Фиктивный трек в Pre-gap подлинного трека
Размещение фиктивного трека в области Pre-gap области первого подлинного трека приводит к довольно интересным результатам, обсуждению которых не грех посвятить отдельныйую разделглаву. На первый взгляд такая защита полностью аналогична предыдущей, с той лишь разницей, что теперь исказиться адрес первого, а не второго треков. Да, это так, но лишь отчасти! Область Pre-gap первого трека —– особеннаяый. Мало того, что по стандарту она вообще не доступнаен для чтения (хотя некоторые приводы вроде бы ухитряются ееего читать), так еще и LBA-адрес еего начала измеряется отрицательным числом! Вспомним, что адреса LBA адреса связаны с абсолютными адресами следующим соотношением:
LBA = ((Min * 60) + Sec) * 75 + Frame – 150,
где 150 и есть sizeof(pre--gap).
Абсолютный стартовый адрес первого нормального трека по стандарту должен быть равен 00:02:00 (что соответствует LBA-адресу 0h), абсолютный стартовый адрес первой областиго Pre-gap —– 00:00:00 (что соответствует LBA-адресу –96h и –150 в десятичной нотации). Даже если разработчик копировщика использовал для хранения адресов знаковые переменные это все равно ничего не меняет, поскольку аргументы команд READ и READ CD всегда представляют собой беззнаковые числа! К тому же, размещение второго трека в области Post-gap'e первого приводит к тому, что стартовый адрес второго трека становится меньше стартового адреса первого трека, к чему подавляющее большинство копировщиков просто не готово.
Скопировать содержимое первой областиго Pre-gap (в которойм расположен фиктивный трек) —– нельзя, да, собственно, и не нужно. Но всякий ли копировщик об этом знает? Если только его разработчики заранее не предусмотрели обработку такой ситуации, копировщик в зависимости от типа используемой им адресации либо выдаст ошибку чтения (абсолютная адресация), либо совершит очень далекое перемещение головкой по "сумасшедшему" LBA-адресу (LBA-адресация без проверки корректности адресов), либо же просто не будет знать, что ему с этим отрицательным адресом делать (LBA-адресация с проверкой корректности адресов).
Забегая вперед, отметим, что с защитой данного типа (кодовое наименование "Шакал") способен справиться один лишь Clone CDCloneCD.
Используя файл IMAGE.CCD, оставшийся от предыдущих эксприменов с "лисой", давайте переместим начало фиктивного трека по абсолютному адресу 00:01:00, как это показано в листинге 6.16.ниже:
Листинг 6.16. Фиктивный трек в Post-gap подлинного трека, расположенный по адресу 00:01:00
[Entry 4]
Session=1
Point=0x02
ADR=0x01
Control=0x04
TrackNo=0
AMin=0
ASec=0
AFrame=0
ALBA=-150
Zero=0
PMin=00
PSec=01
PFrame=0
PLBA=-1
Листинг 8 фиктивный трек в post-gap подлинного трека, расположенный по адресу 00:01:00
При открытии отредактированного файла IMAGE.CCD, копировщик Clone CDCloneCD неправильно вычисляет длину первого трека (см. листинг 6.17 ниже), однако на "прожиге" болванкеи это обстоятельство никак не сказывается.
Листинг 6.17. CloneCD выдает неправильную информацию о длине первого трека
ИНФОРМАЦИЯ О СЕССИИ 1:
Размер сессии: 4726 Кбайт
Число треков: 2
Track 1: Данные Mode 1, размер: 4.294.967.124 Кбайт
Track 2: Данные Mode 1, размер: 4899 Кбайт
ИНФОРМАЦИЯ О СЕССИИ 2:
Размер сессии: 3939 Кбайт
Число треков: 1
Track 3: Data, размер: 3939 Кбайт
Листинг 9 Clone CD выдает неправильную информацию о длине первого трека
Проверка показывает, что защищенный таким способом диск, нормально читается на приводах NEC и TEAC, а ASUS "видит" лишь первый трек первой сессии диска, поэтому закладываться на вторую и все последующие сессии —– неразумно да и не безопасно для своего здоровья (разъяренные пользователи при случаи и побить могут).
При попытке скопировать защищенный диск шатными копировщиками, последние ведут себя довольно странно. Stopm Record Now! и Ahead Nero вообще отказываются читать такой диск, "ругаясь" на Invalid Disk и Imvalid Track Mode соотвественно.
Столкнувшись с фиктивным треком в области Pre-gap, Ahead Nero совершенно дезореентируется и при попытке определения геометрии диска впадает в грубые ошибки (см. рис. 6.9рис. 0x101). Ну, то что длина первого трека определяется неправльно —– это нас и не удивляет, но вот насколько же нужно быть "тупым", чтобы не суметь определить атрибуты всех остальных треков —– это уже интересно! Стартовый адрес второго трека, равный 3728:17:16 со всей своей очевидностью указывает на то, что в качестве базового типа адресации Ahead Nero использует беззнаковоые LBA-адреса, оперативно переводя их в MSF при необходимости. Поскольку, беззнаковый LBA-адрес начала второго трека представляет собой очень большое положительное число, разница между стартовым адресом Lead-outLead-Out и стартовым адресом фиктивного трека вновь оказывается отрицательна, что окончально запутывает Ahead Nero, приводя его к катострофически неверному результату. О причинах же неудачного определения типа третьего трека остается только гадать. Наверное, это как-то связано с неправильным определением количества сессий: Ahead Nero "увидел" всего лишь одну сессию из двух. Только не спрашивайте меня почему, я этого все равно не знаю, а обращаться за разьяснениями в службу технической поддержки мне лень, да и не подписывался я сообщать разработчикам о "ляпах" в их программе. Пускай лучше думают головой, чем гонятся за деньгами.

Рис. 6.9. унок 4 0x101 Ahead Nero, встретив фиктивный трек в Pre-gap подлинного трека запутался настолько, что не смог определить длину ни одного из треков и некорректно определил адрес второго — – фиктивного трека.
Попытка сканирования поверхности диска утилитой Ahead Nero CD Speed на предмет поиска повержденных секторов (~Extra à ScanDisk) приводит к тому, что окно программы просто "слетает". Тесты такие как "CPU Usage", "Spin Up/Dows" так же останавливается с сообщением об ошибке.
Таким образом, размещение фиктивного трека в области Post-gape'e подлинного трека может служить эффективным средстом борьбы с утилитами, определяющими качество диска, позволяя тем самым продавать дефективные диски под видом хороших. Нет, это отнюдь не призыв (за такое морды бить надо!). Напротив, это грустная констатация факта, что мир в котором мы живем, не иделен и доверять нельзя никому и ничему. Ладно, не будемт вдаваться в лирику, а лучше попробуем скопировать защищенный диск Alcohol 120%Алкоголиком.
Если только галочка флажок Попуск ошибок чтения [Y174] [n2k175] "попуск ошибок чтения" не была заблаговременно взведенаустановлен, то программа Alcohol 120%Алкоголик, прервав чтение диска на 13%, "невнятно ругнется" на "Illegal Mode For This Trak" и предложить удалить незавершенные файлы. Как бы сказал чЧучкча из анедота про оленей "Тенденция, однако!"
Чтение диска с пропуском ошибок так же не дает никакого результата. Достигнув сектора 2056 (предпоследний сектор в Post-gap подлинного трека), Alcohol 120% Алкоголик со всего маху "врзезается" в область Lead-outLead-Out широко "раскинув мозгами" (в смысле —– разбросав ихей по всей терриотрии).
Финал[Y81] [n2k82]
В листинге 2.25Ниже приведен законченный примерм использования корректирующих кодов на практике, пригодный для решения реальных практических задач.
Листинг 21.25. Пример вызова функций библиотеки ElByECC.DLL из своей программы
/*----------------------------------------------------------------------------
*
* демонстрация ElByECC.DLL
* ========================
*
* данная программа демонстрирует работу с библиотекой ElByECC.DLL,
* генерируя избыточные коды Рида-Соломона на основе пользовательских данных,
* затем умышленно искажает их и вновь восстанавливает.
* количество разрушаемых байтов передается в первом параметре командной
* строки (по умолчанию - 6)
----------------------------------------------------------------------------*/
#include <stdio.h>
#include "ElByECC.h" // декомпилировано МЫЩЪХем
#define _DEF_DMG 6 // рушить по умолчанию
#define N_BYTES_DAMAGE ((argc>1)?atol(argv[1]):_DEF_DMG) // сколько байт
// рушить?
main(int argc, char **argv)
{
int a;
char stub_head[HEADER_SIZE]; // заголовок сектора
char user_data[USER_DATA_SIZE]; // область польз. данных
struct RAW_SECTOR_MODE1 raw_sector_for_damage; // сектор для искажений
struct RAW_SECTOR_MODE1 raw_sector_for_compre; // контрольная копия сект.
// TITLE
//------------------------------------------------------------------------
printf("= ElByECC.DLL usage demo example by KK\n");
// инициализация пользовательских данных
//------------------------------------------------------------------------
printf("user data initialize...............");
for (a = 0; a < USER_DATA_SIZE; a++) user_data[a] = a; // user_data init
memset(stub_head, 0, HEADER_SIZE); stub_head[3] = 1; // src header init
printf("+OK\n");
// генерация кодов Рида- Соломона на основе пользовательских данных
//-----------------------------------------------------------------------
printf("RS-code generate...................");
a = GenECCAndEDC_Mode1(user_data, stub_head, &raw_sector_for_damage);
if (a == ElBy_SECTOR_ERROR) { printf("-ERROR!\x7\n"); return -1;}
memcpy(&raw_sector_for_compre, &raw_sector_for_damage, RAW_SECTOR_SIZE);
printf("+OK\n");
// умышленное искажение пользовательских данных
//------------------------------------------------------------------------
printf("user-data %04d bytes damage........", N_BYTES_DAMAGE);
for (a=0;a<N_BYTES_DAMAGE;a++) raw_sector_for_damage.USER_DATA[a]^=0xFF;
if(!memcmp(&raw_sector_for_damage,&raw_sector_for_compre,RAW_SECTOR_SIZE))
printf("-ERR: NOT DAMAGE YET\n"); else printf("+OK\n");
// проверка целостности пользовательских данных
//------------------------------------------------------------------------
printf("user-data check....................");
a = CheckSector((struct RAW_SECTOR*)&raw_sector_for_damage,ElBy_TEST_ONLY);
if (a==ElBy_SECTOR_OK){
printf("-ERR:data not damage\x7\n");return -1;}printf(".data damge\n");
// восстановление пользовательских данных
//------------------------------------------------------------------------
printf("user-data recorver.................");
a = CheckSector((struct RAW_SECTOR*)&raw_sector_for_damage, ElBy_REPAIR);
if (a == ElBy_SECTOR_ERROR) {
printf("-ERR: NOT RECORVER YET\x7\n"); return -1; } printf("+OK\n");
// проверка успешности восстановления
//------------------------------------------------------------------------
printf("user-data recorver check...........");
if(memcmp(&raw_sector_for_damage,&raw_sector_for_compre,RAW_SECTOR_SIZE))
printf("-ERR: NOT RECORVER YET\x7\n"); else printf("+OK\n");
printf("+OK\n");
return 1;
}
Функция CheckSector
Функция CheckSector (листинг2.24) осуществляет проверку целостности сектора по контрольной сумме и при необходимости выполняет его восстановление по избыточным кодам Рида-Соломона.
Листинг 21.24. Прототип функции CheckSector
CheckSector(struct RAW_SECTOR *sector, // указатель на секторный буфер
int DO); // только проверка/лечение
Где:
q sector — указатель на 2352-байтовый блок данных, содержащий подопытный сектор. Лечение сектора осуществляется в "живую", т. е. непосредственно по месту возникновения ошибки. Если количество разрушенных байт превышают корректирующие способности кодов Рида-Соломона, исходные данные остаются неизменными;
q
q DO — флаг, нулевое значение которого указывает на запрет модификации сектора. Другими словами, соответствует режиму TEST ONLY. Ненулевое значение разрешает восстановление данных, если они действительно подверглись разрушению.
При успешном завершении функция возвращает ненулевое значение и ноль если сектор содержит ошибку (в режиме TEST ONLY) или если данные восстановить не удалось (при вызове функции в режиме лечения). Для предотвращения возможной неоднозначности рекомендуется вызывать данную функцию в два приема. Первый раз — в режиме тестирования для проверки целостности данных, и второй раз — в режиме лечения (если это необходимо).
Функция GenECCAndEDC_Mode1 осуществляет генерацию корректирующих кодов на основе 2048-байтового блока пользовательских данных и имеет следующий прототип (листинг 2.22).:
Листинг 21.22. Прототип функции GenECCAndEDC_Mode1
GenECCAndEDC_Mode1(char *userdata_src, // указатель на массив из 2048 байт
char *header_src, // указатель на заголовок
struct RAW_SECTOR_MODE1 *raw_sector_mode1_dst)
Где:
q userdata_src — указатель на 2048-байтовый блок пользовательских данных для которых необходимо выполнить расчет корректирующих кодов. Сами пользовательские данные в процессе выполнения функции остаются неизменными и автоматически копируются в буфер целевого сектора, где к ним добавляется 104 + 172 байт четности и 4 байта контрольной суммы;.
q
q header_src — указатель на 4-байтовый блок, содержащий заголовок сектора. Первые три байта занимает абсолютный адрес, записанный в BCD-форме, а четвертый байт отвечает за тип сектора, которому необходимо присвоить значение 1, и соответствующий режиму "корректирующие коды задействованы";.
q
q raw_sector_mode1_dst — указатель на 2352-байтовый блок в который будет записан сгенерированный сектор, содержащий 2048-байт пользовательских данных и 104+172 байт корректирующих кодов вместе 4 байтами контрольной суммы и представленный следующей структурой, представленной в листинге 2.23. :
Листинг 21.23. Структура "сырого" сектора
struct RAW_SECTOR_MODE1
{
BYTE SYNC[12]; // синхрогруппа
BYTE ADDR[3]; // абс. адрес сектора
BYTE MODE; // тип сектора
BYTE USER_DATA[2048]; // пользовательские данные
BYTE EDC[4]; // контрольная сумма
BYTE ZERO[8]; // нули (не используется)
BYTE P[172]; // P-байты четности
BYTE Q[104]; // Q-байты четности
};
При успешном завершении функция возвращает ненулевое значение и ноль в противном случае.
>>>>> Хакерские секреты. Рецепты "тормозной жидкости" для CD
Появление высокоскоростных приводов CD-ROM породило огромное количество проблем ии, по общему мнениюмнению, пользователей плюсов здесь гораздо меньше, чем минусов. Этого реактивный гул, вибрация, разорванные в клочья диски –— скажите, на кой черт все это вам нужно? К тому же, многие из алгоритмов привязки к CD на высоких скоростях чувствуют себя крайне неустойчиво, и защищенный диск запускается далеко не с первого раза, если вообще запускается. Какой же из всего этого выход? Естественно –— тормозить! Благо, команду SET CD SPEED (опкод 0BBh) большинство приводов все-таки поддерживает. Казалось бы, задал нужные параметры и вперед! Ан нет, –— тут все не так просто…
Неприятность первая (маленькая, но зато досадная!). Скорость задается не в "иксах", а в килобайтах в секунду (именно в килобайтах, а не байтах!). Причем однократной скорости передачи соответствует пропускная способность в 176 Ккилобайт/ в секунду. А двукратной? Думаете, 176 ´x 2 == 352? А вот и нет –— 353! Зато трехкратная скорость вычисляется в полном соответствии с привычной нам математикой: 176 ´x 3 == 528, но уже четырех кратная скорость опять отклоняется от "иксов": 176 ´x 4 == 704, против 706 по стандарту. Неправильно заданная скорость приводит к установке скорости на ступень меньшей ожидаемой, причем соответствие между "иксками" и ступенями далеко не однозначное. Допустим, привод поддерживает следующий ряд скоростей: 16x, 24x, 32x и 40х. Если заданная скорость (в килобайтах в секунду) не дотягивает до нормативной скорости 32 "икса", то привод переходит на ближайшую "снизу" поддерживаемую им скорость, т. е. в нашем случае 16х. Отсюда мораль, для перевода "иксов" в килобайты в секунду их нужно умножать не на 176, а на 177!
Неприятность вторая (крупнее и досаднее). Команды, выдающей полный список поддерживаемых скоростей в стандартной спецификации, нет, и добывать эту информацию приходится исключительно методом перебора.
Корректно работающая программа перед началом такого перебора должна убедиться в отсутствии носителя в приводе, а если он там есть –— принудительно открыть лоток. Дело в том, что раскручивание некачественного CD-ROM диска до высоких скоростей может привести к его разрыву и вытекающей отсюда порче самого привода. Пользователь должен быть абсолютно уверен в том, что установленный в привод диск будет вращаться именно с той скоростью, с которой его просят, и его программа не станет самопроизвольно увеличивать скорость без видимых на то причин.
Неприятность третья (или "тихий ужас"). Некоторые приводы (в частности TEAK 522E) успешно "заглатывают" команду SET CD SPEED и подтверждают факт изменения скорости, возвращая в MODE SENSE ее новое значение, однако физически скорость диска остается неизменной вплоть до тех пор, пока к нему не произойдет того или иного обращения. Поэтому, вслед за командой SET CD SPEED, недурно бы дать команду чтения сектора с диска, если, конечно, диск вообще присутствует. Изменять же скорость привода без диска в лотке –— совершенно бессмысленная операция, пригодная разве что для построения ряда поддерживаемых скоростей, т. к. после вставки нового диска в привод его прежние скоростные установки оказываются недействительными, и наиболее оптимальная (с точки зрения привода!) скорость для каждого диска определяется индивидуально. Так же привод вправе изменять скорость диска по своему усмотрению, понижая ее, если чтение идет неважно и, соответственно, увеличивая обороты, если же все идет хорошо.
Идея кодов Рида-Соломна
Если говорить упрощенно, то основная идея помехозащитного кодирования Рида-Соломона заключается в умножении информационного слова, представленного в виде полинома D, на неприводимый полином G
(т.е. такой полином, который не разлагается в произведение полиномов меньшей степени), известный обоим сторонам, в результате чего получается кодовое слово C, опять таки представленное в виде полинома.
Декодирование осуществляется с точностью до наоборот: если при делении кодового слова C на полином G, декодер внезапно получает остаток, то он может "рапортовать наверх" об ошибке. Соответственно, если кодовое слово разделилось нацело, то — его передача завершилась успешно.
Если степень полинома G (называемого так же порождающим полиномом) превосходит степень кодового слова по меньшей мере на две степени, то декодер может не только обнаруживать, но и исправлять одиночные ошибки. Если же превосходство степени порождающего полинома над кодовым словом равно четырем, то восстановлению поддается и двойные ошибки. Короче говоря, степень полинома k
связана с максимальным количеством исправляемых ошибок t следующим образом: k = 2*t. Следовательно, кодовое слово должно содержать два дополнительных символа на одну исправляемую ошибку. В то же время, максимальное количество распознаваемых ошибок равно t, т. е. избыточность составляет один символ на каждую распознаваемую ошибку.
В отличии от кодов Хемминга, коды Рида-Соломона могут исправлять любое разумное количество ошибок при вполне приемлемом уровне избыточности. Спрашиваете, за счет чего это достигается? Смотрите, в кодах Хемминга контрольные биты контролировали лишь те информационные биты, что находятся по правую сторону от них и игнорировали всех "левосторонних" товарищей". Обратимся к таблице 21.1, — добавление восьмого контрольного бита D ничуть не улучшило помехозащищенность кодирования, поскольку контрольному биту D было некого контролировать. В кодах же Рида-Соломона контрольные биты распространяют свое влияние на все информационные биты и потому, с увеличением количества контрольных бит, увеличивается и количество распознаваемых/устраняемых ошибок.
Именно благодаря последнему обстоятельству, собственно, и вызвана ошеломляющая популярность корректирующих кодов Рида-Соломона.
Теперь о грустном. Для работы с кодами Рида-Соломона обычная арифметика, увы, не подходит и вот почему. Кодирование предполагает вычисления по правилам действия над многочленами, с коэффициентами которых надо выполнять операции сложения, вычитания, умножения и деления, причем все эти действия не должны сопровождаться каким-либо округлением промежуточных результатов (даже при делении!), чтобы не вносить неопределенность. Причем, и промежуточные, и конечные результаты не имеют права выходить за пределы установленной разрядной сетки… постой! Воскликнет внимательный читатель! Да ведь это невозможно! Чтобы при умножении и не происходило "раздувания" результатов, — кто же в этот бред поверит?!
Впрочем, если как следует подумать головой, частично призвав на помощь и другие части тела, можно сообразить, что умножать информационное слово на порождающий полином вовсе и не обязательно, можно поступить гораздо хитрее:.
1. Добавляем к исходному информационному слову D
справа k нулей, в результате чего у нас получается слово длины n = m + r и полином Xr**D, где m — длина информационного слова.;
2. Делим полученный полином Xr**D на порождающий полином G и вычисляем остаток от деления R, такой что: Xr*D = G*Q + R, где Q — частное, которое мы благополучно игнорируем за ненадобностью, — сейчас нас интересует только остаток.;
3. Добавляем остаток R к информационному слову D, в результате чего получаем "симпатичное" кодовое слово C, информационные биты которогоых хранятся отдельно от контрольных бит. Собственно, тот остаток, который мы получили в результате деления — и есть корректирующие коды Рида-Соломона. Между нами говоря, способ кодирования, при котором информационные и контрольные символы хранятся раздельно называется систематическим кодированием и такое кодирование весьма удобно с точки зрения аппаратной реализации.
4. Мысленно прокручиваем пункты 1, 2 и 3 пытаясь обнаружить на какой же стадии вычислений происходит выход за разрядную сетку и… такой стадии нет! Все нормальнопучком! Остается лишь отметить, что информационное слово + плюс корректирующие коды можно записать как: T == Xr*D + R = GQ.
Декодирование полученного слова T
осуществляется точно так же, как уже и было описано ранее. Если при делении слова T (которое в действительности является произведением G на Q) на порождающий полином G образуются остаток, то слово T искажено и, соответственно, наоборот.
