрибуту y - интервал [c,d], то результату операции сумма z=x+y сопоставляется интервал [a+c,b+d]. Такая модель хорошо работает для несвязанных друг с другом атрибутов.
Выделение системы линейных связей из многогранного множества
После выполнения преобразования многогранного множества необходимо сохранить результат в атрибуте. Многогранное множество часто получается в результате замыкания атрибута и содержит слишком большое количество линейных связей. Так как при всех операциях каждый раз модифицируется только небольшое количество атрибутов, то, вообще говоря, изменяются только линейные связи, содержащие эти атрибуты. Поэтому из многогранного множества извлекаются только линейные связи, включающие в себя данные атрибуты.
Так как системы линейных связей хранятся отдельно для различных атрибутов, часть полученных линейных связей может оказаться следствием связей, получаемых из окружающих вершин ГЛС. Сохранение таких связей излишне, так как при замыкании линейные связи окружающих вершин и так будут учтены. Поэтому такие связи исключаются.
Аннотация. В статье даётся краткое
В настоящее время в комплексном программном обеспечении широко применяются программные приложения, разработанные сторонними производителями. В ряде случаев такие приложения предоставляются без исходного кода на языке высокого уровня, необходимого для их аудита с точки зрения информационной безопасности их использования. Несмотря на это, такие приложения обязательно должны быть исследованы для оценки рисков их использования. Ни бинарный код, ни ассемблерный листинг, полученный в результате дизассемблирования, не позволяют с приемлемыми трудозатратами оценить взаимосвязь элементов программы, а также идентифицировать в программе стандартные алгоритмические конструкции. Восстановление программы на языке высокого уровня дает возможность преодолеть указанные выше трудности. Программные приложения, представленные в виде исполняемых файлов или на языке ассемблера, сложны для анализа их специалистами в области информационной безопасности, криптографии и т.д. и должны быть предоставлены им для анализа на более высоком уровне представления. В качестве одного из инструментальных средств повышения уровня абстракции представления программы может использоваться декомпилятор.
Под декомпилятором мы будем понимать инструментальное средство, получающее на вход программу на языке ассемблера и выдающее на выход эквивалентную ей программу на некотором языке высокого уровня.
Задача декомпиляции была поставлена в 60-е годы XX века сразу же, когда стали широко применяться компиляторы с языков высокого уровня, но не утратила своей актуальности и по сей день [2]. Эта задача не решена в полной мере из-за наличия ряда трудностей принципиального характера. В частности, при компиляции программы из языка высокого уровня в язык ассемблера характерно отображение «многие к одному» концепций языка высокого уровня в концепции языка ассемблера, и, как следствие, однозначное восстановление программы на языке высокого уровня становится зачастую невозможным.
В силу указанных выше причин полностью автоматический декомпилятор реализовать принципиально невозможно.
Поэтому системы декомпиляции программ должны работать во взаимодействии с аналитиком, который (зачастую методом проб и ошибок) управляет процессом декомпиляции. В ходе декомпиляции программы решаются следующие задачи: выделение структурных единиц программы, в частности, подпрограмм в однородном ассемблерном листинге, выявление параметров подпрограмм и возвращаемых ими значений, структурный анализ, то есть восстановление операторов циклов, ветвлений и т. п., восстановление типов данных, как базовых, так и производных и другие. Поскольку все эти задачи достаточно трудоемки и алгоритмически неразрешимы, на сегодняшний день нет известных декомпиляторов, восстанавливающих программы в какой-либо язык высокого уровня, которые качественно справлялись бы со всеми перечисленными выше задачами. Для решения задач посредством использования декомпиляторов требуется хорошо представлять возможности используемого инструмента, и для достижения наилучшего результата, возможно, потребуется использовать набор декомпиляторов в некоторой композиции. В данной работе предлагается обзор наиболее известных декомпиляторов в язык Си из бинарных файлов, рассматривается набор тестов, на основе которого можно сделать сравнительный анализ работоспособности декомпиляторов, и выполняется этот анализ.
В данной работе в качестве процессорной архитектуры, с которой ведётся декомпиляция, выбрана архитектура Intel i386, наиболее распространённая в настоящее время. В листингах фрагментов программ на языке ассемблера используется синтаксис AT&T [3].
Предлагаемая работа имеет следующую структуру. Поскольку и в литературе, и на практике зачастую смешиваются понятия дизассемблирования программы и декомпиляции программы, уместно рассмотреть различия этих задач. Этому посвящен второй раздел статьи. В третьем разделе статьи дается описание основных подзадач декомпиляции с описанием возникающих трудностей при их решении. В четвертом разделе приводится обзор языка Си с точки зрения обратной инженерии. Пятый раздел посвящен описанию существующих декомпиляторов для языка Си.В пятом разделе представлены результаты сравнительного тестирования декомпиляторов на разработанном наборе тестовых примеров. В заключении сформулированы выводы работы и направления дальнейших исследований.
Boomerang
Декомпилятор Boomerang [5] является программным обеспечением с открытым исходным кодом (open source). Разработка этого декомпилятора активно началась в 2002 году, но сейчас проект развивается достаточно вяло. Изначально задачей проекта была разработка такого декомпилятора, который восстанавливает исходный код из исполняемых файлов, вне зависимости от того, с использованием какого компилятора и с какими опциями исполняемый файл был получен. Для этого в качестве внутреннего представления было решено использовать представление программы со статическими одиночными присваиваниями (SSA). Однако, несмотря на поставленную цель, в результате декомпилятор не сильно адаптирован под различные компиляторы и чувствителен к применению различных опций, в частности, опций оптимизации. Еще одной особенностью, затрудняющей использование декомпилятора Boomerang, является то, что в нем не поддерживается распознавание стандартных функций библиотеки Си.
DCC
Проект по разработке этого декомпилятора [8] был открыт в 1991 году и закрыт в 1994 году с получением главным разработчиком степени PhD. В качестве входных данных декомпилятор DCC принимает 16-битные исполняемые файлы в формате DOS EXE. Алгоритмы декомпиляции, реализованные в этом декомпиляторе, основаны на теории графов (анализ потока данных и потока управления). Для распознавания библиотечных функций используется сигнатурный поиск, для которого была разработана библиотека сигнатур. Однако надо заметить, что, несмотря на это, декомпилятор плохо справляется с выявлением функций стандартной библиотеки.
Декомпиляция и дизассемблирование
Рассмотрим независимо друг от друга задачу дизассемблирования и задачу декомпиляции программ. Под декомпиляцией понимается построение программы на языке высокого уровня, эквивалентной исходной программе на языке низкого уровня (языке ассемблера). Под дизассемблированием понимается построение программы на языке ассемблера, эквивалентной исходной программе в машинном коде. Программа в машинном коде представляется либо в виде исполняемого модуля в стандартном для целевой операционной системы формате (например, для Win32 в формате PE [16], а для Linux – в формате ELF [15]), либо в виде дампа содержимого памяти, либо в виде трассы исполнения программы.
Традиционно декомпиляция рассматривается в более широком смысле, а именно, как построение программы на языке высокого уровня по программе в машинном коде. Очевидно, что в такой постановке задача декомпиляции поглощает задачу дизассемблирования. Такое «широкое» понимание декомпиляции излишне, поскольку дизассемблирование и декомпиляция решают разные по сути задачи, хотя и используют схожие методы (в частности, построение графа потока управления и исполняемого покрытия программы). Так, при дизассемблировании выполняется трансляция исполняемого файла, представляемого в виде набора машинных команд, в программу на языке ассемблера. При декомпиляции программа с представления низкого уровня транслируется в представление высокого уровня. Дальнейшим этапом повышения уровня абстракции программы может быть рефакторинг, посредством которого из программы на языке Си можно, например, получить программу на языке Си++.
Рассмотрим разбиение задач декомпиляции и дизассемблирования на подзадачи. Так, при дизассемблировании требуется решать следующие основные задачи:
Разделение кода и данных. Для каждой ячейки программы (или ячейки памяти дампа) должно быть установлено, хранит ли ячейка исполняемые инструкции или данные. Задача эта сама по себе алгоритмически неразрешима [5] и не всегда может быть решена однозначно (например, в случае самомодифицирующегося кода, динамически подгружаемого кода и т. п.).
Замена абсолютных адресов на символические.
При декомпиляции должны быть решены следующие основные задачи:
Выделение функций в потоке инструкций.
Выявление параметров и возвращаемых значений.
Восстановление структурных конструкций языка высокого уровня.