Теперь — вопрос на засыпку. Как вы собираетесь осуществлять деление полиномов в рамках общепринятой алгебры? В целочисленной арифметике деление определено не для всех пар чисел (вот в частности, 2 нельзя разделить на 3, а 9 нельзя разделить на 4, — без потери значимости естественно). Что же касается "плавучки", — то ее точность еще та (в смысле точность катастрофически недостаточная для эффективного использования кодов Рида-Соломона), к тому же она достаточнодовольно сложна в аппаратной реализации. Ладно, в IBM PC с процессором Pentium, быстродействующий математическийх сопроцессор всем нам дан по дефолооту, но что делать разработчикам ленточных накопителей, винчестеров, приводов CD-приводов наконец? ИспользоватьПихать в них процессор Pentium 4четвертый Пень?! Нет уж, увольте, — лучше воспользоваться специальной арифметикой, — арифметикой конечных групп, называемых полями Галуа. Достоинство этой арифметики в том, что операции сложения, вычитания, умножения и деления определены для всех членов поля (естественно, исключая ситуацию деленияе на ноль), причем, число, полученное в результате любой из этих операций, обязательно присутствует в группе! Таким образом. е. при делении любого целого числа A, принадлежащего множеству 0…255 на любое целое число B из того же множества (естественно, B не должно быть равно нулю), мы получим число C, входящее в данное множество.
А поэтому, потерь значимости не происходит и никакой неопределенности не возникает!
Таким образом, корректирующие коды Рида-Соломона основаны на полиномиальных операциях в полях Галуа и требует от программиста владения сразу несколькими аспектами высшей математики из раздела теории чисел. Как и все "высшее", придуманное математиками, поля Галуа есть суть абстракция, которую невозможно ни наглядно представить, ни "пощупать" руками. ЕеЕе просто надо просто принять как набор аксиом, не пытаясь вникнуть в его смыл, достаточно всего лишь знать, что она работает — вот и все. А еще есть полиномы "немерянных" степеней и матрицы в "пол-Европы", от которых нормального системщика извините тошнитза выражение блевать тянет (увы, программист-математик скорее исключение, чем правило).
Поэтому, прежде чем ринуться в непроходимые джунгли математического леса абстракций, давайте сконструируем макет кодера/декодера Рида-Соломона, работающий по правилам обычной целочисленной алгебры. Естественно, за счет неизбежного в этом случае расширения разрядной сетки, такому кодеру/декодеру будет очень трудно найти практическое применение, но… зато он нагляден и позволяет не только понять, но и почувствовать принцип работы корректирующих кодов Рида-Соломона.
Мы будем исходить из того, что если g = 2n + 1, то для любого a a из диапазона 0…2n, произведение a*g = c (где с — кодовое слово), будет представлять по сути полную мешанину битов обоих исходных чисел.
Допустим n = 2, тогда g = 3. Легко видеть, — на что бы мы не умножали g — хоть на 0, хоть на 1, хоть на 2, хоть на 3, полученный результат делиться нацело на g в том и только в том случае, если никакой из его битов не инвертирован (т.о е.сть, попросту говоря, одиночные ошибки — отсутствуют).
Остаток от деления однозначно указывает на позицию ошибки (при условии, что ошибка одиночная, групповые же ошибки данный алгоритм исправлять не способен).
Точнее, если ошибка произошла в позиции x, то остаток от деления k будет равен k = 2x. Для быстрого определения x по k
можно воспользоваться тривиальным табличным алгоритмом. Впрочем, для восстановления сбойного бита знать его позицию совершенно необязательно, достаточно сделать R = e ^ k, где e — искаженное кодовое слово, ^ — операция XOR (исключающее ИЛИ), а R — восстановленное кодовое слово.
В общем, законченная реализация кодера/декодера Рида-Соломона, работающего по обычной арифметике (т. е. с неоправданным расширением разрядной сетки), и исправляющим любые одиночные ошибки в одном 8-битном информационном слове (впрочем, программу легко адоптировать и под 16-байтовые информационные слова), может выглядеть так как показано в листинге 2.9. Обратите внимание, что кодер реализуется чуть ли не на порядок проще декодера. В настоящем декодере Рида-Соломна, способном исправлять групповые ошибки, этот разрыв еще значительнее. :
Листинг 21.9. [/etc/EDC.ECC/rs.simplest.c] Простейший пример реализации кодера/декодера Рида-Соломона, работающего по обычной арифметике (т.е. с неоправданным расширением разрядной сетки), и исправляющим любые одиночные ошибки в одном 8-битном информационном слове (впрочем, программу легко адоптировать и под 16-байтовые информационные слова). Обратите внимание, что кодер реализуется чуть ли не на порядок проще декодера. В настоящем декодере Рида-Соломна, способном исправлять групповые ошибки, этот разрыв еще значительнее.
/*----------------------------------------------------------------------------
*
* ПРОСТЕЙШИЙ КОДЕР/ДЕКОДЕР РИДА-СОЛОМОНА
* ======================================
*
* Build 0x001 @ 02.07.2003
----------------------------------------------------------------------------*/
// ВНИМАНИЕ! данный кодер/декодер построен на основе обычной арифметики,
// _не_ арифметики полей Галуа, в результате чего его практические возможности
// более чем ограничены, тем не менее он нагляден и удобен для изучения
#include <stdio.h>
#define SYM_WIDE 8 // ширина входного информационного символа (бит)
#define DATAIN 0x69 // входные данные (один байт)
#define ERR_POS 3 // номер бита, который будет разрушен сбоем
// неприводимый полином
#define MAG (1<<(SYM_WIDE*1) + 1<<(SYM_WIDE*0))
// -------------------------------------------------------------------------------
// определение позиции ошибки x по остатку k от деления кодового слова на полином
// k = 2^x, где "^" – возведение в степень
// функция принимает k и возвращает x
// -------------------------------------------------------------------------------
int pow_table[9] = {1,2,4,8,16,32,64,128,256};
lockup(int x) {int a;for(a=0;a<9;a++) if(pow_table[a]==x)return a; return -1;}
main()
{
int i; int g; int c; int e; int k;
fprintf(stderr,"simplest Reed-Solomon endoder/decoder by Kris Kaspersky\n\n");
i = DATAIN; // входные данные (информационное слово)
g = MAG; // неприводимый полином
printf("i = %08x (DATAIN)\ng = %08x (POLYNOM)\n", i, g);
// КОДЕР РИДА-СОЛОМОНА (простейший, но все-таки кое-как работающий)
// вычисляем кодовое слово, предназначенное для передачи
c = i * g; printf("c = %08x (CODEWORD)\n", c);
// конец КОДЕРА
// передаем с искажениями
e = c ^ (1<<ERR_POS); printf("e = %08x (RAW RECIVED DATA+ERR)\n\n", e);
/* ^^^^ искажаем один бит, имитируя ошибку передачи */
// ДЕКОДЕР РИДА-СОЛОМОНА
// проверяем на наличие ошибок передачи
// (фактически это простейший декодер Рида-Соломона)
if (e % g)
{
// ошибки обнаружены, пытаемся исправить
printf("RS decoder says: (%x) error detected\n{\n", e % g);
k = (e % g); // k = 2^x, где x - позиция сбойного бита
printf("\t0 to 1 err position: %x\n", lockup(k));
printf ("\trestored codeword is: %x\n}\n", (e ^= k));
}
printf("RECEIVED DATA IS: %x\n", e / g);
// КОНЕЦ ДЕКОДЕРА
}
Результат работы простейшего кодера/декодера Рида-Соломона показан в листинге 2.10. Обратите внимание — искаженный бит удалось успешно исправить, однако, для этого к исходному информационному слову пришлось добавить не два, а целых три бита (если вы возьмете в качестве входного слова максимально допустимое восьмибитное значение 0xFF, то кодовое слово будет равно 0x1FE00, а так как 210 = 1024, то свободных разрядов уже не хватает и приходится увеличивать разрядную сетку до 211, в то время как младшие биты кодового слова фактически остаются незадействованными и "правильный" кодер должен их "закольцевать", грубо говоря замкнув обрабатываемые разряды на манер кольца.
Листинг 21.10. Результат работы простейшего кодера/декодера Рида-Соломона работы простейшего кодера/декодера Рида-Соломона. Обратите внимание — искаженный бит удалось успешно исправить, однако, для этого к исходному информационному слову пришлось добавить не два, а целых три бита (если вы возьмете в качестве входного слова максимально допустимое восьми битное значение 0xFF, то кодовое слово будет равно 0x1FE00, а так как 210 = 10000, то свободных разряднов уже не хватает и приходится увеличивать разрядную сетку до 211, в то время как младшие биты кодового слова фактически остаются незадействованными и "правильный" кодер должен их "закольцевать", грубо говоря замкнув обрабатываемые разряды на манер кольца.
i = 00000069 (DATAIN)
g = 00000200 (POLYNOM)
c = 0000d200 (CODEWORD)
e = 0000d208 (RAW RECIVED DATA+ERR)
RS decoder says: (8) error detected
{
0 to 1 err position: 3
restored codeword is: d200
}
RECEIVED DATA IS: 69
Интерфейс с библиотечкой ElByECC.DLL
Программная реализация кодера/декодера Рида-Соломона, приведенная в листингах 21.1?21.2, достаточно наглядна, но крайне непроизводительна и нуждается в оптимизации. Как альтернативный вариант можно использовать готовые библиотеки от сторонних разработчиков, входящие с состав программных комплексов так или иначе связанных с обработкой корректирующих кодов Рида-Соломона. Это и утилиты "прожига"/копирования/восстановления лазерных дисков, и драйвера ленточных накопителей (от стримера до Арвида[Y73] [n2k74] ), и различные телекоммуникационные комплексы и т. д.
Как правило, все эти библиотеки являются неотъемлемой частью самого программного комплекса и потому никак не документируется. Причем, восстановление прототипов интерфейсных функций представляет весьма нетривиальную задачу, требующую от исследователя не только навыков дизассемблирования, но и знаний высшей математики, иначе смысл всех битовых манипуляций останется совершенно непонятным.
Насколько законно подобное дизассемблирование? Да, дизассемблирование сторонних программных продуктов действительно запрещено, но тем не менее оно законно. Здесь уместно провести аналогию со вскрытием пломб вашего телевизора, влекущее потерю гарантии, но отнюдь не приводящее к уголовному преследованию. Так же, никто не запрещает вызывать функции чужой библиотеки из своей программы. Нелегально распространять эту библиотеку в составе вашего программного обеспечения, действительно, нельзя, но что мешает вам попросить пользователя установить данную библиотеку самостоятельно?
Ниже приводится описание важнейших функций библиотеки ElByECC.DLL, входящей в состав известного копировщика защищенных лазерных дисков Clone CD, условно-бесплатную копию которого можно скачать c cайта по адресу: http://www.elby.ch/. Сам Clone CD проработает всего лишь 21 день, а затем потребует регистрации, однако на продолжительность использования библиотеки ElByECC.DLL не наложено никаких ограничений.
Усилиями хакера по имени МЫЩЪХ [Y75] [n2k76] был создан h-файл, содержащий прототипы основных функций библиотеки ElByECC.DLL, специальная редакция которого была любезно предоставлена им для настоящей книги.
Несмотря на то, что библиотека ElByECC.DLL ориентирована на работу с секторами лазерных дисков, она может быть приспособлена и для других целей, например, построения отказоустойчивых дисковых массивов, о которых говорилось в предыдущемй разделеглаве.
Краткое описание основных функций библиотеки приводится далеениже.
Интерфейсы взаимодействия с оборудованием
Стандарты—– вещь хорошая. Всегда есть из чего выбрать.
Фольклор
Существует множество способов взаимодействия с оборудованием. В зависимости от специфики решаемой задачи и специфики самого оборудования, предпочтение отдается либо тем, либо иным интерфейсам управления. На самом высоком уровне интерфейсной иерархии располагается семейство API-функций (Application Programming Interface) операционной системы, реализующих типовые операции ввода/вывода (такие, например, как открыть файл, прочитать данные из файла). Для подавляющего большинства прикладных программ этого оказывается более, чем достаточно, однако даже простейший копировщик на этом наборе, увы, не напишешь и приходится спускаться по меньшей мере на один уровень вглубь, обращаясь непосредственно к драйверу данного устройства.
Стандартные дисковые драйверадрайвераы, входящие в состав операционных систем Windows 9x и Windows NT, поддерживают довольно ограниченное количество типовых команд (прочитать сектор, просмотреть TOC и т. д.), не позволяющих в должной мере реализовать все возможности современных приводов CD-ROM/R/RW, однако для написания простейших защитных механизмов их функциональных возможностейа окажется вполне достаточно.
Подавляющее большинство защитных механизмов данного типа безупречно копируется штатными копировщиками, что, собственно, и неудивительно: ведь и копировщик, и "защита" "кормятся" из одной и той же "кормушки", простите, используют идентичный набор управляющих команд, работающихй с устройством на логическом уровне.
Для создания устойчивой к взлому защиты мы должны опуститься "на самое дно колодца", заговорив с устройством на родном для него "языке". Несмотря на то, что контроллеры оптических накопителей поддерживают высокоуровневый набор управляющих команд (намного более высокоуровневый, чем приводы гибких дисков), несмотря на то, что интерфейс привода абстрагирован от конкретного физического оборудования, и несмотря на то, что диски CD-ROM/R/RW диски изначально не были ориентированы на защиту, создание практически не копируемых дисков на этом уровне все-таки возможно.
Вопреки расхожему мнению, для низкоуровневого управления накопителями совершенно необязательно прибегать к написанию своего собственного драйвера. Все необходимые драйверыа давно-даным уже написаны задо нас, и на выбор разработчика предоставляется несколько конкурирующих интерфейсов, обеспечивающих низкоуровневое взаимодействие со SCSI/ATAPI- устройствами с прикладного уровня. Это и ASPI (Advanced SCSI Programming Interface), и SPTI (SCSI Pass Through IOCTLs?), и MSCDEX (MS-DOS CD-ROM Extension) (ныне практически забытый, но все же поддерживаемый операционными системами Windows 98 и MEe). Каждый из интерфейсов имеет свои достоинства и свои недостатки, поэтому коммерческие программные пакеты вынуждены поддерживать их все.
Поскольку, программирование оптических накопителей выходит далеко за рамки предмета защиты лазерных дисков (основного предмета данной книги!), то интерфейсы взаимодействия с устройствами будут рассмотрены максимально кратко и упрощенно. К слову сказать, ряд книг, посвященных непосредственно управлению устройствами SCSI/ATAPI устройствами, значительно проигрывает настоящему разделу (взять, к примеру, "Программирование устройств SCSI и IDE" Всеволода Несвижского — СПб.: БХВ-Петербуерг, 2003 г., описывающего исключительно интерфейс ASPI и к тому же описывающего его неверноправильно).
Информации, приведенной далеениже, вполне достаточно для самостоятельного изучения всех вышеперечисленных интерфейсов с абсолютного нуля. Даже если вам никогда до этого не приходилось сталкиваться с программированием SCSI/ATAPI- устройств, вы навряд ли будете испытывать какие-либо затруднения по ходу чтения книги (не говоря уж о том, что данная книга научит вас основам "шпионажа" за чужими программами и взлому оных, но это строго между нами!).
Исходный текст декодера
Далее в листинге2.20Ниже приводится исходный текст полноценного декодера Рида-Соломона, снабженный минимально разумным количеством комментарием. При возникновении трудностей в анализе этого листинга обращайтесь к блок-схемам, приведенным на рис. 21.3, 21.4 и 21.5 [Y72] — они помогут.
Листинг 21.20. Исходный текст простейшего декодера Рида-Соломона
/*----------------------------------------------------------------------------
*
* декодер Рида-Соломона
* =====================
*
* процедура декодирования кодов Рида-Соломона состоит из нескольких шагов
* сначала мы вычисляем 2t-символьный синдром путем постановки alpha**i в
* recd(x), где recd – полученное кодовое слово, предварительно переведенное
* в индексную форму. По факту вычисления recd(x) мы записываем очередной
* символ синдрома в s[i], где i принимает значение от 1 до 2t, оставляя
* s[0] равным нулю.
* затем, используя итеративный алгоритм Берлекэмпа (Berlekamp), мы
* находим полином локатора ошибки – elp[i]. Если степень elp превышает
* собой величину t, мы бессильны скорректировать все ошибки и ограничиваемся
* выводом сообщения о неустранимой ошибке, после чего совершаем аварийный
* выход из декодера. Если же степень elp не превышает t, мы подставляем
* alpha**i, где i = 1..n в elp для вычисления корней полинома. Обращение
* найденный корней дает нам позиции искаженных символов. Если количество
* определенных позиций искаженных символов меньше степени elp, искажению
* подверглось более чем t символов и мы не можем восстановить их.
* во всех остальных случаях восстановление оригинального содержимого
* искаженных символов вполне возможно.
* в случае, когда количество ошибок заведомо велико для их исправления
* декодируемые символы проходят сквозь декодер без каких либо изменений
*
* на основе исходных текстов
* Simon'а Rockliff'а, от 26.06.1991
//-------------------------------------------------------------------
// вычисляем полином локатора ошибки через итеративный алгоритм
// Берлекэмпа. Следуя терминологии Lin and Costello (см. "Error
// Control Coding: Fundamentals and Applications" Prentice Hall 1983
// ISBN 013283796) d[u] представляет собой m ("мю"), выражающую
// расхождение
(discrepancy), где u = m + 1 и m есть номер шага
// из диапазона от –1 до 2t. У Блейхута та же самая величина
// обозначается D(x) ("дельта") и называется невязка.
// l[u] представляет собой степень elp для данного шага итерации,
// u_l[u] представляет собой разницу между номером шага и степенью elp
// инициализируем элементы таблицы
d[0] = 0; // индексная форма
d[1] = s[1]; // индексная форма
elp[0][0] = 0; // индексная форма
elp[1][0] = 1; // полиномиальная форма
for (i = 1; i < n - k; i++)
{
elp[0][i] = -1; // индексная форма
elp[1][i] = 0; // полиномиальная форма
}
l[0] = 0; l[1] = 0; u_lu[0] = -1; u_lu[1] = 0; u = 0;
do
{
u++;
if (d[u] == -1)
{
l[u + 1] = l[u];
for (i = 0; i <= l[u]; i++)
{
elp[u+1][i] = elp[u][i];
elp[u][i] = index_of[elp[u][i]];
}
}
else
{
// поиск слов с наибольшим u_lu[q], таких что d[q]!=0
q = u - 1;
while ((d[q] == -1) && (q>0)) q--;
// найден первый ненулевой d[q]
if (q > 0)
{
j=q ;
do
{
j-- ;
if ((d[j]!=-1) && (u_lu[q]<u_lu[j]))
q = j ;
} while (j>0);
};
// как только мы найдем q, такой что d[u]!=0
// и u_lu[q] есть максимум
// запишем степень нового elp полинома
if (l[u] > l[q]+u-q) l[u+1] = l[u]; else l[u+1] = l[q]+u-q;
// формируем новый elp(x)
for (i = 0; i < n - k; i++) elp[u+1][i] = 0;
for (i = 0; i <= l[q]; i++)
if (elp[q][i]!=-1)
elp[u+1][i+u-q]=alpha_to[(d[u]+n-d[q]+elp[q][i])%n];
for (i=0; i<=l[u]; i++)
{
elp[u+1][i] ^= elp[u][i];
// преобразуем старый elp
// в индексную форму
elp[u][i] = index_of[elp[u][i]];
}
}
u_lu[u+1] = u-l[u+1];
// формируем (u + 1)'ю невязку
//---------------------------------------------------------------------
if (u < n-k) // на последней итерации расхождение
{ // не было обнаружено
if (s[u + 1]!=-1) d[u+1] = alpha_to[s[u+1]]; else d[u + 1] = 0;
for (i = 1; i <= l[u + 1]; i++)
if ((s[u + 1 - i] != -1) && (elp[u + 1][i]!=0))
d[u+1] ^= alpha_to[(s[u+1-i]+index_of[elp[u+1][i]])%n];
// переводим d[u+1] в индексную форму
d[u+1] = index_of[d[u+1]];
}
} while ((u < n-k) && (l[u+1]<=t));
// расчет локатора завершен
//-----------------------------------------------------------------------
u++ ;
if (l[u] <= t)
{ // коррекция ошибок возможна
// переводим elp в индексную форму
for (i = 0; i <= l[u]; i++) elp[u][i] = index_of[elp[u][i]];
// нахождение корней полинома локатора ошибки
//--------------------------------------------------------------------
for (i = 1; i <= l[u]; i++) reg[i] = elp[u][i]; count = 0;
for (i = 1; i <= n; i++)
{
q = 1 ;
for (j = 1; j <= l[u]; j++)
if (reg[j] != -1)
{
reg[j] = (reg[j]+j)%n;
q ^= alpha_to[reg[j]];
}
if (!q)
{ // записываем корень и индекс позиции ошибки
root[count] = i;
loc[count] = n-i;
count++;
}
}
if (count == l[u])
{ // нет корней – степень elp < t ошибок
// формируем полином z(x)
for (i = 1; i <= l[u]; i++) // Z[0] всегда равно 1
{
if ((s[i]!=-1) && (elp[u][i]!=-1))
z[i] = alpha_to[s[i]] ^ alpha_to[elp[u][i]];
else
if ((s[i]!=-1) && (elp[u][i]==-1))
z[i] = alpha_to[s[i]];
else
if ((s[i]==-1) && (elp[u][i]!=-1))
z[i] = alpha_to[elp[u][i]];
else
z[i] = 0 ;
for (j=1; j<i; j++)
if ((s[j]!=-1) && (elp[u][i-j]!=-1))
z[i] ^= alpha_to[(elp[u][i-j] + s[j])%n];
// переводим z[i] в индексную форму
z[i] = index_of[z[i]];
}
// вычисление значения ошибок в позициях loc[i]
//--------------------------------------------------------------------
for (i = 0; i<n; i++)
{
err[i] = 0;
// переводим recd[] в полиномиальную форму
if (recd[i]!=-1) recd[i] = alpha_to[recd[i]]; else recd[i] = 0;
}
// сначала вычисляем числитель ошибки
for (i = 0; i < l[u]; i++)
{
err[loc[i]] = 1;
for (j=1; j<=l[u]; j++)
if (z[j]!=-1)
err[loc[i]] ^= alpha_to[(z[j]+j*root[i])%n];
if (err[loc[i]]!=0)
{
err[loc[i]] = index_of[err[loc[i]]];
q = 0 ; // формируем знаменатель коэффициента ошибки
for (j=0; j<l[u]; j++)
if (j!=i)
q+=index_of[1^alpha_to[(loc[j]+root[i])%n]];
q = q % n; err[loc[i]] = alpha_to[(err[loc[i]]-q+n)%n];
// recd[i] должен быть в полиномиальной форме
recd[loc[i]] ^= err[loc[i]];
}
}
}
else // нет корней,
// решение системы уравнений невозможно, т.к. степень elp >= t
{
// переводим recd[] в полиномиальную форму
for (i=0; i<n; i++)
if (recd[i]!=-1) recd[i] = alpha_to[recd[i]];
else
recd[i] = 0; // выводим информационное слово как есть
}
else // степень elp > t, решение невозможно
{
// переводим recd[] в полиномиальную форму
for (i=0; i<n; i++)
if (recd[i]!=-1)
recd[i] = alpha_to[recd[i]] ;
else
recd[i] = 0 ; // выводим информационное слово как есть
}
else // ошибок не обнаружено
for (i=0;i<n;i++) if(recd[i]!=-1)recd[i]=alpha_to[recd[i]];else recd[i]=0;
}
Искажение размеров файлов
Еще (или, скорее уже) во времена монохромных терминалов и 8" и 5.25"133" дискет существовал некрасивый, но элементарно реализуемый защитный примем, препятствующий пофайловому копированию носителя. Внося определенные искажения в структуры файлов системы, разработчики "грохали" дискету ровно настолько, чтобы работа с ней становилась возможной лишь при условии учета характера внесенных искажений. Защищенная программа, "знающая" об искажениях файловой структуры, работала с ней без проблем, то штатные утилиты операционной системы на таких дисках конкретно "обламывались", а общедоступных "хакерских" копировщиков в те времена еще не существовало…
Несколько файлов зачастую ссылались на общие для всех них кластера, тогда запись данных в один файл приводила к немедленному их появлению в другом файле, что защита могла так или иначе могла и использовать защита. Естественно, после копирования файлов на новый диск, пересекающиеся кластеры "разыменовывались"перераспределялись и хитрый способ неявной пересылки данных переставал работать, а вместе с ним переставала работать и сама защищенная программа. Если, конечно, содержимое диска вообще удавалось скопировать… Ведь копирование файлов с пересекающимися кластерами приводило к тому, что эти кластера многократно дублировались в каждом копируемом файле, в результате чего их суммарный объем под час увеличивался настолько, что емкости тогдашних носителей попросту не хватало для его вмещения! Если же последний кластер файла "приклеивался" к его началу (т. е. файл попросту зацикливался), то объем и время его копирования тут же обращались в бесконечность… Конечно, дисковые доктора в то время уже существовали, но их использование не давало желаемого результата, т. к. лечение файловой системы приводило к полной неработоспособности защиты (в том же случае с зацикливанием —– если защита закладывалась на то, что за концом файла следует его начало, то после обработки диска "доктором[Y190] [n2k191] ", осуществление этого приема становилось невозможным со всеми от сюда вытекающими последствиями).
Файловые системы лазерных дисков, конечно, совсем не те, что на гибких дисках, но общие принципы их искажений достаточно схожди. Увеличивая фиктивные длины защищаемых файлов на порядок-другой, разработчик защиты может довести их суммарный объем до нескольких сотен гигабайт, так что для копирования защищенного диска понадобитьсяпонадобится по меньшей мере пачка дисков DVD дисков или винчестер солидного объема. Защитный механизм, "помнящий" оригинальные длины всех файлов, сможет работать с ними без проблем, но все файловые копировщики не поймут "юмора и поедут крышей".
В принципе, выход за границы файла ничем не чреват. Файловые системы лазерных дисков очень просты. Лазерные диски не поддерживают фрагментацию файлов, а потому не нуждаются в FAT (File Allocation Table). Все файлы занимают непрерывный ряд секторов и с каждым файлом связаноы только две важнейшие характеристики: номер первого сектора файла, заданный в LBA (Logical Block Address) и его длина, заданная в байтах. Остальные атрибуты, вроде имени файла и времени его создания —– не в счет, мы сейчас говорим исключительно о секторах.
Увеличение длины файла приводит к "захвату" того или иного количества примыкающих к его "хвосту" секторов и при условии, что номер последнего сектора, принадлежащего файлу, не превышает номера последнего сектора диска, копирование файла в принципе протекает нормально ("в принципе" потому, что в копируемый файл оказываютсяоказывается включены все файлы, встретившиеся на его пути). Если же в процессе своего копирования файл "выскакивает" за конец диска, привод CD-ROM привод сигнализирует об ошибке и прекращает чтение. Штатный копировщик операционной системы (равно как и большинство оболочек сторонних производителей) автоматически удаляюет "огрызок" недокопированного файла с диска, в результате чего пользователь остается вообще ни с чем. Впрочем, написать свой собственный копировщик, —– минутное дело, но как узнать сколько именно байт следует скопировать? Как определить: где идут полезные данные, а где начинается "после-хвостовой" мусор" (over-end garbage).
Вот этим мы сейчас и займемся!
Стоп! Но ведь далеко не у всех есть лазерные диски, защищенные подобнымх образом. Что ж, сейчас они будут! Возьмем любой незащищенный диск и самостоятельно защитим его (все-таки эта книга посвященаназывается "техникеа защиты лазерных дисков от копирования", ано не техникеа изх взлома). Задачей номер один будет получение образа того диска, который вы собрались защищать. Лучше всего это делать с помощью программы Roxio Easy CD Creator или аналогичной ей. Копировщик Clone CD для этой цели непригоден, т. к. он наотрез отказывается осуществлять короткое чтение секторов (т. е. user data only) и всегда обрабатывает сектора целиком, принудительно записывая в конец каждого сектора контрольную сумму и корректирующие коды. В результате, все наши манипуляции над пользовательской областью сектора не возымеют никакого действия и будут налету исправлены микропроцессорной начинкой привода. Конечно, после внесения необходимых изменений контрольную сумму и корректирующие коды можно рассчитать заново, но… зачем понапрасну усложнять себе жизнь? Если у вас нет Easy CD Creator'a'а, —– возьмите Alcohol 120%, выбрав из всех, предлагаемых им форматов "Стандартные образы ISO".
ХорошоОК, будем считать что образ диска успешно сохранен в файл trask.iso[Y192] ,[n2k193] с которым мы сейчас и будет работать. Откроем его в HIEW'е или любом другом HEX-редакторе и найдем сектор, содержащий оглавление диска. Хорошенькое дело! А как нам его найти? Требуется как минимум полистать спецификацию файловых систем Joliet или /ISO-9660 или… немного подумать головой. Поскольку, размер файла задается в байтах, а не секторах (в секторах он задаться никак не может, время файловых систем, измеряющих файлы блоками давно прошло), то соответствующее поле можно найти тривиальным контекстным поиском. Выберем файл, длину которого мы хотим изменять и запишем ее в шестнадцатеричном виде. Пусть для определенности это будет файл "01 – – Personal Jesus.mp3" с длиной в 3 .591 .523 байт.В шестнадцатеричной нотации с учетом обратного порядка байт она будет выглядеть так: 63 CD 36 00. Нажимаем <F7> и вводим искомую последовательность…
Листинг 8.1. Первое вхождение искомой последовательности в образе диска
0000CBD0: 07 06 14 38 16 0C 02 00 ¦ 00 01 00 00 01 01 01 30 •¦¶8-+O O OOO0
0000CBE0: 00 91 01 00 00 00 00 01 ¦ 91 63 CD 36 00 00 36 CD СO OСc=6 6=
0000CBF0: 63 67 06 1D 17 0D 0A 28 ¦ 0C 00 00 00 01 00 00 01 cg¦-¦d0(+ O O
0000CC00: 0E 30 31 30 5F 30 30 30 ¦ 31 2E 4D 50 33 3B 31 00 d010_0001.MP3;1
Искажение TOC'а и его последствия
Искажение TOC'а — жестокий, уродливый но на удивление широко распространенный прием, использующийся в доброй половине защитных механизмов. Штатные копировщики (Easy CD Creator, Stomp Record Now[Y158] !, Ahead Nero Burning ROM) на таких дисках в буквальном смысле слова "сходят с ума" и "едут крышей". Копировщики защищенных дисков (Clone CDCloneCD, Alcohol 120%) к искаженному TOC'у относятся гораздо лояльнее, но требуют для своей работы определенного сочетания пишущего и читающего приводов, да и в этом случае копируют такой диск не всегда.
Пишущий привод обязательно должен поддерживать режим RAW DAO (Disc At Once[Y159] [n2k160] ), –— в котором весь диск записывается за один проход лазера. Режим RAW SAO (Session At Once) для этих целей совершенно непригоден, поскольку предписывает приводу писать сначала содержимое сессии, а потом –— TOC. Как следствие –— приводу приходится самостоятельно анализировать TOC, чтобы определить стартовый адрес сессии и ее длину. Попытка записать искаженный TOC в режиме RAW SAO в общем случае приводит к непредсказуемому поведению привода и работоспособной копии защищенного диска нечего и думать! Первая, встретившаяся приводу, сессия с искаженным TOC'ом, обычно оказывается и последней, т. к. остальные сессии писать уже некуда
(искажение TOC'а обычно преследует цель увеличения размера сессии до нескольких гигабайт).
Читающий привод помимо режима "сырого" чтения (который поддерживают практически все приводы) должен уметь распознавать искаженный TOC, автоматически переходя в этом случае на использование "резервного" средства адресации —– Q-канала подкода. В противном случае, сессия, содержащая искаженный TOC, окажется недоступной для чтения даже на секторном уровне.
Таким образом, копирование дисков с искаженным TOC'ом осуществимо не на всяком оборудовании и порядка 1/3 моделей пишущих устройствприводов"писцов" для этих целей непригодны.
Узнать: поддерживает ли выбранная вами модель привода режим RAW DAO или нет можно в частности из раздела "Tech support" справочной системы по программеки Clone CDCloneCD, где перечислены характеристики достаточно большого количества всевозможных приводов (впрочем, моих приводов там уже увы нет). Другой путь –— "скормить" приводу SCSI/ATAPI команду 46h (GET CONFIGURATION) и посмотреть что он ответит. Из двух моих "пишущих приводовсцов" режим RAW DAO поддерживает один лишь NEC. С определением возможности чтения искаженных сессий дела обстоят на порядок сложнее, ибо данная особенность поведения является исключительно внутренней характеристикой привода и не афишируется ни самим приводом, ни его производителями. Приходится выяснять эту информацию экспериментально. Возьмите диск с искаженным TOC'ом (о том как его создать –— рассказано далее в этой главениже), вставьоткните его в привод и попробуйте прочесть несколько секторов из искаженной сессии. Реакция приводов может быть самой разнообразной. Тот же PHILIPS в зависимости от "настроения" своих электронных цепей, то рапортует об ошибке чтения, то возвращает совершенно бессмысленный "мусор", в котором не угадывается даже синхро-последовательность, возглавляющая заголовок "сырого" сектора.
Основной недостаток защитных механизмов с искаженным TOC'ом состоит в том, что некоторые приводы такие диски просто не "видят" и потому не могут их воспроизвести. Легальный пользователь, испытавший несовместимость защиты со своей аппаратурой, в лучшем случае обложит ее разработчика матом и поспешит вернуть диск продавцу…. если конечно, сможет вытащить эту "бяку" из недр CD-ROM'a'а, что вовсе не факт, поскольку микропроцессорная начинка некоторых приводов при попытке анализа искаженного TOC'a'а просто "зависает" и привод полностью абстрагируется от всех раздражителей внешнего мира, не реагируя в том числе и на настойчивые попытки пользователя получить обратно диск, нажатием на кнопкусделать диску "Eject".
Отверстие для аварийного выброса диска, правда, еще никто не отменял, но по слухам не везде оно есть (хотя лично мне такие приводыов без дырки еще не встречалосьвстречались), а там где есть –— зачастую оказывается скрытым за декоративной панелью или, – что более вероятно, – пользователь может вообще не знать, что это за отверстие такое, для чего оно предназначено и как им, собственно, следует пользоваться. Посмотрите внимательно на лицевую панель своего привода CD-ROM, видите, — внизу лотка расположено крохотное отверстие порядка 1 мм в диаметре? Воспользовавшись любым длинным, тонким и достаточно прочным предметом, например, металлической канцелярской скрепкой, слегка приоткройте лоток, введя "отмычку" в указанное отверстие до упора и еще чуть-чуть надавив. Все! — дальше лоток можно выдвинуть уже руками.
Внимание!
Во-первых проделывайте эту операцию только при выключенном компьютере, а, во-вторых, держите "отмычку" строго горизонтально, иначе вы можете промазать и угодить в какой ни будь нежный узел, основательно его повредив.
На "Макинтошах" (Macintosh) таких отверстий нет –— это точно (или же производители пользователи этих компьютеров плохого мнения о пользователяхвсе сплошь идиоты). Во всяком случае, количество судебных исков, поданных последними, в буквальном смысле слова не поддается ни разуму, ни исчислению. Самое интересное, что подавляющее большинство этих исков были удовлетворены и разработчикам пришлось оплатить и "ремонт" аппаратуры, и моральный ущерб, и, собственно сами, судебные издержки. (Между нами говоря, снятие защиты с дисков, записанных с грубыми нарушениями стандарта, коими в частности и являются диски с искаженным TOC, не считается взломом, и не преследуется по закону, поэтому: ломайте, ломайте и еще раз ломайте).
* Искажение TOC'а и его последствияФиктивный трек в настоящем треке
Не зная броду больше шансов утопиться
народная мудрость
Тот факт, что диски с данными адресуются исключительно на секторном уровне, дает большой простор для "извращений" с раскладкой треков, —– ни сам привод, ни операционная система не обращают на это обстоятельство ни малейшего внимания, но сбивает с толку подавляющее большинство копировщиков, включая копировщиков защищенных дисков, пытающихся скопировать диск именно по трекам, а не по секторам. Еще больший эффект дает размещение фиктивных треков в служебных областях, которые либо вовсе не могут быть скопированы приводом, либо завязаны на малоизвестных и редко используемых структурах, присутствие которых копировщики предпочитают не замечать. Но для начала разберемся как организованы стандартные треки и как все это хозяйство ухитряется работать.
По соображениям экономии места служебные структуры лазерных дисков содержат минимум необходимой информации и длина треков нигде явным образом не хранится. В грубом приближении она вычисляется путем вычитания стартового адреса текущего трека от стартового адреса следующего трека (стартового адреса выводной области диска —– если текущий трек в сессии последний). Сами же стартовые адреса хранятся в оглавлении диска (листинг 6.9), так называемом TOC'e (Table Of Contents).
Листинг 6.9. Пример содержимого оглавления диска в "сыром" виде с комментариями
session number
| ADR/control
| | TNO
| | | point
| | | | AM:AS:AF
| | | | | | | zero
| | | | | | | | PM:PS:PF
01 14 00 A0 00 00 00 00 01 00 00 ß номер первого трека первой сессии диска
01 14 00 A1 00 00 00 00 02 00 00 ß номер последнего трека первой сессии диска
01 14 00 A2 00 00 00 00 00 1D 21 ß адрес выводной области первой сессии диска
01 14 00 01
00 00 00 00 00 02 00 ß стартовый адрес трека N1
01 14 00 02
00 00 00 00 00 11 00 ß стартовый адрес трека N2
02 14 00 A0 00 00 00 00 03 00 00 ß номер первого трека второй сессии диска
02 14 00 A1 00 00 00 00 03 00 00 ß номер последнего трека второй сессии диска
02 14 00 A2 00 00 00 00 03 18 17 ß адрес выводной области второй сессии диска
02 14 00 03 00 00 00 00 03 01 21 ß стартовый адрес трека N3
Листинг 1 пример содержимого оглавления диска в сыром виде с комментариями
Между концом области Lead-inLead-In области и стартовым адресом первого трека каждой сессии расположена область пред-зазора иначе(так же называемая областью Pre-gap областью) протяженностью в 150 секторов, формально принадлежащая первому треку и по стандартам "Красной" и "Желтой" кКниг (базовые стандарты для аудиодисков и дисков с данными соответственно) не содержащая никаких полезных данных и на штампованных дисках CD-ROM дисках обычно заполненная нулями. Тип области пред-зазора совпадает с типом относящегося к ней трека и она сконструирована по его образу и подобию. А это значит, что для треков, записанных в MODE1, MODE2 FORM1 и MODE2 FORM2 область пред-зазора оказывается совсем не пустой. Как минимум она содержит корректные заголовки секторов, а как максимум —– заголовки секторов, контрольную сумму, корректирующие коды Рида-Соломона и прочую служебную информацию.
Листинг 6.10. Сектор из области Pre-gap аудио-трека (слева) и трека с данными (справа)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 FF FF FF FF FF FF FF FF FF FF 00 00 00 02 01
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
… ¦ …
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 69 A0 A7 82 CA 8A 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 CA 65 65 BC AF D9 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 A7 5B BD 72 88 0A 92 23 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ¦ 00 00 00 00 00 00 00 00 00 00 3D 90 90 48 AD D8
Листинг 2 сектор из pre-gap области аудио-трека (слева) и трека с данными (справа)
Между концом последнего трека и выводной областьюью каждой сессии расположена область постзазора иначе(так же называемая областью Post-gap областью) протяженностью от 150 и более секторов, формально принадлежащая последнему треку и аналогично области Pre-gap области не содержащая никаких данных. Тип области постзазора такой же, как и у предшествующего ей трека.
Если за треком одного типа следует трек другого типа (например, MODE1 сменяется на MODE2 или аудио-треки чередуются с треками данных), такие треки разделяются переходной областью (transition area) протяженностью по меньшей мере в 350 секторов.
Первые 150 секторов занимает область Post-gap область предшествующего трека, а остальные 200 секторов принадлежат расширенной (Extended) pre- gap области последующего трека. Расширенная область пред-зазора состоит из двух частей, занимающих по 50 и 150 секторов соответственно. Первые 50 секторов сохраняют тип предшествующего им трека, а оставшиеся 150 секторов представляют собой обычную область пред-зазора.
Треки данных идентичного типа могут располагаться как вплотную друг к другу, так и разделяться переходными областями. Однако, некоторые копировщики (в частности, Ahead Nero) ошибочно полагают, что переходные области между соседними треками присутствуют всегда и в порядке собственной инициативы пропускают последние ~350 секторов каждого трека. Поэтому, диски без переходных областей (или с укороченной переходной областью) такими копировщиками копируются некорректно, несмотря на свое полное соответствие стандарту.
Заметим, что выше здесь указаны лишь минимально допускаемые по стандарту размеры переходных областей, а их предельная длина практически ничем не ограничена. Размеры переходных областей нигде в явном виде не хранятся и для определения их границ необходимо проанализировать субканальные данные. Конкретно —– содержимое поля INDEX Q-канала подкода. Нулевое значение соответствует Pre-gap (или, применительно к аудиодискам —– паузе), любое другое —– действительному сектору трека или области Post-gap области. Таким образом, область постзазора ничем не отличается от предшествующего ей трека и копировщик не в состоянии определить ее длину и наличие Post-gap распознается лишь по косвенным признакам, – а именно по отсутствию информации в пользовательской части последних секторов трека. Грамотно спроектированный копировщик должен копировать содержимое всех сессий диска целиком —– от первого до последнего принадлежащего им сектора, не пытаясь анализировать раскладку треков, ибо она может быть произвольным образом искажена (адресация дисков с данными идет исключительно на секторном уровне и треки в ней не участвуют, а потому искажение их атрибутов вполне допустимо и не приводит ни к каким возмущениям со стороны операционной системы).
К сожалению, подавляющее большинство копировщиков (включая и копировщики защищенных дисков) негласно закалываются полагается на стандартные размеры переходных областей и крайне чувствительны к их искажениям. Обратите внимание (листинг 6.11), что второй трек начинается с адреса 465h, что соответствует абсолютному адресу 00:11h:00, приведенному в листинге 6.9 адрес начала Pre-gap, равный 3CFh, отстоит от стартового адреса трека ровно на 96h (150) секторов, следовательно, данная область Pre-gap полностью соответствует стандарту.
Листинг 6.11. Определение длины области Pre-gap по субканальным данным
++- номер трека
!! ++- index
03CC:00 15 00 0C 01 14 01 01 00 00 03 CC 00 00 03 CC
03CD:00 15 00 0C 01 14 01 01 00 00 03 CD 00 00 03 CD
03CE:00 15 00 0C 01 14 01 01 00 00 03 CE 00 00 03 CE ß конец post-gap первого трека
03CF:00 15 00 0C 01 14 02 00 00 00 03 CF 00 00 00 96 ß начало pre-gap второго трека
03D0:00 15 00 0C 01 14 02 00 00 00 03 D0 00 00 00 95
03D1:00 15 00 0C 01 14 02 00 00 00 03 D1 00 00 00 94
…
0462:00 15 00 0C 01 14 02 00 00 00 04 62 00 00 00 03
0463:00 15 00 0C 01 14 02 00 00 00 04 63 00 00 00 02
0464:00 15 00 0C 01 14 02 00 00 00 04 64 00 00 00 01 ß конец pre-gap второго трека
0465:00 15 00 0C 01 14 02 01 00 00 04 65 00 00 00 00 ß начало второго трека
0466:00 15 00 0C 01 14 02 01 00 00 04 66 00 00 00 01
0467:00 15 00 0C 01 14 02 01 00 00 04 67 00 00 00 02
Листинг 3 определение длины pre-gap области по субканальным данным, обратите внимание, что второй трек начинается с адреса 465h, что соответствует абсолютному адресу 00:11h:00, приведенному в листинге $-3. адрес начала pre-gap, равный 3CFh, отстоит от стартового адреса трека ровно на 96h (150) секторов, следовательно, данный pre-gap полностью соответствует Стандарту.
Однократно записываемые и перезаписываемые лазерные диски, используют Pre-gap для хранения такой экзотической и малоизвестной структуры данных как TDB (Track Descriptor Block —– блок описания трека), содержащей сведения о режиме записи, размере одного пакета и т. д.
Стандарт предписывает "прожигать" блок описания трека в режиме пакетной записи и режиме TAO (Track At Once —– по треку за раз), однако, большинство программ "прожига" (включая уже упомянутый Ahead Nero), "прожигают" TDB во всех доступных режимах записи, включая DAO. В листинге 6.12 представлен пример TDB с диска, прожженного Ahead Nero (диск записан в XA MODE2 FORM1, поэтому первый байт пользовательской области начинается со смещения 17h, а не 10h как это происходит в MODE1).