Замена всех обращений к памяти на конструкции языка высокого уровня (в частности, сюда входит идентификация обращения к локальным переменным и параметрам и их замена на символические имена, идентификация обращений к массивам и их замена на операции с массивами и т. д.). Восстановление типов объектов языка высокого уровня, выявленных на предыдущем шаге.
В дальнейшем мы будем рассматривать задачу декомпиляции в узкой постановке, то есть как задачу трансляции программы, представленной на языке низкого уровня, в частности, на языке ассемблера, в программу на языке высокого уровня, в частности, на Си.
Декомпиляторы в язык Си
В данном разделе дается краткое описание существующих на сегодняшний момент декомпилятров в язык Си. Это – декомпиляторы Boomerang [5], DCC [8], REC [14] и плагин Hex-Rays [10] к дизассемблеру IdaPro [11]. Все рассматриваемые декомпиляторы, кроме плагина Hex-Rays, на вход принимают исполняемый файл, и выдают программу на языке Си. В том случае, когда декомпилятор оказывается не в состоянии восстановить некоторый фрагмент исходной программы на языке Си, этот фрагмент сохраняется в виде ассемблерной вставки. Надо заметить, что даже небольшие исходные программы после декомпиляции зачастую содержат очень много ассемблерных вставок, что практически сводит на нет эффект от декомпиляции.
В отличие от этого, плагин Hex-Rays принимает на вход программу, являющуюся результатом работы дизассемблера Ida Pro, то есть схему программы на ассемблеро-подобном языке программирования. В качестве результата Hex-Rays выдает восстановленную программу в виде схемы на Си-подобном языке программирования. Тем не менее, для простоты мы в дальнейшем объединим процесс дизассемблирования с использованием Ida Pro и последующей декомпиляции.
Языки высокого уровня с точки зрения обратной инженерии
Языки высокого уровня позволяют повысить уровень абстракции представления реализуемого алгоритма, избавляя программиста от необходимости заботиться о низкоуровневых деталях. Эти языки соперничают друг с другом по простоте использования и гибкости, а разработчики компиляторов соперничают по производительности сгенерированного ими кода. Следовательно, имеется большое количество разнообразных языков высокого уровня, и для каждого из них существует множество компиляторов.
При восстановлении программ по программе на языке низкого уровня, имея широкое представление о языке высокого уровня, нужно с достаточной точностью восстановить то, что было написано на языке высокого уровня в исходном тексте программы. Точность и трудозатраты восстановления программы сильно зависят от языка высокого уровня, на котором была написана исходная программа.
Язык Си формально считается языком высокого уровня, однако в нем присутствует много черт языка низкого уровня. В частности, в языке Си поддерживается прямой доступ к памяти и работа с указателями. При обращении к элементам массива не контролируется выход за его пределы, то есть возможен доступ к областям памяти, не имеющим никакого отношения к массиву. С другой стороны, в языке Си поддерживаются такие высокоуровневые конструкции, как производные типы данных: массивы, структуры, объединения, а также условные операторы, циклы и т. д.
На практике особую значимость имеют декомпиляторы, транслирующие ассемблерный листинг в язык Си. Во-первых, восстанавливать программы, написанные изначально на языке Си, удобно, потому что это процедурный язык и у него много низкоуровневых особенностей. Во-вторых, язык Си широко применяется в промышленном программировании, и большое количество системных приложений написано именно на языке Си. С другой стороны, восстанавливать программу из ассемблера в объектно-ориентированный язык принципиально сложнее, да и к тому же программа, реализованная на основе процедурной парадигмы программирования, может быть переведена в объектно-ориентированную программу посредством рефакторинга ее кода. Следовательно, в данной работе ограничим множество рассматриваемых декомпиляторов теми, которые восстанавливают на языке Си программы, представленные либо на языке ассемблера, либо в виде исполняемых файлов.
О некоторых задачах обратной инженерии
, , Труды Института системного программирования РАН
Обзор основных подзадач декомпиляции
Рассмотрим основные задачи декомпиляции и подходы к их решению.
Структурный анализ
Одним из результатов предыдущих фаз анализа ассемблерного листинга программы является разбиение потока инструкций ассемблерного листинга на отдельные функции и выявление точек входа в функции и возврата из функций.