Листинг 6.12. Пример TDB с диска, "прожженного" Nero
000:00 FF FF FF FF FF FF FF FF FF FF 00 00 00 05 02 ¦O ; sector head
010:00 00 00 00 00 00 00 00 54 44 49 01 50 01 01 01 TDIOPOOO
; TDT-блок \
020:01 80 FF FF FF 00 00 00 00 00 00 00 00 00 00 00 OА ; TDU-блок / TDB
030:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
040:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
050:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
…
810:00 00 00 00 00 00 00 00 C3 0C 2E 82 00 00 00 00 ++.В ; к
820:00 00 00 00 00 00 00 00 93 78 85 F5 60 F5 F5 F5 УxЕї`їїї ; о
830:F5 0B AA AA AA 00 00 00 00 00 00 00 00 00 00 00 ї>ккк ; р Р
840:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ; р И
850:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ; к Д
860:00 00 00 00 00 00 00 00 00 00 00 00 00 00 58 14 X¶ ; т А
870:72 9B 00 00 00 00 00 00 00 00 00 00 00 00 C7 3C rЫ ¦< ; и
880:CC F4 30 F4 F4 F4 F4 8B 55 55 55 00 00 00 00 00 ¦Ї0ЇЇЇЇЛUUU ; р
890:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ; у С
8A0:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ; ю О
8B0:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ; щ Л
8C0:00 00 00 00 9B 18 5C 19 00 00 00 00 00 00 00 00 Ы^\v ; и О
8D0: 00 00 00 00 00 00 72 9B E5 94 71 47 E6 48 00 00 rЫхФqGцH ; е М
8E0:D1 00 F3 15 CC F5 2B 2C B1 AF F6 51 41 80 E0 F2 T є§¦ї+,-пЎQAАрЄ ; О
8F0:23 40 00 00 00 00 00 00 00 00 00 00 00 00 00 00 #@ ; к Н
900:00 00 00 00 00 00 00 00 00 00 5C 19 54 03 75 4A \vT¦uJ ; о А
910:7D 50 00 00 7B 00 0C BF 93 AB D5 AD 24 2E 42 51 }P { +¬Ул-н$.BQ ; д
920:4E 0D 6E CF 77 04 00 00 00 00 00 00 00 00 00 00 Ndn¦w¦ ; ы
Листинг 4 пример TDB с диска, прожженного Nero (диск записан в XA MODE2 FORM1, поэтому первый байт пользовательской области начинается со смещения 17h, а не 10h как это происходит в MODE1). дешифровка TDT: длина pre-gap 150 секторов, данный TDB относится только к первому треку, следом за TDT идет один-единственный TDU, описывающий текущий трек; дешифровка TDU: тип записи – непрерывная запись.
Блок описателя трека занимает один сектор, начинаясь с первого байта его пользовательской части, и дублируется во всех секторах второй половины Pre-gap данного трека. На структурном уровне он стоит из двух частей: таблицы описателя трека и одно или двух модулей описателей трека, сокращенно обозначаемых как TDT (Track Descriptor Table) и TDU (Track Descriptor Unit) соответственно. Дешифровка TDT в представленном листинге 6.12: длина Pre-gap 150 секторов, данный TDB относится только к первому треку, следом за блоком TDT идет один-единственный TDU, описывающий текущий трек; дешифровка TDU: тип записи — непрерывная запись.
Таблица описателя трека начинается со специальной сигнатуры: TDI (54h 44h 49h), что расшифровывается как Track Descriptor Identification (идентификатор описателя трека), следующие два байта хранят заявленную длину Pre-gap области, записанную в BCD-формате. Поле Type of Track Description Unit (табл. 6.1) указывает на количество модулей описания трека (сокращенно TDU от Track Description Unit), начинающихся непосредственно за концом блока TDB.
Единичное значение соответствует одному-единственному модулю, относящемуся к текущему треку. Нулевое значение указывает на наличие двух модулей, следующих друг за другом, первый из которых описывает атрибуты предшествующего трека, а текущий трек специфицируется вторым модулем.
Поля Lowest Track Number и Highest Track Number , записанные в BCD-формате, содержат наименьший и наибольший номера треков, описанных в данном TDB и используются главным образом в режиме пакетной записи для определения режимов предпочтительной записи. Во всех остальных случаях, следить за корректностью этих полей необязательно.
Первый байт модуля описателя трека содержит BCD-номер трека, который он, собственно, и описывает. Следующий за ним байт специфицирует метод записи и может принимать следующие значения:
q 00000000b — непрерывная запись (аудио-трек);
q 10010000b — непрерывная запись (всего лишь один пакет);
q 10010000b — инкрементная запись с пакетами переменной длины;
q 10010001b — инкрементная запись с пакетами фиксированной длины.
Поле Packet Size действительно только в режиме инкрементной записи пакетов постоянной длины – в этом случае оно содержит размер одного пакета, измеряемых в секторах. Иначе здесь должно находится FF FF FFh.
Таблица 6.1. Структура блока описателя трека с одним модулем описателя трека на конце
|
Байт |
Содержимое |
|
0 |
"T" |
|
1 |
"D" |
|
2 |
"I" |
|
3 |
Pre-gap length |
|
4 |
|
|
5 |
Type of Track Description Unit |
|
6 |
Lowest Track Number |
|
7 |
Highest Track Number |
|
8+00 |
Track Number |
|
8+01 |
Write Method of the Track |
|
8+02 |
Packet Size |
|
8+03 |
|
|
8+04 |
|
|
8+05 |
Reserved |
|
8+06 |
|
|
8+07 |
|
|
8+08 |
|
|
8+09 |
|
|
8+10 |
|
|
8+11 |
|
|
8+12 |
|
|
8+13 |
|
|
8+14 |
|
|
8+15 |
|
|
8+16 |
Большинство копировщиков защищенных дисков (и Alcohol 120%/Clone CD в том числе) в отношении переходных областей ведут себя чрезвычайно некорректно и никогда не копируют область Pre-gap первого трека, либо оставляя ее "непрожженной" (Alcohol 120%Алкоголь), либо забитой нулями (Clone CD). Последующие же переходные области копируются вполне нормально.
Все переходные области, за исключением Pre-gap первого трека первой сессии диска, свободно доступны на секторном уровне и не вызывают никаких проблем при чтении. Но область Pre-gap первого трека первой сессии — особенная. Поскольку, логический адрес первого значимого сектора диска принят за ноль (и это адрес первого сектора первого трека), то предшествующая ему область Pre-gap целиком лежит в отрицательных адресах. Это не вызывает никаких затруднений у команды READ CD MSF, принимающей в качестве аргументов абсолютные адреса, однако при использовании READ CD уже требуется совершенно иная система преобразования адресов (отрицательные LBA-адреса привод "в упор" не понимает). Она описана в стандарте, однако, разработчики копировщиков не всегда обращают на нее внимание, а может быть, им просто лень "топтать" кнопки? Кто знает… Но, как бы там ни было, первую область Pre-gap никто из них не читает, что позволяет нам использовать ее для хранения ключевой информации (на штампованных и дисках CD-R/RW) или же привязываться к конкретному TDB (на дисках CD-R/RW).
Сектор с адресом 00:00:00 (первый сектор Pre-gap) по стандарту читаться не обязан, т. к. у привода еще отсутствуют субканальные данные и он вынужден некоторое время заниматься их накоплением. На практике же, однако, штампованные и однократно записываемые диски CD-ROM/CD-R в зависимости от их качества и модели привода начинают читаться где-то со второго—десятого сектора, а до этого идут сплошные ошибки. С перезаписываемыми дисками ситуация обстоит намного хуже и они зачастую содержат нечитабельные сектора даже в середине области Pre-gap!
Таким образом, для защиты лазерного диска от несанкционированного копирования мы можем использовать следующие приемы:
q размещать соседние треки вплотную, без переходных областей (такой диск не копируется Ahead Nero, но копируется Алкоголем Alcohol 120% и Clone CDCloneCD);
q разместить в области Pre-gap первого трека диска ключевую информацию (такой диск копируется Ahead Nero, но не копируется ни Alcohol 120%Алкоголем, ни Clone CDCloneCD);
q создать фиктивный трек в подлинном треке или в переходной области подлинного трека (такой диск не копируется Ahead Nero, но копируется Clone CDCloneCD);
q разместить фиктивный трек в области Pre-gap первого трека (такой диск не копируется вообще ничем).
Добавление фиктивного трека приводит к искажению длины первого трека, т. к. теперь она вычисляется путем вычитания стартового адреса первого — подлинного — трека от стартового адреса второго — фиктивного — трека минус размер области Post-gap первого трека и Pre-gap второго (рис. 6.7). Допустим мы имеем диск с одним треком (рис. 6.7, а) и добавляем в TOC фиктивную запись о втором, реально несуществующем треке; как следствие этого длина первого трека уменьшается на sizeof(TRACK2) + sizeof(post-gap) + sizeof(pre-gap), причем между треком номер один и треком номер два образуется "дыра" в sizeof(post-gap) + sizeof(pre-gap) байт (рис. 6.7, б), которая штанными копировщиками не копируется! Поскольку, номера треков в адресации дисков с данными вообще не участвуют, операционной системе по-прежнему доступно все содержимое исходного трека, включая и области Pre-gap или Post-gap, образовавшиеся на границе настоящего и фиктивного треков. Другими словами, диск будет нормально читаться на любом оборудовании и под любой операционной системой, но скопировать его смогут лишь те копировщики, которые копируют содержимое Pre-gap и Post-gap, что по стандарту они делать не обязаны, т. к.
с официальной точки зрения эти области не содержат ничего интересного. Как следствие —– скопированный диск будет содержать "дыру" в 300 секторов, заполненных нулями. Такая "рана" способа угробить любой файл, а то и несколько файлов сразу!
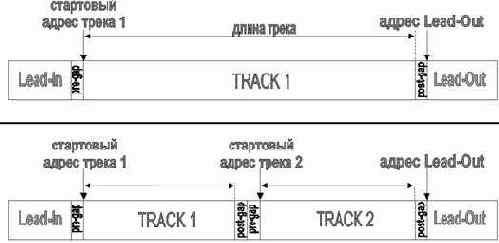
Рис. 6.7. унок 2 0x074 Длина трека определяется как разность стартовый адресов следующего трека и стартового адресам самого этого трека минус размер области Post-gap области . допустим мы имеем диск с одним треком (рисунок сверху) и добавляем в TOC фиктивную запись о втором, реально несуществующем треке; как следствие этого – длина первого трека уменьшается на sizeof(TRACK2) + sizeof(post-gap) + sizeof(pre-gap), причем между треком номер один и треком номер два образуется "дыра" в sizeof(post-gap) + sizeof(pre-gap) байт (рисунок снизу), которая штанными копировщиками не копируется!
Еще большие перспективы открывает создание фиктивных треков в буферных областях Post-gap и Pre-gap областях. Длина образовавшегося трека, вычисленная по алгоритму PreGap_len = min(&Lead-Out, &NexTrack - 150) - &MyTrack – 150$, становится резко отрицательной, дезориентируя такие копировщики как Ahead Nero, CDRWin, Blind Write и даже самого Alcohol 120%Алкоголя. Причем, если первые три копировщика дипломатично отказываются копировать защищенный диск, завершая свою работу вежливым сообщением об ошибке, то дезориентация Alcohol 120% Алкоголя сопровождается конкретным обрушением последнего.
А вот Clone CDCloneCD копирует такие диски вполне корректно! На первый взгляд, это полностью обессмысливает данный защитный механизм (действительно, кому нужна защита, копирующаяся хотя бы одним-единственным широко распространенным копировщиком?). Однако, не торопитесь выносить окончательное решение! Среди защитных механизмов существует и такие, что легко копируются Alcohol 120%Алкоголем, но жестоко "обламывают" Clone CDCloneCD.
Совмещение нескольких защитных механизмов на одном диске, равносильно объединению разрозненных штатов (княжеств) в единую державу, стойически сопротивляющуюся натиску злобных полчищ врагов. В этом свете, операцииизвращения с размещением фиктивных треков в областях Pre-gap и Post-gap областях становятся весьма перспективной и к тому же чрезвычайно неконфликтной технологией защиты, претендующей на широкое распространение. Достаточно заманчивые перспективы, не так ли?
Итак, задача-минимум: добавить в файл IMAGE.CCD еще один трек, соответствующим образом скорректировав все, связанные с ним поля. Эта, элементарная на первый взгляд миссия, на самом деле требует внесения в файл большого количества изменений. По меньшей мере должны быть проделаны следующие операции:
q количество TocEntries должно быть увеличено на единицу;
q поле PMin, принадлежащее указателю point'у'у 0A1h, также должно быть увеличено на единицу;
q необходимо добавить новый Entry с подложным треком (для простоты можно скопировать Entry подлинного трека, слегка изменив его стартовый адрес);
q номера всех последующих треков должны быть увеличены на единицу (т. е. все последующие указатели (point)'ы такие, что 64h > point > 00h, должны быть перенумерованы, при этом предполагается, что диск содержит менее 63h треков, т. к. максимальное количество треков жестко ограничено сверху);
q номера всех последующих Entry должны быть увеличены на единицу;
если на диске имеется больше, чем одна сессия, то номера треков и указатели point'ов A0h/A1h последующих сессий должны быть увеличены на единицу (указательpoint A0h первой сессии увеличивать ненужно);
q в карту треков должен быть добавлен фиктивный трек, а номера всех последующих треков перенумерованы.;
q за сим все.
Для пущей важности ( в смысле для лучшего соответствия стандарту) было бы нелишне скорректировать субканальные данные фиктивного трека, увеличив содержимое полей TNO (Track Number) каждого из них, на единицу. Эта информация содержаться в Q-канале подкода, который вместе со всеми остальными каналами находится в файле IMAGE.SUB. Каждый 0Dh + 60h * N байт файла содержит поле TNO -поле сектора N (строго говоря: жесткого соответствия между субканальными данными и секторами нет, поэтому эта формула весьма приблизительна). После внесения всех необходимых изменений, контрольная сумма каждой 16-байтовой субканальной секции должна быть пересчитана заново, в противном случае защищаемый диск перестанет работать. Для этой цели можно воспользоваться функцией CalcSubChannelCRC из динамической библиотеки newtrf.dll, входящей в состав прожигателя Ahead Nero.
Листинг 6.13. Пример секции субнанальных данных, выделенное полужирным шрифтом поле содержит номер текущего трека
0003060C: 41 02
01 00 00 06 00 03 ¦ 01 39 63 8A 00 00 00 00 AOO ¦ ¦O9cК
Листинг 5 пример секции субнанальных данных, выделенное жирным шрифтом поле содержит номер текущего трека
Если вам лень возиться с субканальными данными —– ничего не трогайте и оставьте все как есть —– в процессе чтения диска с данными номера треков никак реально не используются. Вот аудиодиски —– другое дело. Там поле TNO используется для индикации текущего воспроизводимого трека и (иногда) для переключения между треками.
С другой стороны, наличие некорректных полей TNO существенно усиливает защищенность диска, поскольку лишь немногие из копировщиков способны копировать субканальные данные, да и у тех эта опция по умолчанию отключена (у Clone CDCloneCD отключена точно).
Исторический аспект
Первые попытки защиты лазерных дисков от копирования
датируются началом девяностых годов XXвека. Пишущих приводов (далее по тексту "писцов") в то время еще не существовало и в основном приходилось бороться с не санкционированнымием копированиемпередираем
содержимого CD на жесткий диск. А как же пираты? –— спросите вы. Да, действительно, уровень пиратства в России всегда был и остается традиционно велик, но пытаться остановить его программными средствами защиты по меньшей мере наивно. Тот, кто копирует диски в промышленном масштабе, всегда держит при себе пару-тройку опытных хакеров, которые все
снимающих такие защиты снимают без труда. Интеллектуальный потенциал "отдела по снятию защит" в пиратских конторах практически неограничен, –— здесь работают лучшие из лучших (когда-то, до появления соответствующих законов, автор этой книги в таком "отряде" тоже состоял), и финансовый фактор тут, кстати говоря, вторичен. Платили немного, а "вкалывать" приходилось вона
всю, но в этом-то весь интерес и был! Где еще вы могли познакомиться с таким количеством разнообразных защит и приобрести навыки по их ликвидации?
Впрочем, насчет "количества" я немного "загнул". Все многообразие защитных механизмов тех дней сводилось к двум основным типам: LaserLock и "кодовое колесо" (подробности далеениже). С появлением пишущих приводовсцов
актуальность защит от копирования значительно возросла и они "поперли из земли, как грибы после дождя". К началу 2003 года на рынке насчитывалось более полусотни разнообразных методик защиты, большая часть из которых выдавалась за ноу-хау, разработавшей их фирмы. Однако, стоило пропустить защиту через дизассемблер, как вас отхватало щемящее чувство ностальгии по тем далеким, и казалось бы безвозвратно растворившимся в песке истории временам, когда программное обеспечение поставлялось на дискетах и каждая вторая из них оказывалась защищенной. Современный лазерный диск, конечно, непохож на дискеты десятилетней давности, но методики защиты тех и других по сути своей общие!
В современных защитных механизмах используются следующие методики:
q использование нестандартной разметки;,
q внедрение ключевых меток;,
q привязка к поверхности;
q "и слабые"
сектора.
Познакомимся со всем этим семейством поподробнее.
Нестандартная разметка диска в общем случае сводится к умышленному внесению тех или иных искажений, препятствующих нормальной обработке информации. Например, если длину каждого из защищенных файлов искусственно увеличить до ~666 Ггигабайт, просто скорректировав поле длины, то при попытке копирования таких файлов на винчестер произойдет грандиозный "облом-с". В тоже самое время защита, точно знающая от сих и до сих каждый файл,
можно читать, будет работать с ними без особых проблем. Разумеется, такой защитный механизм элементарно взламываетясхачится копированием диска на посектрном уровне, однако для этого копировщик должен знать какое именно количество секторов содержится на диске. Разработчику защиты ничего не стоит исказить служебные структуры диска так, чтобы тот либо представлялся совсем пустым, либо, напротив, разросся до неимоверных размеров слона. Копировщики, тупо читающие оглавление диска, и свято верящие каждому байту служебных данных, просто заключат[n2k5] дерябнуться по полной программе. Те же, кто "поумнее" сумеют определить истинный размер диска по косвенным признакам, двигая оптической головкой до тех пор, пока она еще двигается, а сектора, пролетающие над ней –—
читаются. Допустим защита решит схитрить и в непосредственной близости от конца диска "выроет яму" из множества сбойных секторов. Ага! –— подумают некоторые копировщики, после того как свалятьсясвалятся в нее. –—
Мы достигли конца! А вот и ни чего подобногофига! –—
воскликнут другие. Те, что тщательного
анализируют чувственную информацию, возращенную приводом, который-то наверняка знает в чем причина неудачного чтения –— то ли это диск кончился, то ли просто плохой сектор попался.
Другие защиты поступают еще хуже, нагло и самоуверенно записывая оригинальный диск с неустранимыми ошибками (неустанными –—
значит, не исправляемыми специальными корректирующими кодами, размещенными на CD). Для аудиодисков это означает, что проигрывание последнего будет сопровождаться ожесточенными щелчками. Точнее должно было бы сопровождаться, но на практике этого не происходит, поскольку разработчики аудио проигрывателей предусмотрели специальный фильтр, отбрасывающий заведомо искаженные данные и при необходимости прибегающий к интерполяции (ктогда текущая точка отсчета строится на основе усредненных значений предыдущей и последующей точек). Разумеется, это несколько ухудшает качество воспроизведения, но… медиамагнатам на это наплевать, да и ухудшение это не такое уж и значительное. С цифровым воспроизведением все обстоит иначе. Ранние версии Стандарта предписывали приводу сообщать лишь о факте возникновения одной или нескольких неустранимых ошибок, но не предусматривали никаких механизмов "маркировки" сбойных байт. Ну считал привод 2352 байта данных, ну убедился, что добрая сотня из них искажена… Что ему дальше-то делать? Интерполировать? Кого и с чем?! Вручную анализировать сигнал и искать "выхлесты"? Слишком сложно, да и качество "восстановленного" звука будет все равно не то… Можно, правда, отважиться "сграбить" аудио-поток с цифрового аудио-выхода, но подавляющее большинство дешевых звуковых карт его не поддерживает, а если и поддерживает, то так "криво", что лучше бы этого вообще не делализастрелись. Короче, над хакерами начали сгущаться мрачные тучи без следов присутствия лучика солнца. Но все изменилось, когда производители "выбросили" на рынок приводы, умеющие не только тупо сигнализировать об ошибке чтения, но и сообщающие позицию сбойных байт в секторе (прямо как в анекдоте: ты не мудри, ты пальцем покажи!). Теперь полноценная интерполяция стала возможна и на интерфейсом уровне! Немедленно появились и программы-грабители, использующие новые возможности.
Впрочем, мы сильно забежали вперед. В плане возращения к анналам перенесемся в те далекие времена, когда никаких оптических приводов еще и в проекте не существовало и все программное обеспечение распространялось исключительно на дискетах, стремительно утекающих как "налево", так и "направо" (собственно говоря, "copyright" именно так и переводится: "скопировано правильно"). Тогда все кому не лень активно "царапали"
дискеты всеми подручными предметами: кто побогаче —
прожигал магнитное покрытие лазером, кто победнее –— орудовал ржавым гвоздем. Защите оставалось лишь проверить присутствие дефекта поверхности в строго определенном месте. Скопировать такой диск без спецоборудования было практически нереально, т. к. даже Левша не смог бы перенести царапины оригинального диска на тоже самое место. Правда, хакеры, знающие порты контроллера как свои пять пальцев, быстро сообразили, что если исказить контрольную сумму ключевых секторов, тото,
не смотря на физическую целостность поверхности, диск будет читаться с ошибкой! Так вот, лазерные диски защищаются тем же самым способом! И абсолютно тем же самым способом они "ломаются"! Производитель может "нафаршировать" диск сбойными секторами словно рождественского гуся и при каждом запуске защищенногой программного обеспечениясофтины
проверять их присутствие. Это порождает следующие проблемы: во-первых, далеко не каждый всякий копировщик согласиться копировать дефективный диск, а если даже и согласитьсясогласится, то ждать завершения процесса копирования придется ну очень долго (все мы знаем с какой скоростью читаются дефективные сектора). Но полученная копия окажется все равно неработоспособной, поскольку на ней-то заданных дефектов уже не окажется –—
а это во-вторых.
ТупыеБездумные хакеры просто "убивают"грохают искажают контрольную сумму сектора, заставляя привод возвращать ошибку (естественно, пишущий привод должен позволять записать сектора с ошибкой контрольной суммы, на что согласитьсясогласится далеко не каждый).
Однако, это не решает проблемы –— ведь "гнутый" сектор читается мгновенно и защита, если она не совсем дура, может сообразить, что здесь что-то здесь не так! Или, как вариант, она может провести длинное чтение сектора и тогда сектор с искаженной контрольной суммой начнет читаться!
Как поступают умные хакеры? Ну… это так сразу и не объяснишь. Упрощенно говоря, формат лазерного диска таков, что высокочастотный сигнал, возникающий при чтении последовательности питов (pits) и лендов (lands), пролетающих над оптической головкой, не имеет опорного уровня и чтобы привод мог определить где здесь минус, а где плюс, количество лендов должно быть приблизительно равно количеству питов. О питах и лендах см. далее главу 1. Если какой-то участок сектора будет содержать одни питы, то он окажется катострофическикатастрофически темным и автоматический усилитель сигнала привода попытается увеличить мощность лазерного луча, ошибочно полагая, что с диском или оптикой не все в порядке. Но ведь тогда… часть питов превратиться в ленды и привод "обломается" по всем статьям. Сначала он свалитьсясвалится
в рекалибровку, поерзает оптической головкой… и лишь затем печально констатирует тот факт, что данный сектор не читается. С точки зрения защиты такой сектор будет выглядеть как глубоко дефектный, хотя на физическом уровне поверхность носителя останется и не повреждена.
Теперь самое главное: поскольку привод должен уметь записывать любые мыслимые и немыслимые данные, для преодоления подобных вот неблагоприятных ситуаций, разработчики должны были вынуждены предусмотреть специальный механизм их обхода. И такой механизм действительно есть! На пальцах: существует несколько возможных способов кодирования записываемых на диск данных и привод должен выбрать наиболее благоприятные из них. К счастью (или несчастью) не все приводы столь щепетильны. И поскольку, вероятность непредумышленного возникновения неблагоприятных последовательностей исчезающше мала, некоторые (между прочим, достаточно многие) приводы кодируют данные одним-единственным наперед заданным способом.
А значит, существует возможность сымитировать сбойные сектора, практически ничем не отличающиеся от настоящих.
Ага! Сказали разработчики защит! Да это же целый клад! Смотрите –— если подобрать специальную неблагоприятную последовательность байт, то для ее корректной записи понадобится специальный подойдет далеко не всякий привод! При копировании такого диска на обычном приводе, оригинал будет изумительно читаться, но копия обнаружит большое количество "бэдов", и… скопированный диск запускаться ни за что не будет. Сектора с неблагоприятными последовательностями внутри получили название "слабых" (weak) и для их копирования необходимы весьма высокотехнологичные и "навороченные" приводы от "крутых"
брэанд-неаймов (brand-name). А если такого привода у нас нет и он нам не по карману, тогда что –—
"кранты", да? А вот и нет! Если только защита не делает дополнительных поползновений, копировщик может рассчитать корректирующие коды для истинной неблагоприятной последовательности, а затем слегка выправить ее и записать на диск. На физическом уровне такой сектор будет читаться без каких либо проблем, ну а на логическом –— привод самостоятельно восстановит его по избыточным кодам в нормальный вид. Правда, если защита прочитает сектор в сыром виде, то она сразу же распознает подлог, так что таким способом копируются далеко не все диски.
Чтобы понять суть следующего защитного механизма, нам тоа же придется обратиться к дискетам. Как известно, поверхность дискеты физическим образом делиться на концентрические кольца, именуемые цилиндрамидорожками, а дорожкицилиндры
в свою очередь делятся на сектора. При перемещении головки от последнего сектора однойго
дорожкицилиндра
к первому сектору следующей дорожкиго, тот в силу вращения дискеты мотором, успевает пролететь и дисководу приходится ждать целый оборот, чтобы дождаться "свидания". Парни, денно и ночшно сидевшие в насквозь прокуренных вычислительных центрах, уже тогда додумались, что если провернуть сектора каждойго последующейго дорожки, а если имеется ввиду винчестер, то цилиндра[n2k6] , на некоторое расстояние, скорость последовательного чтения секторов существенно возраст, поскольку теперь нужный сектор сразу же окажется под головкой.
С другой стороны, проворачивая сектора различных цилиндров на различный угол, мы добьемся определенных колебаний скорости обмена, по которым оригинальный диск может быть легко отличен от копии, таких колебаний не содержащей.
Теперь перейдем к лазерным дискамов. Никаких цилиндров здесь и в помине нет и последовательность секторов скручена в тугую спирать. Позиционирование на сектора соседних витков дорожки осуществляется путем отклонения лазерной головки в магнитной системой (т. е. происходит практически мгновенно), а позиционирование на удаленные сектора вовлекает в движение механизм перемещения головки по специальным "ползункам" –— что требует значительного времени. Зная скорость вращения диска,
и, измеривзамеряв время позиционирования на сектора соседних витков дорожки, мы сможем найти угол между ним, напрямую зависящий от степени закрутки спирали. Различные партии CD-R/CD-RW дисков обладают различной структурой спирали и, что самое неприятное, эта структура закладывается непосредственно самим производителем –— т. е. диски поступают в продажу с предварительно выполненной разметкой, необходимой для ориентации записывающего привода на "местности". Скопировать защищенный таким образом диск нереально и приходится прибегать к его эмуляции. Копировщик должен тщательно измерять углы между различными секторами и воссоздать исходную структуру спирали. Процесс сканирования диска занимает чудовищное количество времени (поройд час
несколько суток), но результат того стоит.
Диск так же может иметь катастрофически нестандартный формат, –— например сектора переменной длины, в результате чего один из них будут читаться быстрее, другие медленнее. Поскольку, всякое изменение длины секторов немедленно отражается на структуре спиральной дорожи, копировщику приходится иметь дело с двумя неизвестными –—
неизвестным углом спиральной закрутки и неизвестной длиной секторов. С математической точки зрения это уравнение имеет множество возможных решений, но только одно из них правильное.
Копировщик может (и должен!) представить несколько вариантов копий, чтобы мы могли самостоятельно решить какая из них "ломает"
защиту, а какая нет. К сожалению, ни один из всех известных мне копировщиков этого не делает.
Впрочем, длинные сектора представляют собой вполне самостоятельную сущность и некоторые диски используют для своей защиты только их одних. Плохо то, что ни один из всех представленных на рынке пишущих приводоврезцов [n2k7] не позволяет управлять длиной записываемых секторов по нашему усмотрению. Правда, одна зацепка все же есть –— пусть мы не можем увеличить длину сектора, но мы в состоянии создать два сектора с идентичными заголовками –— приводпривод, успешно прочитав первый из двух секторов, второй просто проигнорирует, тем не менее, видимая длина сектора возрастет двое. Минус этой технологии состоит в том, что мы можем увеличить длину секторов лишь на величину кратную двум, да и то не на всех приводах. Некоторые из них писать спаренные сектора (они, кстати, называются twin-sectors) просто отказываются.
Теперь перейдем к ключевым меткам. Помимо пользовательской области сектора, которую исправно копируют практически все копировщики, на лазерных дисках существует множество мест, на которыех
"не ступала нога человека". Прежде всего это каналы подкода. Всего их восемь. Один хранит сервоинформацию, по которой лазерная головка ориентируется на местности, другой –—
информацию о паузах, остальные шесть каналов свободны и нормальные копировщики их не копируют, да и не всякие резцы
пишущие приводыдают дают возможность их записывать. Вот защиты с помощью сюда ключевыхе
метоки
сюда и внедряют![n2k8]
Кстати говоря, каналы подкода хранятся независимо от канала основных данных и прямого соответствия между ними нет. При чтении канала подхода сектора X, привод может вернуть субканальные данные любого из соседних секторов по своему усмотрению –— это раз. А теперь два –—
большинство приводов обладает крайне плохим постоянством и при последовательном чтении субканальных данных секторов X, Y и Z, нам могут возвратиться, например, данные X, X, X или Y, Z, X или Y, Z, Z или любая другая комбинация последних.
Допустим, канал подкода одного из секторов содержит ключевую метку. Допустим, мы пытаемся ее прочитать. Но прочитаем ли? А вот это как раз и не факт! Если сервоинформация окажется слегка искажена, мы вообще не сможем разобраться субканальные данные каких именно секторов мы прочитали и входит ли наш сектор в их перечень или нет. Единственный выход –— воспользоваться качественным читающим приводом, обладающим хорошим постоянством чтения субканальных данных.
И последнее. Записываемые и перезаписываемые диски по ряду характеристик значительно отличаются от штампованных CD-ROM. ATIP[Y9] [n2k10] [1]
представлять думаю нет необходимости? Еще существует такая вещь как TDB (Track Descriptor Block –—
блок описания трека), среди прочей информации сообщающий мощность лазера и иже с ней. На CD-ROM дисках, ничего подобного разумеется нет. Непосредственно подделать природу CD-ROM диска невозможно, но существует множество утилит, перехватывающих все обращения к приводу и возвращающих то, что "нужно", а не то, что есть на самом деле.
На этом нашуу кратнуюкраткую экскурсию "по зоопарку защитных механизмов" можно считать законченным. Затем, по мере углубления в книгу, каждый из этих эскпонатовэкспонатов
будет рассмотрен во всех подробностяхей.
…обход защиты от копирования совсем не тоже самое, что и нарушение авторских прав! Законы многих стран (в том числе и Российской федерации) явным образом разрешают создание резервных копий лицензионного носителя. В тоже самое время, нет такого закона, который бы запрещал "взлом" легально приобретенного экземпляра программы. Лицензионное соглашение вправе запрещать, что угодно, однако, статуса закона оно не имеет. Нарушая лицензионное соглашение вы автоматически разрываете договор с продавцом программы, а, значит, лишаетесь всех обещанных им льгот и гарантий. Приблизительно тоже самое происходит, когда вы путем замыкания таких-то ножек процессора разблокируете его тактовую частоту.Посадить вас не посадят, но и сожженный процессор (если он вдруг сгорит) вам не обменяют. С другой стороны, распространение взломанных программ уже попадает под статью и потому, лучше не рисковать.
Измерение угла между секторами
Услышав, что некоторые защитные механизмы измеряют угол между первым и последним логическим блоком на лазерном диске, я задумался: а как они, собственно, это делают? Поскольку, самих защищенных программ в моем распоряжении не было, а технические детали разработчиками защит умалчивались, пришлось заняться логическими рассуждениями и практическими экспериментами. Ценой пары пачек безнадежно загубленных болванок CD-R и суток свободного времени, фирменный секрет был раскрыт и создана вполне работоспособная защита от копирования. Но все по порядку.
Известно, что лазерные диски представляют собой устройство последовательного доступа с ускоренной переметкой, осуществляемой радиальным перемещением головки вдоль спиральной дорожки. Переместившись на некоторое расстояние, головка сама наводится на новую дорожку и дожидается прихода ближайшей синхропоследовательности, отмечающей начало каждого сектора. Прочитав, содержащийся в заголовке сектора адрес, головка сравнивает текущий адрес с искомым и, при необходимости, совершает еще одно перемещение вперед или назад. Этот процесс повторяется до тех пор, пока головка не приблизится к искомому сектору на достаточно близкое расстояние (в пределах одного оборота диска). Теперь головка прекращает суетиться и начинает спокойно ждать, пока сектор сам не приплывает в ее поле зрения.
Предположим, что поиск нужной дорожки всегда занимает одно и тоже время (хотя, это и не совсем так, но в качестве отправной точки рассуждений такое допущение вполне сойдет, поскольку позиционирование на сектора, находящиеся на соседних витках спирали, осуществляется путем отклонения головки в магнитом поле, т.е. происходит практически мгновенно, и только при позиционировании на удаленные сектора головка движется на "салазках" специальным приводным механизмом, работающим со скоростью черепахи). Тогда полное время доступа к сектору будет напрямую зависеть от угла между данным и последним прочитанным сектором (рис. 9.5). Соответственно, измерив время доступа, мы сможем вычислить угол.
Единственная проблема заключается в определении времени позиционирования головки. Поскольку оно сильно варьируется от привода к приводу, то закладываться на абсолютное время доступа нельзя. Однако, относительные изменения видны вполне отчетливо. Последовательно гоняя головку между сектором 0 и секторами X, X+1, X+2, X+3… мы будем наблюдать "волнообразные" колебания полного времени доступа. Гребень волны соответствует максимальному углу между этими секторами, а "впадина" — минимальному (в этом случае нужный сектор попадает в головку сразу же после завершения процесса позиционирования). Запомнив, какие сочетания секторов соответствуют минимуму, а какие — максимуму, попытаемся "натравить" эту комбинацию на дубликат диска.
Что, не получилось? Действительно, различные партии болванок CD-R отформатированы далеко не идентичным образом и плотность спиральной дорожки у них различна. А раз так, то различным оказывается и угол между нашими секторами, причем эти различия стремительно нарастают с удалением секторов друг от друга. Предположим, что средняя длина секторов оригинала и дубликата отличается на 0,01%. Тогда, при условии, что полная емкость диска составляет ~350 000 секторов, изменение угла между первым и последним сектором диска составят 3,5% — а это вполне измеряемая величина! Причем, на практике указанная точность разметки практически никогда не наблюдается и при копировании эталонного диска на болванки других производителей, "поворот" угла порой достигал 180 градусов, т. е. половины оборота диска!
Рис. 9.5. унок 27 0х02A Измерение угла между секторами
Запустив ее программу, измеряющую межсекторные углы [Y198] на выполнение и дав приводу CD-ROM вволю "прошуршать" головкой (собственно, по этому "шуршанию" алгоритм работы защиты и распознается), мы обнаружим, что время доступа к секторам с различными номерами изменяется весьма любопытным образом.
Четыре или пять соседних секторов читаются приблизительно с одинаковой скоростью, а затем кривая резко изгибается, изменяя время доступа чуть ли не вдвое! Однако, спустя один или несколько секторов, время доступа вновь скачкообразно изменяется. Чередование пиков и провалов обнаруживает достаточно строгую периодичность, отклоняющуюся от всего среднего положения всего на несколько секторов, что, судя по всему вызвано, непостоянством времени перемещения оптической головки. Естественно, чем сильнее "раздолбан" дисковод, тем с меньшей точностью удается определить период, однако, при большом количестве замеров величина погрешности окажется относительно невелика.
На рис. 9.6 приведены профили спиральных дорожек двух различных болванок. Темно-серая (на цветном рисунке красная) кривая соответствует болванке Imation, а черная (на цветном рисунке голубая) — болванке TDK. Обратите внимание, насколько отличается один график от другого!

Рис. 9.6. унок 28 0x031 Профиль спиральной дорожки диска Imation (темно-серая кривая) и TDK (черная кривая).
Как подключить дамп памяти
"…в отделе программ весь пол был усеян дырочками от перфокарт и какие-то мужики ползали по раскатанной по полу 20-метровой распечатке аварийного дампа памяти с целью обнаружения ошибки в распределителе памяти ОС-360. К президенту подошел начальник отдела и сообщил, что есть надежда сделать это еще к обеду"
Ю.Антонов "Юность Гейтса"
Дамп памяти (memory dump, также называемый "корой" [от английского core –— сердцевина], crash- или аварийным дампом), сброшенный системой при возникновении критической ошибки –— не самое убедительное средство для выявления причин катастрофы, но ничего другого в руках администратора зачастую просто не бывает. Последний вздох операционной системы, похожий на дурно пахнущую навозную кучу, из которой высовывается чей-то наполовину разложившийся труп, мгновенным снимком запечатленный в момент неустранимого сбоя –— вот что такое дамп памяти во время крушения системы! Копание в нем вряд ли доставит вам удовольствие. Не исключено, что истинного виновника краха системы вообще не удастся найти. Допустим, некий некорректно работающий драйвер вторгся в область памяти, принадлежащую другому драйверу, и наглым образом затер критические структуры данных, сделав из чисел "винегрет". К тому моменту, когда драйвер-жертва пойдет вразнос, драйвер-хищник может быть вообще выгружен из системы, и определить его причастность к крушению системы по одному лишь дампу практически нереально.
Тем не менее, полностью игнорировать факт существования дампа, право же, не стоит. В конце концов, до возникновения инактивных отладчиков ошибки в программах приходилось искать именно так. Избалованность современных программистов визуальными средствами анализа, увы, не добавляет им уверенности в тех ситуациях, когда неумолимая энтропия оставляет их со своими проблемами один на один. Но довольно лирики. Переходим к делу, расписывая каждое действие по шагам.
Первым делом, необходимо войти в конфигурацию системы Пуск à Настройка à Панель управления à Система
(Start à Settings à Control Panel à System) и убедиться, что настройки дампа соответствуют предъявляемым к ним требованиям Дополнительно à Загрузка и восстановление à Отказ системы (Startup/Shutdown à Recovery) в Windows 2000 RUS и Windows NT 4.0 ENG соответственно). Операционная система Windows 2000 поддерживает три разновидности дампов памяти: малый дамп памяти (small memory dump), дамп памяти ядра (kernel memory dump) и полный дамп памяти (complete dump memory). Для изменения настроек дампа вы должны иметь права администратора.
Малый дамп памяти занимает всего лишь 64 Кбайта (а отнюдь не 2 Мбайта, как утверждает контекстная помощь) и включает в себя:
q копию "голубого экрана смерти";
q перечень загруженных драйверов;
q контекст обрушившегося процесса со всеми его потоками;
q первые 16 Кбайт содержимого ядерного стека "обрушившегося" потока.
Разочаровывающие малоинформативные сведения! Непосредственный анализ дампа дает нам лишь адрес возникновения ошибки и имя драйвера, к которому этот адрес принадлежит. При условии, что конфигурация системы не была изменена после возникновения сбоя, мы можем загрузить отладчик и дизассемблировать подозреваемый драйвер, но это мало что даст. Ведь содержимое сегмента данных на момент возникновения сбоя нам неизвестно, более того —? мы не можем утверждать, что видим те же самые машинные команды, что вызвали сбой. Поэтому малый дамп памяти полезен лишь тем администраторам, которым достаточно одного лишь имени нестабильного драйвера. Как показывает практика, в подавляющем большинстве случаев этой информации оказывается вполне достаточно. Разработчикам драйвера отсылается гневный "бан-рапорт" (вместе с дампом!), а сам драйвер тем временем заменяется другим –— более новым и надежным.
По умолчанию малый дамп памяти записывается в каталог %SystemRoot%\Minidump, где ему присваивается имя Mini, дата записи дампа и порядковый номер сбоя на данный день. Например Mini110701-69.dmp –— 69 дамп системы от 07 ноября 2001 года (не пугайтесь! это просто я отлаживал драйвера).
Дамп памяти ядра содержит намного более полную информацию о сбое и включает в себя всю память, выделенную ядром и его компонентами (драйверами, уровнем абстракции от оборудования и т. д.), а также копию "голубого экрана смерти". Размер дампа памяти ядра зависит от количества установленных драйверов и варьируется от системы к системе. Контекстная помощь утверждает, что эта величина составляет от 50 до 800 Мбайт. Ну, на счет 800 Мбайт авторы явно "загнули", и объем в 50–—100 Мбайт выглядит более вероятным (техническая документация на систему сообщает, что ориентировочный размер дампа ядра составляет треть объема физической оперативной памяти, установленной на системе). Это наилучший компромисс между накладными расходами на дисковое пространство, скорости сброса дампа и информативностью последнего. Весь "джентльменский" минимум информации –— в вашем распоряжении. Практически все типовые ошибки драйверов и прочих ядерных компонентов могут быть локализованы с точностью до байта, включая и те, что вызваны физическим сбоем аппаратуры (правда, для этого вы должны иметь некоторый "патологоанатомический" опыт исследования "трупных" дампов системы). По умолчанию дамп памяти ядра записывается в файл %SystemRoot%\Memory.dmp, затирая или не затирая (в зависимости от текущих настроек системы) предыдущий дамп.
Полный дамп памяти включает в себя все содержимое физической памяти компьютера, занятое как прикладными, так и компонентами ядра системы. Полный дамп памяти оказывается особенно полезным при отладке ASPI/SPTI-приложений, которые в силу своей специфики могут "уронить" ядро даже с прикладного уровня.
Несмотря на довольно большой размер, равный размеру оперативной памяти, полный дамп остается наиболее любимым дампом всех системных программистов (системные же администраторы в своей массе предпочитают малый дамп). Это не покажется удивительным, если вспомнить, что объемы жестких дисков давно перевалили за отметку 100 Гбайт, а оплата труда системных программистов за последние несколько лет даже несколько возросла. Лучше иметь невостребованный полный дамп под рукой, чем кусать локти при его отсутствии. По умолчанию полный дамп памяти записывается в файл %SystemRoot%\Memory.dmp, затирая или не затирая (в зависимости от текущих настроек системы) предыдущий дамп.
Выбрав предпочтительный тип дампа, давайте совершим учебный "падение" системы, отрабатывая методику его анализа в "полевых" условиях. Для этого нам понадобится:
q комплект разработчика драйверов (Driver Development Kit или сокращенно DDK), бесплатно распространяемый фирмой Microsoft и содержащий в себе подробную техническую документацию по ядру системы; несколько компиляторов Си/Си++ и ассемблера, а также достаточно "продвинутые" средства анализа дампа памяти;
q драйвер W2K_KILL.SYS или любой другой драйвер-убийца операционной системы, например BDOS.EXE от Марка Русиновича, позволяющий получить дамп в любое удобное для нас время, не дожидаясь возникновения критической ошибки (бесплатную копию программы можно скачать с адреса http://www.sysinternals.com);
q файлы символьных идентификаторов (symbol files), необходимые отладчикам ядра для его нормального функционирования и делающие дизассемблерный код более наглядным. Файлы символьных идентификаторов входят в состав "зеленого" набора MSDN, но, в принципе, без них можно и обойтись, однако переменная окружения _NT_SYMBOL_PATH по любому должна быть определена, иначе отладчик i386kd.exe работать не будет;
q одна или несколько книжек, описывающих архитектуру ядра системы.
Очень хороша в этом смысле книга " Внутреннее устройство Windows 2000" Марка Руссиновича и Дэвида Соломона, интересная как системным программистам, так и администраторам.
Итак, установив DDK на свой компьютер и завершив все приложения, запускаем драйвер-убийцу и… под "скрипящий" звук записывающегося дампа, система немедленно выбрасывает "голубой экран смерти" (BSOD — Blue Screen Of Death), свидетельствующий о возникновении неустранимого сбоя системы с краткой информацией о нем, кратко информирующий нас о причинах сбоя (см. рис. 3.4 xx).
*** STOP: 0x0000001E (0xC0000005, 0xBE80B000, 0x00000000, 0x00000000)
KMODE_EXEPTION_NOT_HALTED
*** Address 0xBE80B000 base at 0xBE80A000, Date Stamp 389db915 – w2k_kill.sys
Beginning dump of physical memory
Dumping physical memory to disk: 69
Рис.унок 3.4. "Голубой экран смерти" (BSOD – Blue Screen Of Death), свидетельствующий о возникновении неустранимого сбоя системы с краткой информацией о нем
Для большинства администраторов "голубой экран смерти" означает лишь одно –— системе "поплохело" настолько, что она предпочла смерть позору неустойчивого функционирования. Что же до таинственных надписей, сопровождающих эти экраны, то они остаются сплошной загадкой. Но только не для настоящих профессионалов!