Инструкции ассемблерной программы в функции могут рассматриваться как представление нижнего уровня (Low-level intermediate representation) [12]. В частности, представление низкого уровня отличается от представления высокого уровня (программы на языке Си) отсутствием структурных управляющих конструкций (if, for и т. п.).
Для восстановления управляющих конструкций сначала строится граф потока управления программы. По графу потока управления строится дерево доминаторов, затем дуги графа потока управления классифицируются на «прямые», «обратные» и «косые».
На основании этой информации уже можно выполнять непосредственно структурный анализ, то есть восстановление высокоуровневых управляющих конструкций [6]. Поиском в глубину в графе выделяются шаблоны основных структурных конструкций, которые затем организуются в иерархическую структуру.
Восстановление типов
Задача автоматического восстановления типов данных на настоящее время – одна из задач в области декомпиляции, наименее проработанных с теоретической точки зрения. Ее можно условно разделить на подзадачу восстановления базовых типов данных языка, таких как char, unsigned long и т. п., и на подзадачу восстановления производных типов, таких как типы структур, массивов и указателей. В работе [13] рассматривается восстановление как базовых, так и производных типов при декомпиляции, однако этот подход имеет ряд существенных недостатков, и отсутствует его практическая реализация. В работе [4] описан подход к автоматическому восстановлению производных типов языка по исполняемому файлу. Такой подход используется для анализа на уязвимость программ в виде исполняемых файлов и поэтому не применим напрямую к задаче восстановления типов при декомпиляции.
На практике же все декомпиляторы, кроме Hex-Rays, вообще не восстанавливают даже базовые типы переменных, а в выражениях используют явное приведение типов, что делает восстановленные выражения сложными для понимания и модификации.
Выделение функций
Одной из основных структурных единиц программ на языке Си являются функции, которые могут принимать параметры и возвращать значения. Откомпилированная программа, однако, состоит из потока инструкций, функции в котором никак структурно не выделяются. Как правило, компиляторы генерируют код с одной точкой входа в функцию и одной точкой выхода из функции. При этом в начало кода, генерируемого для функции, помещается последовательность машинных инструкций, называемая прологом функции, а в конец кода – эпилог функции. И прологи, и эпилоги функций, как правило, стандартны для каждой архитектуры и лишь незначительно варьируются. Например, стандартный пролог и эпилог функции для архитектуры i386 показаны ниже:
Пролог: pushl %ebp movl %esp, %ebp
Эпилог: movl %ebp, %esp popl %ebp ret
Прологи и эпилоги функций могут быть легко выделены в потоке инструкций. Кроме того, при работе с трассами можно считать, что инструкции, на которые управление передается с помощью инструкции call, являются точками входа в функции, а инструкции ret завершают функции. Возникает соблазн считать инструкции, расположенные между прологом и эпилогом, или между точками входа и выходом, телом функции, однако в этом случае можно натолкнуться на ряд сложностей. Во-первых, при компиляции программы могут быть указаны опции, влияющие на форму пролога и эпилога функции. Например, опция компилятора GCC –fomit-frame-pointer подавляет использование регистра %ebp в качестве указателя на текущий стековый кадр, когда это возможно. В этом случае пролог и эпилог функции будут, как таковые, отсутствовать. Во-вторых, отдельные оптимизационные преобразования могут разрушать исходную структуру функций программы. Очевидным примером такого оптимизационного преобразования является встраивание тела функции в точку вызова. Встроенная функция не существует как отдельная структурная единица программы, и ее автоматическое выделение представляется затруднительным.
Существуют оптимизирующие преобразования, которые приводят к появлению в машинном коде конструкций, принципиально невозможных в языках высокого уровня.
Таким оптимизирующим преобразованием является, например, sibling call optimization. Если список параметров двух функций идентичен, и первая функция вызывает вторую с этими параметрами, то инструкция вызова подпрограммы call может быть преобразована в инструкцию безусловного перехода jmp в середину тела второй функции. Результатом такого рода «неструктурных» оптимизаций будет появление переходов из одной функции в другую, появление функций с несколькими точками входа или несколькими точками выхода. Другим источником «неструктурных» конструкций в машинной программе являются операторы обработки исключений в таких языках, как Си++.