Мы начнем с левого верхнего угла экрана и, зигзагами спускаясь вниз, трассируем все надписи по порядку.
q *** STOP: — буквально означает "останов [системы]" и не несет в себе никакой дополнительной информации;
q 0x0000001E — представляет собой код Bug Check, содержащий категорию сбоя. Расшифровку кодов Bug Check можно найти в DDK. В данном случае это 0x1E –— KMODE_EXEPTION_NOT_HALTED, о чем и свидетельствует символьное имя расположенное строкой ниже. Краткое объяснение некоторых, наиболее популярных кодов Bug Check приведено в таблице 3.1.
Определение рейтинга популярности кодов Bug Check осуществлялось путем подсчета упоминаний о них в конференциях Интернет (спасибо старику Googl'у). Полноту фирменной документации она, разумеется, не заменяет, но некоторое представление о целесообразности скачивания 70 Мбайт DDK все-таки дает;
q "арабская вязь" в круглых скобках –— это четыре Bug Check-параметра, физический смысл которых зависит от конкретного кода Bug Check и вне его контекста теряет всякий смысл; применительно к KMODE_EXEPTION_NOT_HALTED –— первый Bug Check-параметр содержит номер возбужденного исключения. Судя по таблице 3.1, это –— STATUS_ACCESS_VIOLATION –— доступ к запрещенному адресу памяти –— и четвертый Bug Check-параметр указывает какой именно. В данном случае он равен нулю, следовательно, некоторая машинная инструкция попыталась совершить обращение по null-pointer, соответствующему инициализированному указателю, ссылающемуся на невыделенный регион памяти. Ее адрес содержится во втором Bug Check-параметре. Третий Bug Check-параметр в данном конкретном случае не определен;
q *** Address 0xBE80B00 –— это и есть тот адрес, по которому произошел сбой. В данном случае он идентичен второму Bug Check-параметру, однако так бывает далеко не всегда (коды Bug Check собственно и не подряжались хранить чьи-либо адреса).
q base at 0xBE80A00 –— содержит базовый адрес загрузки модуля-нарушителя системного порядка, по которому легко установить "паспортные" данные самого этого модуля.
Внимание!
Далеко не во всех случаях правильное определение базового адреса вообще возможно.
Воспользовавшись любым подходящим отладчиком (например, Soft-Ice от Нумега или i386kd от Microsoft), введем команду, распечатывающую перечень загруженных драйверов с их краткими характеристиками (в i386kd это осуществляется командой !drivers).
Как одним из вариантов, можно воспользоваться утилитой drivers.exe, входящей в NTDDK. но, какой бы вы путь не избрали, результат будет приблизительно следующим:
kd> !drivers!drivers
Loaded System Driver Summary
Base Code Size Data Size Driver Name Creation Time
80400000 142dc0 (1291 kb) 4d680 (309 kb) ntoskrnl.exe Wed Dec 08 02:41:11 1999
80062000 cc20 ( 51 kb) 32c0 ( 12 kb) hal.dll Wed Nov 03 04:14:22 1999
f4010000 1760 ( 5 kb) 1000 ( 4 kb) BOOTVID.DLL Thu Nov 04 04:24:33 1999
bffd8000 21ee0 ( 135 kb) 59a0 ( 22 kb) ACPI.sys Thu Nov 11 04:06:04 1999
be193000 16f60 ( 91 kb) ccc0 ( 51 kb) kmixer.sys Wed Nov 10 09:52:30 1999
bddb4000 355e0 ( 213 kb) 10ac0 ( 66 kb) ATMFD.DLL Fri Nov 12 06:48:40 1999
be80a000 200 ( 0 kb) a00 ( 2 kb) w2k_kill.sys Mon Aug 28 02:40:12 2000
TOTAL: 835ca0 (8407 kb) 326180 (3224 kb) ( 0 kb 0 kb)
Обратите внимание на выделенную полужирным черным цветом строку с именем w2k_kill.sys, найденную по ее базовому адресу 0xBE80A00. Это и есть тот самый драйвер, который нам нужен! А впрочем, этого можно и не делать, поскольку имя "неправильного" драйвера и без того присутствует на "голубом экране смерти";
q две нижние строки отражают прогресс "сброса" дампа на диск, развлекая администратора чередой быстро меняющихся циферок на это время.
Таблица 3.1. Физический смысл наиболее популярных кодов Bug Check с краткими пояснениями
|
Категория |
Описание |
|
|
hex-код |
Символьное имя |
|
|
0x0A |
IRQL_NOT_LESS_OR_EQUAL |
Драйвер попытался обратиться к странице памяти на уровне DISPATCH_LEVEL или более высоком, что и привело к краху, поскольку менеджер виртуальной памяти работает на более низком уровне; источником сбоя может быть и BIOS, и драйвер, и системный сервис (особенно этим грешат вирусные сканеры и FM-тюнеры); как вариант –— проверьте кабельные терминаторы на SCSI-накопителях и Master/Slayer на IDE, отключите кэширование памяти в BIOS; если и это не поможет, обратитесь к четырем параметрам кода Bug Check, содержащим ссылку на память, к которой осуществлялся доступ, уровень IRQ (Interrupt ReQuest), тип доступа (чтение/запись) и адрес машинной инструкции драйвера |
|
0x1E: |
KMODE_EXCEPTION_NOT_HANDLED |
Компонент ядра возбудил исключение и "забыл" его обработать; номер исключения содержится в первом Bug Check-параметре; обычно он принимает одно из следующих значений: 0x80000003 (STATUS_BREAKPOINT): встретилась программная точка останова –— отладочный рудимент, по небрежности не удаленный разработчиком драйвера; (0xC0000005) STATUS_ACCESS_ VIOLATION: доступ к запрещенному адресу (четвертый Bug Check-параметр уточняет к какому) –— ошибка разработчика; (0xC000021A) STATUS_SYSTEM_ PROCESS_TERMINATED: сбой процессов CSRSS и/или Winlogon, источником которого могут быть как компоненты ядра, так и пользовательские приложения; обычно это происходит при заражении машины вирусом или нарушении целостности системных файлов; (0xC0000221) STATUS_IMAGE_ CHECSUM_MISMATCH: целостность одного из системных файлов оказалась нарушена; второй Bug Check-параметр содержит адрес машинной команды, возбудившей исключение |
|
0x24 |
NTFS_FILE_SYSTEM |
Проблема с драйвером NTFS.SYS, обычно возникающая вследствие физического разрушения диска, реже –— при остром недостатке физической оперативной памяти |
|
0x2E |
DATA_BUS_ERROR |
Драйвер обратился по несуществующему физическому адресу; если только это не ошибка драйвера; оперативная память и/или кэш-память процессора (видеопамять) неисправны или же работают на запредельных тактовых частотах |
|
0x35 |
NO_MORE_IRP_STACK_LOCATIONS |
Драйвер более высокого уровня обратился к драйверу более низкого уровня посредством IoCallDriver-интерфейса, однако свободного пространства в стеке IRP (I/O Request Packet) не оказалось и передать весь IRP-пакет целиком не удалось; это гибельная ситуация, не имеющая прямых решений; попытайтесь удалить один или несколько наименее нужных драйверов, быть может тогда система заработает |
|
0x3F |
NO_MORE_SYSTEM_PTES |
Результат сильной фрагментации таблицы страниц PTE (Page Table Entry), приводящей к невозможности выделения затребованного драйвером блока памяти; обычно это характерно для аудио- или видеодрайверов, манипулирующих огромными блоками памяти и к тому же не всегда их вовремя освобождающих; для решения проблемы попробуйте увеличить количество PTE (до 50 000 максимум) в следующей ветке реестра: HLLM\SYSTEM\CurrentControlSet\ Control\SessionManager\ Memory Management\SystemPages |
|
0x50 |
PAGE_FAULT_IN_NONPAGED_AREA |
Обращение к несуществующей странице памяти, вызванное либо неисправностью оборудования (как правило –— оперативной, видео или кэш-памяти), либо некорректно спроектированным сервисом (этим грешат многие антивирусы, в том числе Касперский и Доктор Веб), либо разрушениями NTFS-тома (запустите программу chkdsk.exe с ключами /f и /r), также попробуйте запретить кэширование памяти в BIOS |
|
0x58 |
FTDISK_INTERNAL_ERROR |
Сбой RAID-массива, –— при попытке загрузки с основного диска система обнаружила, что он поврежден, тогда она обратилась к его зеркалу, но таблицы разделов не оказалось и там. |
|
0x76 |
PROCESS_HAS_LOCKED_PAGES |
Драйвер не смог освободить залоченные [Y94] [n2k95] страницы после завершения операции ввода-вывода; для определения имени дефективного драйвера следует обратиться к ветке HKLM\SYSTEM\CurrentControlSet\ Control\Session Manager\ Memory Management, и установить параметр TrackLockedPages типа DWORD в значение 1, потом перезагрузить систему, после чего та будет сохранять трассируемый стек и, если нехороший драйвер вновь начнет чудить, возникнет BSOD с кодом Bug Check: 0xCB, позволяющим определить виновника |
|
0x77 |
KERNEL_STACK_INPAGE_ERROR |
Страница данных памяти ядра по техническим причинам недоступна, если первый код Bug Check не равен нулю, то он может принимать одно из следующих значений: (0xC000009A) STATUS_INSUFFICIENT_RESOURCES –— недостаточно системных ресурсов; (0xC000009C) STATUS_DEVICE_DATA_ ERROR –— ошибка чтения с диска (bad-сектор?); (0xC000009D) STATUS_DEVICE_NOT_ CONNECTED –— система не видит привод (неисправность контроллера, плохой контакт шлейфа); (0xC000016A) STATUS_DISK_ OPERATION_FAILED –— ошибка чтения диска (bad-сектор или неисправный контроллер); (0xC0000185) STATUS_IO_DEVICE_ ERROR –— неправильное "термирование" SCSI-привода или конфликт IRQ IDE-приводов; нулевое же значение первого кода Bug Check указывает на неизвестную аппаратную проблему; такое сообщение может появляться и при заражении системы вирусами, и при разрушении диска старыми "докторами", и при отказе RAM –— войдите в консоль восстановления и запустите программу chkdsk.exe с ключом /r |
|
0x7A |
KERNEL_DATA_INPAGE_ERROR### |
Страница данных памяти ядра по техническим причинам недоступна, второй Bug Check-параметр содержит статус обмена, четвертый –— виртуальный страничный адрес, загрузить который не удалось; возможные причины сбоя — те же дефектные сектора, попавшие в файл-подкачки pagefile.sys, сбои дискового контроллера, ну и вирусы, наконец |
|
0x7B |
INACCESSIBLE_BOOT_DEVICE |
Загрузочное устройство недоступно, –— таблица разделов повреждена или не соответствует файлу boot.ini; также такое сообщение появляется при замене материнской платы с интегрированным IDE-контроллером (или замене SCSI-контроллера), поскольку всякий контроллер требует "своих" драйверов и при подключении жесткого диска с установленной Windows NT на компьютер, оснащенный несовместимым оборудованием, операционная система просто откажется грузиться и ее необходимо будет переустановить (опытные администраторы могут переустановить непосредственно сами дисковые драйвера, загрузившись с консоли восстановления); также не помешает проверить общую исправность оборудования и наличие вирусов на диске |
|
0x7F |
UNEXPECTED_KERNEL_MODE_TRAP |
Исключение процессора, необработанное операционной системой; обычно возникает вследствие неисправности оборудования (как правило –— разгона CPU), его несовместимости с установленными драйверами или алгоритмическими ошибками в самих драйверах; проверьте исправность оборудования и удалите все посторонние драйвера; первый Bug Check-параметр содержит номер исключения и может принимать следующие значения: 0x00 –— попытка деления на нуль; 0x01 –— исключение системного отладчика; 0x03 –— исключение точки останова; 0x04 –— переполнение; 0x05 –— генерируется инструкцией BOUND; 0x06 –— неверный опкод; 0x07 –— двойной отказ (Double Fault); описание остальных исключений содержится в документации на процессоры Intel и AMD |
|
0xC2 |
BAD_POOL_CALLER |
Текущий поток вызвал некорректный pool-request, что обычно происходит по причине алгоритмической ошибки, допущенной разработчиком драйвера; однако, судя по всему, и сама система не остается без ошибок, поскольку для устранения этого "голубого экрана смерти" Microsoft рекомендует установить SP2 |
|
0xCB |
DRIVER_LEFT_LOCKED_PAGES_IN_ PROCESS |
После завершения процедуры ввода/вывода, драйвер не может освободить заблокированные страницы (см. PROCESS_HAS_LOCKED_PAGES); первый Bug Check-параметр содержит вызываемый, а второй Bug Check-параметр, вызывающий адрес; последний, четвертый параметр указывает на UNICODE-строку с именем драйвера |
|
0xD1 |
DRIVER_IRQL_NOT_LESS_OR_EQUAL |
То же самое, что и IRQL_NOT_LESS_OR_EQUAL |
|
0xE2 |
MANUALLY_INITIATED_CRAS |
Сбой системы, спровоцированный вручную, путем нажатия "горячей" комбинации клавиш <Ctrl>+<Scroll Loock>, при условии, что параметр CrashOnCtrlScroll реестра HKLM\System\CurrentControlSet\ Services\i8042prt\Parameters содержит ненулевое значение |
|
0x7A |
KERNEL_DATA_INPAGE_ERROR |
Страница данных памяти ядра по техническим причинам недоступна, второй Bug Check-параметр содержит статус обмена, четвертый –— виртуальный страничный адрес, загрузить который не удалось; возможные причины сбоя — те же дефектные сектора, попавшие в файл pagefile.sys, сбои дискового контроллера, ну и вирусы, наконец |
Как восстановить не читающийся CD?
"bad sector не волк–— в лес не убежит"
народная мудрость
Лазерные диски –— не слишком-то надежные носители информации. Даже при бережном обращении с ними вы не застрахованы от появления царапин и загрязнения поверхности (порой диск "фрезерует" непосредственно сам привод и вы бессильны этому противостоять). Но даже вполне нормальный на вид диск может содержать внутренние дефекты, приводящие к его полной или частичной не читаемости на штатных приводах. Особенно это актуально для дисков CD-R/CD-RW дисков, качество изготовления которых все еще оставляет желать лучшего, а процесс записи сопряжен с появлением различного рода ошибок.
Однако даже при наличии физических разрушений поверхности лазерный диск может вполне нормально читаться за счет огромной избыточности хранящихся на нем данных, но затем, по мере разрастания дефектов, корректирующей способности кодов Рида-Соломона неожиданно перестает хватать и диск без всяких видимых причин отказывает читаться, а то и вовсе не опознается приводом.
К счастью, в подавляющем большинстве случаев хранимую на диске информацию все еще можно спасти и этота разделглава рассказывает как.
Каналы подкода
Среди прочей служебный информации во фреймовый кадр входит один байт субкода (sub-channel byte), так же иногда называемый байтом субканала или управляющим байтом (см.рис. 1.160х017). Субканальные данные полностью изолированы от содержимого сектора и в некотором роде ведут себя точно так же, как и множественные потоки данных в файловой системе NTFS (читайте "Основы Windows NT и NTFS" Хелен Кастер). Рисунок 0x016, уже разобранный нами выше, все это наглядно иллюстрирует.

Рис. 1.6. Организация субканальных данных
Субканальные данные полностью изолированы от содержимого сектора и в некотором роде ведут себя точно так же, как и множественные потоки данных в файловой системе NTFS (читайте "Основы Windows NT и NTFS" Хелен Кастер). Все это наглядно иллюстрирует рис. 1.7.
Рис. 1.7. Иерархия различных структур данных
Каждый из восьми битов, слагающих байт субкода, обозначается заглавной латинской буковой P, Q, R, S, T, U, V и W соотвественно. Одноименные биты субканальных байтов всех фреймов объединяются в так называемые каналы субдкода. Каналы состоят из секций, каждая из которых образуется путем объединения субканальных данных из 98 фреймов, что соответствует одному сектору (см. рис. 1.60x039). Однако, границы секций и секторов могут и не совпадать, поэтому для гарантированного извлечения одной секции с диска мы должны прочесть два сектора. Первые два байта секции задействованы для синхронизации, а 96 отданы под действительные данные. Путем несложных расчетов можно вычислить, что на каждый канал приходится ровно по 16 байт "сырых", еще не обработанных данных.
Данные каналов P и Q поступают в виде уже готовом к употреблению, причем значимыми из них являются только первые 12 байт, а остальные используются для выравнивания. Данные каналов P—-W перед употреблением должны быть специальным образом "приготовлены" (cook). 96 составляющих их 6-битных символов разбиваются на 4-группы, состоящие их 24 слов.
Каждое такая группа называется пакетом (pack) и включает в себя 16 символов пользовательских данных и 2 + 4 cимвола корректирующих кодов EDC/ECC.
Рисунок 7 0х039 Организация субканальных данных
Но что за информация хранится в каналах подкода? Согласно стандарту ECMA-130, "нормальные" компакт-диски задействуют лишь два канала: P и Q.
Канал P содержит в себе маркер окончания текущего трека (см. дорожка) и указатель на следующий трек, а канал Q используется для хранения сервоинформации, определяющий текущую позицию данного блока на диске, и является важнейшим каналом из всех.
Структурно канал Q состоит из следующих частей: четырех управляющих битов, соответствующих полю Control; четырех адресных битов, соответствующих полю q-Mode (ADR); 72-битов Q-данных, соответствующих полю q-Data и 16-битов контрольной суммы, соответствующих полю CRC (см. рис. 1.80x021).
Таблица 1.1. Формат данных Q-подканала
|
Байт |
Описание |
|
|
0 |
Control/ADR |
|
|
1 |
TNO (Track Number —– номер трека) |
|
|
2 |
INDEX (номер индекса) |
|
|
3 |
P-Min |
Положение головки относительно начала трека (относительный адрес) |
|
4 |
P-SEC |
|
|
5 |
PFrame[4][Y31] [n2k32] |
|
|
6 |
ZERO |
|
|
7 |
A-MIN |
Положение головки относительно начала диска (абсолютный адрес) |
|
8 |
A-SEC |
|
|
9 |
AFrame |
|
|
10 |
CRC |
|
|
11 |
||
|
12 |
Оставлено для выравнивания |
|
|
13 |
||
|
14 |
||
|
15 |
Кастрированный Урезанный Lead-outLead-Out
Другой популярный способ воспрепятствовать прослушиваю аудиодисков в компьютерных CD-приводах состоит в искажении содержимого TOC таким образом, чтобы указатель на область Lead-outLead-Out область указывал не на реальную областьый Lead-outLead-Out, а на гораздо более близкое к началу диска местоа. Подавляющее большинство бытовых аудио проигрывателей игнорирует значение этого поля (оно им действительно ни к чему), а вот компьютерные приводы CD-ROM при достижении фиктивнойго области Lead-outLead-Out ведут себя менее предсказуемо. Часть из них послушно прерывает воспроизведение в указанное в TOC'е время. Часть— – просто "зависает", тщетно пытаясь найти фиктивную областьый Lead-outLead-Out там, где еего и в помине нет (причем, это может случиться и до начала проигрывания диска, —– сразу же после загрузки диска в привод!). Правда, некоторые проводы приводы все-таки "догадываются" о том, что TOC предумышленно искажен (а, может, просто игнорируют его) и успешно обходят такую защиту, но закладываться на это я бы все- таки не стал.
Для создания защищенного диска нам потребуется любой обычный аудиодиск (который мы, собственно, и будет защищать) и какой- ни будь копировщик защищенных программ (например, Alcohol 120% или Clone CDCloneCD). Поддержка режима RAW DAO пишущим приводом необязательна.
Сняв образ защищаемого диска, откроем сформированный копировщиком CCD-файл и найдем в нем следующую текстовую строку "point=0xa2". Это и есть тот entry, который собственно и указывает на область Lead-outLead-Out область, чей абсолютный адрес хранится в полях PMin, PSec и PFrame, представляющих собой минуты, секунды и фреймы соответственно. Уменьшим абсолютный адрес до любого разумного времени (например, до 28 секунд) и не забыв сохранить изменения в файле, запишем отредактированный образ на диск CD-R/CD-RW диск. Дав записанному диску немного "остыть" (шутка!) извлечем его из привода и установим егозаснуем в бытовой аудио проигрыватель. С вероятностью близкой к единице защищенный диск должен воспроизводиться вполне нормально (однако, шансы нарваться на конфликт у вас все-таки есть). Теперь вернем "подопытного" обратно в компьютерный CD-ROM. Привод, едва начав воспроизведение, послушно прерывает проигрывание диска на 28-й'ой секунде.
На самом же деле такую защиту очень легко обойти. Сняв образ диска с помощью копировщика CloneCD, просто отредактируйте TOC, установив указатель Lead-outLead-Out на его законное положение. Для определения последнего достаточно вручную просмотреть содержимое Q-канала подкода в поисках трека поле TNO которого содержит значение 0xAA. Впрочем, копировщик CloneCD способен снимать такие защиты и самостоятельно.
Кодировщик (encoder)
Существует, по меньшей мере, два типа кодеров Рида-Соломона: несистематические и систематические
кодировщики.
Вычисление несистематических корректирующих кодов Рида-Соломона осуществляется умножением информационного слова на порожденный полином, в результате чего образуется кодовое слово, полностью отличающееся от исходного информационного слова, а потому для непосредственного употребления категорически непригодное. Для приведения полученных данных в исходный вид мы должны в обязательном порядке выполнить ресурсоемкую операцию декодирования, даже если данные не искажены и не требуют восстановления!
При систематическом кодировании, напротив, исходное информационное слово останется неизменным, а корректирующие коды (часто называемые символами четности) добавляются в его конец, благодаря чему к операции декодирования приходится прибегать лишь в случае действительного разрушения данных. Вычисление несистематических корректирующих кодов Рида-Соломона осуществляется делением
информационного слова на порожденный полином. При этом, все символы информационного слова сдвигаются на n– k байт влево, а на освободившееся место записывается 2t байт остатка (рис. 21.1).
Рис. 21.1. 0x335 Устройство кодового слова
Поскольку, рассмотрение обоих типов кодировщиков заняло бы слишком много места, сосредоточим свое внимание на одних лишь систематических кодерахкодировщиках, как на наиболее популярных.
Рис. 1.1. 0x335 устройство кодового слова
Архитектурно, кодировщик представляет собой совокупность сдвиговых регистров (shift registers), объединенных посредством сумматоров и умножителей, функционирующих по правилам арифметики Галуа. Сдвиговый регистр (иначе называемый регистром сдвига) представляет последовательность ячеек памяти, называемых разрядами, каждый из которых содержит один элемент поля Галуа GF(q). СодержащейсяСодержащийся в разряде символ, покидая этот разряд, поступает"выстреливается" на выходную линию.
Одновременно с этим, разряд фиксирует"засасывает" символ, находящийся на его входной линии. Замещение символов происходит дискретно, в строго определенные промежутки времени, называемые тактами.
При аппаратной реализации сдвигового регистра его элементы могут быть объедены как последовательно, так и параллельно. При последовательном объединении пересылка одного m-разрядного символа потребуетем m -тактов, в то время как при параллельном она осуществляется всего за один такт.
Низкая эффективность программных реализаций кодиеровщиков Рида-Соломона объясняется тем, что разработчик не может осуществлять параллельное объединение элементов сдвигового регистра и вынужден работать с той шириной разрядности, которую "навязывает" архитектура данной машины. Однако, создать 4-х элементный 8-битный регистр сдвига параллельного типа на процессорах семейства IA-32 вполне реально.
Примечание
IA-32 (Intel Architecture-32 bit) — общее обозначение 32-разрядной архитектуры процессоров корпорации Intel: i386, i486, Pentium, Pentium Pro, Pentium II и т. п.
Цепи, основанные на регистрах сдвига, обычно называют фильтрами. Блок-схема фильтра, осуществляющего деление полинома на константу, приведена на рис. 21.2. Пусть вас не смущает тот факт, что деление реализуется посредством умножения и сложения. Данный прием базируется на вычислении системы двух рекуррентных равенств с помощью формулы деления полинома на константу посредством умножения и сложения:
rx
rx (1.1)


Здесь: Q(r)(x) и R(r)(x) — соответственно, частное и остаток на r-шаге рекурсии. Поскольку сложение и вычисление, выполняемое по модулю два, тождественны друг другу, для реализации делителя нам достаточно иметь всего два устройства — устройство сложения и устройство умножения, а без устройства вычитания можно обойтись.
Рис. 2.2. Устройство простейшего кодировщика Рида-Соломона
После n-сдвигов на выходе регистра появляется частное, а в самом регистре окажется остаток, который и представляет собой рассчитанные символы четности (они же — коды Рида-Соломона), а коэффициенты умножения с g0 по g(2t – -1) напрямую соответствуют коэффициентам умножения порожденного полинома.
Рис. 1.2. 0x336 устройство простейшего кодера Рида-Соломона
Простейший пример программной реализации такого фильтра приведен в листинге 2.19ниже. Это законченный кодировщикера Рида-Соломона, вполне пригодный для практического использования. Конечно, при желании его можно было бы и улучшить, но тогда неизбежно пострадала бы наглядность и компактность листинга.
Листинг 21.19. Исходный текст простейшего кодиеровщикаа Рида-Соломона
/*----------------------------------------------------------------------------
*
* кодировщик Рида-Соломона
* ========================
*
* кодируемые данные передаются через массив data[i], где i=0..(k-1),
* а сгенерированные символы четности заносятся в массив b[0]..b[2*t-1].
* Исходные и результирующие данные должны быть представлены в полиномиальной
* форме (т. е. в обычной форме машинного представления данных).
* кодирование производится с использованием сдвигового feedback-регистра,
* заполненного соответствующими элементами массива g[] с порожденным
* полиномом внутри, процедура генерации которого уже обсуждалась в
* предыдущей главе.
* сгенерированное кодовое слово описывается следующей формулой:
* с(x) = data(x)*x^(n-k) + b(x), где ^ означает возведение в степень
*
* на основе исходных текстов
* Simon'а Rockliff'а, от 26.06.1991
* распространяемых по лицензии GNU
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––-*/
encode_rs()
{
int i, j;
int feedback;
// инициализируем поле бит четности нулями
for (i = 0; i < n - k; i++) b[i] = 0;
// обрабатываем все символы
// исходных данных справа налево
for (i = k - 1; i >= 0; i--)
{
// готовим (data[i] + b[n – k –1]) к умножению на g[i]
// т. е.
складываем очередной "захваченный" символ исходных
// данных с младшим символом битов четности (соответствующего
// "регистру" b2t-1, см. рис. 2.2[Y70] ) и переводим его в индексную
// форму, сохраняя результат в регистре feedback
// как мы уже говорили, сумма двух индексов есть произведение
// полиномов
feedback = index_of[data[i] ^ b[n – k - 1]];
// есть еще символы для обработки?
if (feedback != -1)
{
// осуществляем сдвиг цепи bx-регистров
for (j=n-k-1; j>0; j--)
// если текущий коэффициент g – это действительный
// (т.е. ненулевой коэффициент, то
// умножаем feedback на соответствующий g-коэффициент
// и складываем его со следующим элементов цепочки
if (g[j]!=-1) b[j]=b[j-1]^alpha_to[(g[j]+feedback)%n];
else
// если текущий коэффициент g – это нулевой коэффициент,
// выполняем один лишь сдвиг без умножения, перемещая
// символ из одного m-регистра в другой
b[j] = b[j-1];
// закольцовываем выходящий символ в крайний левый b0-регистр
b[0] = alpha_to[(g[0]+feedback)%n];
}
else
{ // деление завершено,
// осуществляем последний сдвиг регистра,
// на выходе регистра будет частое, которое теряется,
// а в самом регистре – искомый остаток
for (j = n-k-1; j>0; j--) b[j] = b[j-1] ; b[0] = 0;
}
}
}
Коды Рида-Соломона в практических реализациях
В предыдущих разделахглавах мы рассмотрели базовый математический аппарат, на который опираются коды Рида-Соломона, и исследовали простейший кодер/декодер, способный исправлять одиночные ошибки и работающий с двумя символами четности. Для подавляющего большинства задач такой корректирующей способности оказывается катастрофически недостаточно, и тогда приходится задумываетсязадумываться о реализации более мощного кодера/декодера.
Кодер/декодер, рассматриваемый в настоящей главе, достаточно легкочрезвычайно конфигурируетсяабелен и может быть настроен на работу с любымх количеством символов четности, а это обозначает, что при разумной избыточности он способен исправлять любое мыслимое количество ошибок. Подобная универсальность не проходит даромдаром, и конструкция такого декодера усложнятся более чем в сто(!) раз. Самостоятельное проектирование декодеров Рида-Соломона требует глубоких знаний высшей математики в целом и природы корректирующих кодов в частности, поэтому не смущайтесь, если данная глава поначалу вам покажется непонятной. Это действительно сложные вещи, не допускающие простого объяснения.
С другой стороны, для практического использования корректирующих кодов можно и не вникать в их сущность, просто откомпилировав исходные тексты кодера/декодера Рида-Соломона, приведенные в данной главе. Так же вы можете воспользоваться любой законченной библиотекой, поставляемой сторонними разработчикам. В качестве альтернативного примера в заключении этой главы будет краткно описан интерфейс библиотеки ElByECC.DLL, разработанной компанией "Elaborate Bytes" и распространяемой вместе с популярным копировщиком Clone CD. Известнейший "прожигатель" дисков всех времен и народов Ahead Nero Burning ROM имеет аналогичную библиотеку, размешенную в файле NEWTRF.DLL.
Корни полинома
Коль скоро полином локатора ошибки нам известен, то его корни определяют местоположение искаженных символов в принятом кодовом слове. Остается эти корни найти. Чаще всего для этого используется процедура Ченя (Chien search), аналогичная по своей природе обратному преобразованию Фурье и фактически сводящаяся к тупому перебору (brute force, exhaustive search) всех возможных вариантов. Все 2m
возможных символов один за другим подставляются в полином локатора в порядке "социалистической" очереди и затем выполняется расчет полинома. Если результат обращается в ноль, то— считается, что искомые корни найдены.
Корректирующие коды и помехоустойчивое кодирование (азы)
Персональные компьютеры с их битами и байтами настолько прочно вошли в нашу жизнь, что программисты вообще перестали задумываться о теории кодирования информации, принимая ее как должное. Между тем, здесь все не так просто, как может показаться на первый взгляд.
Фактически, кодирование есть ни что иное, как преобразование сообщения в последовательность кодовых символов так же называемых кодовыми словами. Любое дискретное сообщение состоит из конечного числа элементов: в частности, текст состоит из букв, изображение состоит из пикселей, машинная программа состоит из команд и т. д., — все они образуют алфавит источника сообщения. При кодировании происходит преобразование элементов сообщения в соответствующие им числа — кодовые символы, причем каждому элементу сообщения присваивается уникальная совокупность кодовых символов, называемая кодовой комбинацией. Совокупность кодовых комбинаций, образующих сообщение, и есть код. Множество возможных кодовых символов называется кодовым алфавитом, а их количество (далее по тексту обозначаемое малой латинской m) — основанием кода.
Впрочем, все это вы уже наверняка знаете (а если не знаете, — то без труда найдете исчерпывающее объяснение основ кодирования в любом учебнике по информатике), но знаете ли вы, что такое расстояние Хемминга? Это — минимальное количество различий между двумя различными допустимыми кодовыми словами
и в теории помехоустойчивого кодирования расстояние Хемминга играет основополагающую роль. Рассмотрим, например, следующий четырех битный код (листинг 21.1).:
Листинг 21.1. Пример простейшего четырех битного кода с расстоянием Хемминга, равныом единице.
0 à 0000; 4 à 0100; 8 à 1000; 12 à 1100;
1 à 0001; 5 à 0101; 9 à 1001; 13 à 1101;
2 à 0010; 6 à 0110; 10 à 1010; 14 à 1110;
3 à 0011; 7 à 0111; 11 à 1011; 15 à 1111;
Такой код широко используется в вычислительной технике, несмотря на его невозможность обнаружить ошибки.
Это обыкновенный двоичный код, который можно встретить в некоторых "однокристалках", вмещающий в свои 4 бита 16 символов (т. е. с его помощью можно закодировать 16 букв алфавита). Как нетрудно убедиться, что два любых символа этого кода отличаются, по меньшей мере, на один бит, следовательно, расстояние Хемминга для такого кода равно единице (что условно обозначает как
d = 1).
А вот другой четырех битный код с расстоянием Хемминга, равным двум, способный обнаруживать одиночные ошибки (листинг 21.2).:
Листинг 21.2. Пример четырех битного кода с расстоянием Хемминга, равныом двум, способный обнаруживать одиночные ошибки.
0 à 0000; 4 à 1001;
1 à 0011; 5 à 1010;
2 à 0101; 6 à 1100;
3 à 0110; 7 à 1111;
На этот раз, два произвольных символа отличаются как минимум в двух позициях, за счет чего информационная емкость такого кода сократилась с 16- до 8 символов. Постойте-постойте! — воскликнет иной читатель. — Что это за бред? Куда девалась комбинация 0001 или 0010 например? Нет, это не бред и указанных комбинаций бит в данном коде действительно нет, точнее они есть, но объявлены запрещенными. Благодаря этому обстоятельству наш подопечный код способен обнаруживать любые одиночные ошибки. Возьмем, например, символ "1010" и исказим в нем произвольный бит (но только один!). Пусть это будет второй слева бит, — тогда искаженный символ станет выглядеть так: "1110". Поскольку, комбинация "1110" является запрещенной, декодер может засвидетельствовать наличие ошибки. Увы, только засвидетельствовать, но не исправить, т. к. для исправления даже одного-единственного сбойного байта требуются увеличить расстояние Хемминга как минимум до трех. Поскольку, 4-?битный код с d = 3 способен вмещать в себя лишь два различных символа, то он крайне ненагляден, и потому нам лучше выбрать код с большей разрядностью.
Хорошо, пусть это будет 10-битный код с d = 5 (листинг 21.3).
Листинг 21.3. Пример 10-битного кода, с расстоянием Хемминга равныом пяти, способного обнаруживать четырех битные ошибки, а исправлять — двух битовыедвух битовые.
0000000000 0000011111 1111100000 1111111111
Возьмем, к примерупримеру, символ "0000011111" и изменимискорежим два его любых бита, получив в итоге что-то наподобие: "0100110111". Поскольку, такая комбинация является запрещенной, декодер понимает, что произошла ошибка. Достаточно очевидно, что если количество сбойных бит меньше расстояния Хемминга хотя бы наполовину, то декодер может гарантированно восстановить исходный символ. Действительно, если между двумя любыми разрешенными символами существует не менее пяти различий, то искажение двух бит всякого такого символа приведет к образованию нового символа (обозначим его k), причем расстояние Хемминга между k и оригинальным символом равно числу непосредственно искаженных бит (т. е. в нашем случае двум), а расстояние до ближайшего соседнего символа равно: d – k (т. е. в нашем случае трем). Другими словами, пока d – k > k
декодер может гарантированно восстановить искаженный символ. В тех случаях, когда d > k > d – k, успешное восстановление уже не гарантируется, но при удачном стечении обстоятельств все-таки оказывается в принципе возможным.
Возвращаясь к нашему символу "0000011111," давайте на этот раз исказим не два бита, а четыре: "0100110101" и попробуем его восстановить. Изобразим процесс восстановления графически (листинг 21.4).:
Листинг 21.4. Восстановление четырех битной ошибки
0000000000 0000011111 1111100000 1111111111
0100110101 0100110101 0100110101 0100110101
---------- ---------- ---------- ----------
5 отличий 4 отличия 6 отличий 5 отличий
Грубо говоря, обнаружив ошибку, декодер последовательно сличает искаженный символ со всеми разрешенными символами алфавита, стремясь найти символ наиболее "похожий" на искаженный. Точнее — символ с наименьшим числом различий, а еще точнее — символ, отличающийся от искаженного не более чем в (d – 1) позициях. Легко увидеть, что в данном случае нам повезло и восстановленный символ совпал с истинным. Однако, если бы четыре искаженных бита распределились бы так: "0111111111", то декодер принял бы этот символ за "1111111111" и восстановление оказалось бы неверным.
Таким образом, исправляющая способность кода определяется по следующей формуле: для обнаружения r ошибок расстояние Хемминга должно быть больше или равно r, а для коррекции r ошибок, расстояние Хемминга должно быть, по крайней мере, на единицу больше удвоенного количества r (листинг 21.5).
Листинг 21.5. Корректирующие способности простого кода Хемминга
обнаружение ошибок: d
>= r
исправление ошибок: d
> 2r
информационная емкость: 2n/d
Теоретически количество обнаруживаемых ошибок неограниченно, практически же информационная емкость кодовых слов стремительно тает с ростом d. Допустим, у нас есть 24 байта данных, и мы хотели бы исправлять до двух ошибок на каждый такой блок. Тогда нам придется добавить к этому блоку еще 49 байт, в результате чего реальная информационная емкость блока сократиться всего… до 30%! Хорошенькая перспективаперспектива, не так ли? Столь плачевный результат объясняется тем, что биты кодового слова изолированы друг от друга и изменение одного из них никак не сказывается на окружающих. А что если…
Пусть все биты, номера которых есть степень двойки, станут играть роль контрольных битов, а оставшиеся и будут обычными ("информационными") битами сообщения. Каждый контрольный бит должен отвечать за четность суммы (т. е.
если сумма проверяемых бит — четна, то контрольный бит будет равен нулю и, соответственно, наоборот) некоторой, принадлежащей ему группы битов, причем один и тот же информационный бит может относиться к различным группам. Тогда, один информационный бит сможет влияет на несколько контрольных и потому информационная емкость слова значительно (можно даже сказать чудовищно) возрастет. Остается только выбрать наиболее оптимальное разделение сфер влияния.
Согласно методу помехозащитного кодирования, предложенного Хеммингом, для того, чтобы определить какие контрольные биты контролируют информационный бит, стоящий в позиции k, мы должны разложить k
по степеням двойки, как это показано в таблице 21.1.:
Таблица 21.1. Разделение бит на контрольные и информационные
|
Позиция |
Какими битами контролируется |
|
|
1 (A) |
20 = 1 |
Это контрольный бит, никто его не контролирует |
|
2 (B) |
21 = 2 |
Это контрольный бит, никто его не контролирует |
|
3 |
20+21 = 1 + 2 = 3 |
Контролируется 1 и 2 контрольными битами |
|
4 (C) |
22 = 4 |
Это контрольный бит, никто его не контролирует |
|
5 |
20+22 = 1 + 4 = 5 |
Контролируется 1 и 4 контрольными битами |
|
6 |
21+22 = 2 + 4 = 6 |
Контролируется 2 и 4 контрольными битами |
|
7 |
20+21+22 = 1 + 2 + 4 = 7 |
Контролируется 1, 2 и 4 контрольными битами |
|
8 (D) |
23 = 8 |
Это контрольный бит, никто его не контролирует |
q Бит A, контролирующий биты 3, 5 и 7 равен нулю, т. к. их сумма (0 + 1 + 1) четна.
q Бит B, контролирующий биты 3, 6 и 7 равен единицеодному, т. к.
их сумма (0 + 0 + 1) нечетна.
q Бит C, контролирующий биты 5, 6 и 7 равен нулю, т. к. их сумма (1 + 0 + 1) четна.
Таким образом, "новоиспеченное" кодовое слово будет выглядеть так: "0100101", где жирным шрифтом выделены контрольные биты (листинг 21.6).
Листинг 21.6. Кодовое слово вместе с информационными битами
AB0C101
1234567
Допустим, при передаче наше слово было искажено в одной позиции и стало выглядеть так: 0100111. Сможем ли мы обнаружить такую ошибку? А вот сейчас и проверим! Так, бит A должен быть равен: (0 + 1 + 1) % 2 = 0, что соответствует истине. Бит B должен быть равен (0 + 1 + 1) % 2 = 0, а в нашем слове он равен единице. Запомним номер "неправильного" контрольного бита и продолжим. Бит C должен быть равен (1 + 1 + 1) % 2 = 1, а он равен нулю! Ага, значит, контрольные биты в позициях 2 (бит B) и 4 (бит C) обнаруживают расхождение с действительностью. Их сумма (2 + 4 = 6) и дает позицию сбойного бита. Действительно, в данном случае номер искаженного бита будет равен 6, — инвертируем его, тем самым, восстанавливая наше кодовое слово в исходный вид.
А что, если искажение затронет не информационный, а контрольный бит? Проверка показывает, что позиция ошибки успешно обнаруживается и в этом случае и контрольный бит при желании может быть легко восстановлен по методике уже описанной выше (только если ли в этом смысл? ведь контрольные биты все равно выкусываются в процессе декодирования кодового слова).
На первый взгляд кажется, что коды Хемминга жутко неэффективны, ведь на 4 информационных бита у нас приходится 3 контрольных, однако, поскольку номера контрольных бит представляют собой степень двойки, то с ростом разрядности кодового слова они начинают располагаться все реже и реже.
Так, ближайший к биту C контрольный бит D находится в позиции 8 (т . е. в "трех шагах"), зато контрольный бит E отделен от бита D уже на 24 – 23 – 1 = 7 "шагов", а контрольный бит F и вовсе — на – 25 – 24 – 1 = 15 "шагов".
Таким образом, с увеличением разрядности обрабатываемого блока, эффективность кодов Хемминга стремительно нарастает, что и показывает следующая программа (листинг 21.7) и результаты расчетов, выполненные с ее помощью (листинг 21.8).:
Листинг 21.7. Расчет эффективной информационной емкости кодов Хемминга для слов различной длины
main()
{
int a;
int _pow = 1;
int old_pow = 1;
int N, old_N = 1;
printf( "* * * hamming code efficiency test * * * by Kris Kaspersky\n"\
" BLOCK_SIZE FUEL UP EFFICIENCY\n"\
"-----------------------------------\n");
for (a = 0; a < MAX_POW; a++)
{
N = _pow - old_pow - 1 + old_N;
printf("%8d %8d %8.1f%%\n",_pow, N, (float) N/_pow*100);
// NEXT
old_pow = _pow; _pow = _pow * 2; old_N = N;
} printf("-----------------------------------\n");
}
Листинг 21.888. Результат расчета эффективной информационной емкости кодов Хемминга для слов различной длины
BLOCK_SIZE FUEL UP EFFICIENCY
-----------------------------------
1 0 0.0%
2 0 0.0%
4 1 25.0%
8 4 50.0%
16 11 68.8%
32 26 81.3%
64 57 89.1%
128 120 93.8%
256 247 96.5%
512 502 98.0%
1024 1013 98.9%
2048 2036 99.4%
4096 4083 99.7%
8192 8178 99.8%
16384 16369 99.9%
32768 32752 100.0%
65536 65519 100.0%
131072 131054 100.0%
262144 262125 100.0%
524288 524268 100.0%
-----------------------------------
Из приведенной выше распечатки (см. листинг 21.8) видно, что при обработке блоков, "дотягивающихся" хотя бы до 1024 бит, накладными расходами на контрольные биты можно полностью пренебречь.
К сожалению, коды Хемминга способны исправлять лишь одиночные ошибки, т. е. допускают искажение всего лишь одного сбойного бита на весь обрабатываемый блок. Естественно, с ростом размеров обрабатываемых блоков увеличивается и вероятность ошибок. Поэтому, выбор оптимальной длины кодового слова является весьма нетривиальной задачей, как минимум требующей знания характера и частоты возникновения ошибок используемых каналов передачи информации. В частности, для ленточных накопителей, лазерных дисков, винчестеров и тому подобных устройств, коды Хемминга оказываются чрезвычайно неэффективными. Зачем же тогда мы их рассматривали? А затем, что понять прогрессивные системы кодирования (к которым в том числе относятся и коды Рида-Соломона), ринувшись атаковать их "с нуля", практически невозможно, ибо они завязаны на сложной, действительно высшей математике, но ведь не Боги горшки обжигают, верно?
Кратко о питахPit'ы, лендland'ахы, EFM-словаха, фреймовыхе кадрахы и секторах (кратко)
Вопреки распространенному заблуждению питы (pits)pit'ы и ленды (lands)land'ы отнюдь не соответствуют двоичному нулю и единице непосредственно. Кодирование информации на CD устроено значительно хитрее и… умнее! Единица представляется переходом от питаpit'а к ленду land'у или наоборот, а ноль —– отсутствием переходов на данном промежутке (см. рис. 1.3 0х015). Причем, между двумя соседними единицами должно быть расположено не мене двух, но и не более десяти нулей. Ограничение снизу обусловлено технологическими трудностями штамповки, а ограничение сверху —– нестабильностью скорости вращения диска. Действительно, пусть стабильность вращения составляет 3%, тогда при считывании последовательности из десяти нулей мы получаем погрешность 1/3 пбита/ленда, что не вызывает никаких проблем. Но уже при чтении пятнадцати нулей погрешность возрастает дпо половины битапита/ленда и приводу остается лишь гадать: в большую или меньшую строну ее следует округлять.