Таким образом, хотя в типичном случае компилятор генерирует хорошо структурированный код, поддающийся разбиению на функции, достаточно легко может быть получен и «неструктурированный» код. Следует отметить, что в этом случае влияние программиста, пишущего программу на языке Си, на структуру генерируемого кода ограничено возможностями языка Си, не позволяющего бесконтрольной передачи управления между функциями и не поддерживающего механизм исключений. Поэтому можно предполагать, что если восстанавливается программа с языка ассемблера, полученная в резу-льтате компиляции программы на языке Си, то она не содержит «неструк-турных» особенностей, описанных выше, и может быть разбита на функции.
Выявление параметров и возвращаемых значений
В языках высокого уровня, в частности, Си поддерживается передача параметров в функции и возврат значений. В языке Си существует только передача параметров по значению, в других языках могут поддерживаться и другие механизмы. Заметим, что здесь мы рассматриваем только механизмы передачи параметров, отображаемые в генерируемый машинный код. Передача параметров по имени, передача параметров в шаблоны и другие механизмы периода компиляции программы здесь не рассматриваются.
Способы передачи параметров и возврата значений для каждой платформы специфицированы и являются составной частью так называемого ABI (application binary interface). Под платформой здесь понимается, как обычно, тип процессора и тип операционной системы, например, Win32/i386 или Linux/x86_64. Одной из задач ABI является обеспечение совместимости по вызовам приложений и библиотек, скомпилированных разными компиляторами одного языка или написанных на разных языках.
Так, для платформы win32/i386 используется несколько соглашений о передаче параметров. Соглашение о передаче параметров _cdecl
используется по умолчанию в программах на Си и Си++ и имеет следующие особенности [9]:
Параметры передаются в стеке и заносятся в стек справа налево (то есть первый в списке параметр заносится в стек последним).
Параметры выравниваются в стеке по границе 4 байт, и адреса всех параметров кратны 4. То есть параметры типа char
и short передаются как int, но и дополнительное выравнивание для размещения, например, double
не производится.
Очистку стека производит вызывающая функция. Регистры %eax, %ecx, %edx и %st(0) – %st(7) могут свободно использоваться (не должны сохраняться при входе в функцию и восстанавливаться при выходе из нее).
Регистры %ebx, %esi, %edi, %ebp не должны модифицироваться в результате работы функции.
Значения целых типов, размер которых не превосходит 32 бит, возвращаются в регистре %eax, 64-битных целых типов – в регистрах %eax и %edx, вещественных типов – в регистре %st(0).
Если функция возвращает результат структурного типа, то место под возвращаемое значение должно быть зарезервировано вызывающей функцией. Адрес этой области памяти передается как (скрытый) первый параметр.
Отметим, что этот набор правил – это именно соглашения, которые «добровольно» выполняются в сгенерированном коде. Пока речь не заходит об интерфейсе с независимо скомпилированными сторонними модулями, программист может в определенной мере модифицировать эти правила, существенно затрудняя задачу автоматического восстановления функций.
Опять же можно предполагать, что если программа декомпилируется из автоматически полученного ассемблерного кода (либо компилятором, либо дизассемблером), то в ней используются только соглашения о передаче параметров из некоторого предопределенного множества. Причем в одной программе для разных функций не могут использоваться разные соглашения о передаче параметров.
На первом этапе решения задачи выявления параметров функций следует определить следующие особенности вызова функций:
Используемое соглашение о передаче параметров. Требуется определить, какое соглашение из набора предопределенных соглашений используется в программе.
Размер области параметров функции. Почти все соглашения о передаче параметров могут быть достаточно надежно идентифицированы по используемым инструкциям. Так, соглашение о передаче параметров stdcall требует, чтобы параметры из стека удалялись вызываемой функцией. Для этого может использоваться единственная инструкция системы команд i386 – ret N, где N
– размер удаляемых из стека параметров. Таким образом, использование этой инструкции для возврата из функции указывает как на соглашение о передаче параметров, так и на размер параметров функции.
В случае вызова функции по указателю при статическом анализе нам может быть неизвестен адрес вызываемой функции. В этом случае не представляется возможным отследить, как возвращается управление из вызываемой функции. Определение соглашения о вызовах тогда должно быть отложено на фазы последующего анализа.
Итак, на фазе выявления параметров и возвращаемых значений определяется размер передаваемых в функцию параметров и способ возврата значения из функции. В дальнейшем эта информация используется как начальная при восстановлении символических имен и восстановлении типов.