Четырнадцать бит образуют EFM-слово, которое по специальной таблице перекодируется в "нормальный" 8-битный байт (собственно EFM так и расшифровывается: Eight to Fourteen Modulation —– модуляция восемь на четырнадцать). Между двумя EFM-словами располагаются три объединяющих бита (merging bits), которые, во-первых, служат для разрешения конфликтных ситуаций кодирования (например, за одним EMF-словом оканчивающимся на единицу, следует другое EFM-слово, начинающееся с единицы), а, во-вторых, препятствуют появлению ложных синхрогрупп (о чем будет рассказано далеениже).

Рис. 1.3. унок 3 0х015 Принцип записи на CD
Группа из 36 байт образует фреймовый кадр (F1 frame) (рис. 1.4), который состоит из предшествующей ему синхрогруппы, байта субкода и двух 12-байтных групп данных, снабженных 4-байтными полями контрольных сумм (или сокращенно CRC — Cyclical Redundancy Check — контроль с помощью циклического избыточного кода)).

Рис. 1.4. унок 4 0х017 Устройство фреймового кадра
Кадры объединяются в сектора, также называемые блоками. Каждый сектор состоит из 98 хаотично перемешанных кадров (перемешивание позволяет уменьшить влияние дефектов носителя, поскольку, полезная информация как бы "размазывается" вдоль дорожки), причем первые 16-байт всякого сектора занимает специальный заголовок (header), состоящий из: 12-?байтного поля синхронизации, 3-?байтного поля адреса и 1-?байтного поля режима (см. рис. 1.50х018).

Рис. 1.5.унок 5 0х018 Устройство заголовка сектора
Значимость сектора заключается в том, что это наименьший раздел диска, который CD-?привод может считать в "сыром" виде. Причем эта "сырость" на ощупь довольно суха. Никакие приводы не позволяют заполучить содержимое данных кадра как они есть, а принудительно восстанавливают их на аппаратном уровне, используя для этой цели четырехбайтовые поля CRC. Подробности о технике восстановления ошибок мы еще поговориможно найти во врезке, сейчас же достаточно Заметимть, что отсутствие доступа к действительно "сырым" байтам приводит к невозможности получения побитовой копии диска, а, значит, у защитного механизма существует принципиальная возможность отличить где дубликат, а где оригинал!
Легенда
Напомним читателю основные условные обозначения, используемые в этой главе. Количество символов кодируемого сообщения (называемого так же информационным словом) по общепринятому соглашению обозначается букой k; полная длина кодового слова, включающего в себя кодируемые данные и символы четности, — n. Отсюда, количество символов четности равно: n – k. За максимальным количеством исправляемых ошибок "закреплена" буква t. Поскольку, для исправления одной ошибки требуется два символа четности, общее количество символов четности равно 2t. Выражение RS(n, k) описывает определенную разновидность корректирующих кодов Рида-Соломона, оперирующую с n-символьными блоками, k-символов из которых представляют полезные данные, а все остальные задействованы под символы четности.
Полином, порожденный на основе примитивного члена a, называется порожденным или сгенерированным
(generate) полиномом.
фрагмент оригинального диска
Листинг 6.60. Фрагмент скопированного диска
0049D2B0: 00 FF FF FF-FF FF FF FF-FF FF FF 00-00 29 32 01 yyyyyyyyyy )2O
0049D2C0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
…
0049DBE0: 00 FF FF FF-FF FF FF FF-FF FF FF 00-02 81 33 61 yyyyyyyyyy O?3a
0049DBF0: 00 28 00 1E-80 08 60 06-A8 02 FE 81-80 60 60 28 ( ^И•`¦?O??И``(
0049DC00: 28 1E 9E 88-68 66 AE AA-FC 7F 01 E0-00 48 00 36 (^z?hfо?u¦Oa H 6
0049DC10: 80 16 E0 0E-C8 04 56 83-7E E1 E0 48-48 36 B6 96 И-adE¦V?~aaHH6¦Ц
0049DC20: F6 EE C6 CC-52 D5 FD 9F-01 A8 00 7E-80 20 60 18 oi?IROyYO? ~И `^
0049DC30: 28 0A 9E 87-28 62 9E A9-A8 7E FE A0-40 78 30 22 (0zЗ(bzй?~?а@x0"
0049DC40: 94 19 AF 4A-FC 37 01 D6-80 5E E0 38-48 12 B6 8D Фv?Ju7OOИ^a8H¦¦?
0049DC50: B6 E5 B6 CB-36 D7 56 DE-BE D8 70 5A-A4 3B 3B 53 ¦a¦E6?V??OpZд;;S
Листинг 52 фрагмент скопированного диска
Прежде всего, бросается в глаза, что в области Pre-gap второго трека, ранее заполненной нулями, теперь появились какие-то данные, по внешнему виду очень смахивающие на "мусор" и не соответствующие никаким данным исходного трека с данными. Выбрем любую, наугад взятую последовательность, например, 1E 9E 88 68 66 AE AA (в тексте листинга 6.60 она выделена полужирным шрифтом) и попытаемся отыскать ее в исходном файле IMAGE.IMG. Ее там не окажется!
Абсолютный адрес сектора, находящийся в его заголовке (в тексте он взят в рамку), так же выглядит весьма неадекватно, как студент после хорошей пьянки на следующее утро. Смотрите, поле A-SEC принимает неприлично высокое значение, дотягиваясь, аж до 81h, что представляет собой грубешую ошибку. Максииум — здесь может находиться 59h, но никак не больше! Поле Mode, равное в данном случае 61h, тоже очевидно искажено.
Может быть, это просто маленькая локальная ошибка? Но нет! Просмотр заголовков секторов, показывает, что они здесь все такие (листинг 6.61).
Листинг 6.61. Искаженные заголовки секторов
0049DBE0: 00 FF FF FF-FF FF FF FF-FF FF FF 00-02 81 33 61 yyyyyyyyyy O?3a
0049E510: 00 FF FF FF-FF FF FF FF-FF FF FF 00-02 81 34 61 yyyyyyyyyy O?4a
0049EE40: 00 FF FF FF-FF FF FF FF-FF FF FF 00-02 81 35 61 yyyyyyyyyy O?5a
0049F770: 00 FF FF FF-FF FF FF FF-FF FF FF 00-02 81 36 61 yyyyyyyyyy O?6a
004A00A0: 00 FF FF FF-FF FF FF FF-FF FF FF 00-02 81 37 61 yyyyyyyyyy O?7a
Листинг 53 искаженные заголовки секторов
Вот так дела творятся в Багдаде! Ладно, черт с ними — с заголовками секторов, сейчас нас больше волнует вопрос: в какие-же "тар-тарары" провались наши исходные данные и что это за "мусор" читается из аудиотрека? Кто же во всем этом виноват? Дисковые сбои? Аудио-коррекция или… все-таки скремблирование?
Скремблирование! Это точно! Обнаружив в заголовке сектора сигнатуру синхропоследовательности 00 FF FF FF FF FF FF FF FF FF FF 00 и MODE равный единице, привод, не взирая на тип трека, заданный в TOC, интерпретировал данный сектор, как сектор с данными и отскремблировал все его байты — с 12 по 2351 включительно. Не только пользовательская область данных, но и поле MODE отказалось отскреблированным и потому при последующем считывании данного сектора с диска его принадлежность к сектору данных оказалось не столь очевидной и привод, заглянув в TOC, понял, что имеет дело с сектором "аудио", ре-скремблировать который не нужно. В результате мы получили на выходе искаженные скремблером данные, которые оказалось некому восстанавливать!
Такая особенность поведения привода не санкционирована стандартом, который эти вопросы описывает слишком неоднозначно и туманно, поэтому часть приводов (и их большинство!) принудительно скремблируют записываемые "аудио" данные, а часть — пишут их так, как есть. Правда, возможность считывания неотскремблированных секторов никем не гарантирована, поскольку они могут содержать регулярные последовательности данных, дезореентирующих считывающий механизм и вводящий его в грубые ошибки (см. "слабые сектора[Y180] ").
Поэтому для начала лучше поработать с приводами, насильственно скремблирующими сектора. К таковым в частности относятся NEC и TEAC.
Пропустив считанные данные через ре-скремблер, который можно позаимствовать, например, из библиотечки ElbyECC.dll, входящей в состав Clone CDCloneCD, мы восстановим исковерконные скремблером сектора их исходный вид, с которым наша программа без труда сможет работать. А отдельные дисковые сбои могут быть устанены и в ручную, ведь корректирующие коды находятся в нашем распоряжении! Если писать свой собственный декодер Рида-Соломона вам лень, то воспользуйтесь услугами все той же библиотеки ElbyECC.dll (только не забывайте при этом, что распростаняя последнюю в составе своего продукта вы нарушаете авторские права ее создателей).
Кажется, что мы напали на настоящую золотую жилу! Раз содержимое трека с данными, помечанного как аудиотрека принудительно скремблируется при записи, попытка копирования такого диска приведет к его повторному скремблированию, в результате чего мы получим совершенно другие данные (строго говоря, это будет не совсем "другие" данные — повторное скремблирование равносильно ре-скремблированию и исходный "аудиотрек" будет полностью восстановлен, однако, поскольку защитный механизм так же прогоняет данные через ре-скремблер, то он сможет работать только со "своим" диском, а его копипей, правда копия с копии даст желанный результат, но всякий ли до этого догадается?).
Увы! Поскольку, поле MODE так же скремблируется, считанный с защищенного диска сектор уже не опознается приводом как сектор с данными и его принудительное скремблирование не выполняется, благодаря чему "защищенный" диск копируется вполне нормально. Однако… мы проделали слишком большой путь, чтобы вот так запросто сдаваться!
"Аудиотреки", записанные на проводе, который не выполняет их автоматического скремблирования, при попытке копирования на всех остальных приводах приведут к полному провалу, — ведь эти приводы, выполняя скремблирование, необратимо "гробят" содержимое секторов, которое невозможно восстановить даже двукратным перекопированием.
Единственный выход — найти нескремблирующий привод ( что будет весьма непросто, лично я таких приводов так и не нашел), либо изменить прошивку своего пишушего привода так, чтобы он позволял включать/выключать скремблирование секторов по нашему желанию. Для этого подойдет любой привод, который только можно "прошивать" (например, TEAC). Скачав свежую прошивку с сайта его производителя, "натравите" на него дизассемблер, понимающий "язык" данного процессора и проанализируйте алгоритм работы микропрограммы. Только помините, что некорректно измененная прошивка может полностью вывести привод из строя, поскольку процедура "прошивки[Y181] [n2k182] " привода в самой "прошивке" и содержиться и если последняя вдруг перестанет работать, перестанут работать и все "артерии" привода. И хотя осуществить задумание вполне реально, квалификация взломщика должна быть очень и очень высока.
К сожалению, разработчики защищаемого приложения находятся ничуть не в лучших условиях, поскольку для записии оригинальных дисков им требуется аналогичный привод, который чрезвычайно трудно застать в продаже и ничуть не легче изготовить самому. С другой стороны — было бы желание, а уж пути для его осуществления завсегда найдутся! Зато, данный защитный механизм как нельзя лучше подходит для штампованных CD, на логическую структуру которых вообще не наложено никаких ограничений. Диск, защищенный по данной технологии, скопировать практически нереально…
Теперь перейдем к "слабым" секторам, — то есть секторам, содержащим неблагоприятные для привода последовательности. И одна из таких последовательностей — …04 B9 04 B9 04 B9… Нескремблируемый сектор, содержащий такую запись в своем теле запишется без проблем, но в силу определенных конструктивных ограничений даже лучшими из приводов будет читаться крайне нестабильно, а то и вовсе не будет читаться вообще. Так происходит потому, что физическое представление данной последовательности приводит к образованию длиных цепочек лендов (питов), а приводу для работы жизненно необходим постоянно изменяющийся HF--сигнал (HF — High Frequency, высокая частота) и читать однородные области спиральной дорожки он не в состоянии.
Подробнее о "слабых" последовательностях можно прочитать в разд.главе "Синхрогруппы, объединяющие битыmerging bits и DSV" главы 1 и "Слабые (weak) сектора[Y183] ". Для нас же сейчас важно в первую очередь тот факт, чтово-первых, некоторые приводы все-таки ухитряются найти выход из положения, просто меняя стартовую позицию сектора во фрейме, что ведет к колоссальным изменениям на физическом уровне представления информации и "слабая" последовательность внезапно перестает быть таковой, нормально читаясь всеми приводами. Но! Скопировать такой диск можно только на том приводе, который умело распознает и корректно обрабатывает "слабые" последовательности (к таким приводам в частности относятся приводы Plextor, за полным списоком подходящих для этих целей моделей обращайтесь к справке Clone CDCloneCD).
С другой стороны, приводы пишушие "слабые" последовательности как есть оказываются невероятно полезными для качественной имитации сбойных секторов (подробнее см. разд. "Защиты, основанные на физических дефектах" главы 9), поскольку сектора, содержащие "слабые" последовательности, не читаемыбельны на физическом уровне. Это вам не тривиальное искажение полей EDC/ECC полей, легко обнаруживаемое защитным механизмом путем чтения сектора в "сыром" режиме. "Слабые" сектора к тому же заставляют привод сбросить скорость и немного поерзрхать головкой, вызывая тем самым определенную временную задержку —– точно такую, какую вызываются настоящие сбойные сектора (и многие защитные механизмы закладываются на это). Сектор с искореженным EDC/ECC, напротив, читается практически мгновенно, чем и выдает себя с головой. Короче говоря, "папуас папуасу друг, товарищ и корм", —– слабые сектора служает не только на благо защиты, но и неплохо чувствуют себя в руках "пролетариата" —– то бишь хакеров и кракеров, не желающих платить "буржуинам" свои кровные.
Надеююсь, вы будете не против немного поэкспериментировать с ними?
Итак, берем наш старый-добрый образ оригинального файла (нет, не искореженный скремблированием образ защищенного файла, а образ снятый с нормального диска), привычным дивжением руки меняем атрибуты трека с данными на аудио, как это мы уже делали ранее, но в дополнение к тому искажаением поле синхронизации Sync и/или поле MODE нескольких секторов с заранее известными адресами. Записываем образ на диск и убеждаемся, что теперь их содержимое уже не скремблируется и с диска читается именно то, что мы на него писали (правда, если сектор содержит в себе регулярные последовательности он может и не прочитаться —– все же не от простой жизни секторам с данными скремблирование придумали).
А теперь забьем эти сектора последовательностью …04 B9 04 B9 04 B9… и запишем их снова. Если ваш привод не достаточно интеллектуален для того, чтобы выбирать стартовую позицию сектора во фрейме, наши сектора запишутся самым неблагоприятным образом и попытка их чтения даст ошибку! Кстати, если вы густо усеете диск сбойными секторами, —– его копирование окажется чрезвычайно затруднено, особенно если расположить "слабые" сектора группами, размер которых варьируется от 9 до 99 секторов, а за концом каждой групы будет расположен один ключевой сектор (т. е. обыкновенный сектор, содержащий ключевую информацию). Дело тут вот в чем. Умные копировщики (Clone CDCloneCD или \Alcohol 120%Алкоголь), обнаружив, что диск содержит большое число дефектных секторов, на чтение которых уходит коллосальноеколоссальное количество времени, предлагают пользователю задействовать режим быстрого пропуска сбойных секторов, —– тогда, встретившись со сбойным сектором, копировщик пропускает 100 последующих секторов, экономя время на попытках их чтения. Защиты, привязывающиеся к настоящим физическим дефектам поверхности, на этом трюке "обламываются" по полной программе (т. к.дефекты имеют тенденцию со временем разрастаться и потому внедрять ключевую информацию в окрестности дефектной области крайне не рекомендуетсяопасно для своих яйиц). Однако, слабые сектора не являются дефективными в физическом смысле этого слова и потому чтению прилагающих к ним секторов ничуть не мешают. А раз так, то – мы можем смело закладываться на их существование! Копирование защищенного диска в режиме "быстрого пропуска" пропустит не только "слабые" сектора, но и ключевые метки, а копирование в обычном режиме растянется на несколько часов (если не больше) да и то по причинам о которых мы поговорим далеениже.
первое вхождение искомой последовательности в образе диска
Листинг 8.2. Второе вхождение искомой последовательности в образе диска
00010370: 01 00 00 00 00 01 91
63 ¦ CD 36 00 00 36 CD 63 67 O OСc=6 6=cg
00010380: 06 1D 17 0D 0A 28 0C 00 ¦ 00 00 01 00 00 01 32 00 ¦-¦d0(+ O O2
00010390: 30 00 31 00 20 00 2D 00 ¦ 20 00 50 00 65 00 72 00 0 1 - P e r
000103A0: 73 00 6F 00 6E 00 61 00 ¦ 6C 00 20 00 4A 00 65 00 s o n a l J e
000103B0: 73 00 75 00 73 00 2E 00 ¦ 6D 00 70 00 33 00 3B 00 s u s . m p 3 ;
Листинг 70 второе вхождение искомой последовательности в образе диска
Искомое значение действительно присутствует в образе, причем не в одном, а в двух… нет, даже в четырех экземплярах! Нет, это не чертовщина — – все так и должно быть. Современные лазерные диски содержат две файловых системы: одна из которых —– ISO-9660 —– записывается на диск исключительно для его совместимости с устаревшим программным обеспечением, ограничивающим максимальную длину файла одиннадцатью символами (восемь из которых приходятся собственно на само имя, а оставшиеся три —– на расширение). Современное программное обеспечение работает с более "продвинутыми" файловыми системами к которым принадлежит и файловая система Joliet Джульета (ДжульеттаJoliet), разработанная компанией Microsoft. Говорите, "только Ромео для полноты компании не хватает"? А ведь файловая система Romeo Ромео (РомеоRomeo) действительно есть и разработана она компанией Adaptec. К сожалению, этот "Ромео" не получил большого распространения и скоропостижно "скончался", так что Joliet (Джульетта) вынуждена оставаться лась в одиночестве.
Но довольно романтики, возвращаемся к делу. Заботиться о синхронизации обоих файловых систем в общем-то и необязательно, т. к. операционная система Windows "видит" только Joliet Джульету и игнорирует ISO-9660, а MS-DOS поступает с точностью до наоборот. Поэтому, если мы увеличим длину файла в JolietДжульете, но "забудем" внести соответствующее изменения в ISO-9660 (а некоторые разработчики защит именно так и поступают!), Windows не заподозрит в этом и тени обмана.
Вот хакеры —– другое дело! Оригинальные длины файлов, оставленные в ISO-9660, значительно упрощают задачу взломщика и потому оставлять их там ни в коем случае не стоит! К тому же, существуют драйвера, позволяющие вручную выбирать какую из имеющихся файловых систем следует монтировать. Так что не будем лениться и скорректируем оба значения сразу, изменив два старших байта с "36 00" на "FF 66" (естественно, вы можете предпочесть и другое значение). Когда будете это делать обратите внимание на двойное слово "00 36 CD 63" —– это тоже длина файла, но записанная в "противоестественном" для IBM PC порядке. Здесь младший байт располагается по большему адресу. Адрес стартового сектора файла так же записан в двух вариантах. Очевидно, такая схема представления информации выбрана по соображениям переносимости и каждая платформа вправе выбирать наиболее естественный для нее порядок байтов, однако, не факт, что операционная система Windows выберет вариант "младший байт по меньшему адресу". Все решает файловый драйвер, а он в зависимости от особенностей реализации может работать с любым из этих полей. Поэтому, оба этих поля всегда должны быть согласованы.
Теперь исправленный (в смысле искаженный) ISO-образ можно смело записывать на диск CD-R/CD-RW диск или смонтировать образ на виртуальный CD-привод (для этого вам понадобиться Alcohol 120% или его аналоги). Даем команду "DIR" и смотрим (листинг 8.3).:
Листинг 8.3. Размер файла Personal Jesus.mp3 умышленно искажен
>
dir N:\Depeche Mode
Том в устройстве N имеет метку 030706_2038
Серийный номер тома: 61A1-A7EE
Содержимое папки N:\Depeche Mode
06.07.2003 21:56 <DIR>
.
06.07.2003 21:56 <DIR>
..
01.01.1601 04:00 1 728 040 291
01 - Personal Jesus.mp3
30.06.2003 00:11 3 574 805 02 - See You.mp3
30.06.2003 00:12 3 472 405 03 - Strangerlove.mp3
30.06.2003 00:12 3 718 165 04 - Enjoy The Silence.mp3
30.06.2003 00:13 2 956 643 05 - The Meaning Of Love.mp3
30.06.2003 00:14 3 820 565 06 - Master and Servant.mp3
30.06.2003 00:15 3 066 149 07 - Never Let Me Down Again.mp3
30.06.2003 00:16 3 806 772 08 - Its Called a Heart.mp3
30.06.2003 00:16 3 813 460 09 - Little 15.mp3
30.06.2003 00:17 3 574 805 10 - Everything Counts.mp3
30.06.2003 00:18 3 687 236 11 - People Are People.mp3
30.06.2003 00:19 4 916 036 12 - The Thing You Said.mp3
30.06.2003 00:20 4 182 100 13 - Agent Orange.mp3
30.06.2003 00:21 4 585 012 14 - World in my Eyes.mp3
30.06.2003 00:22 3 646 276 15 - Behind The Wheel.mp3
30.06.2003 00:22 3 049 012 16 - Black Celebration (live).mp3
30.06.2003 00:23 3 800 085 17 - Nothing.mp3
30.06.2003 00:25 7 151 700 18 - Bonus (unnamed).mp3
18 файлов 1 794 861 517 байт
2 папок 0 байт свободно
Листинг 71 размер файла "Personal Jesus.mp3" умышленно искажен путем
Вот это да! Размер файла увеличился до 1 .728 .040 .291 байт (см. выделенную полужирным шрифтом строку листинга), что более чем в два с половиной раза превышает объем всего лазерного диска. А еще говорят, что часть не может быть больше целого! Естественно, попытка скопировать файл на жесткий диск винчестер заканчивается провалом и приходится искать обходные пути. Будем исходить из того, что файлы на диске располагаются последовательно, т. е. за последним сектором одного файла, непосредственно следует стартовый сектор следующего. А, поскольку, стартовые сектора всех файлов нам известны, определение номеров последних секторов для всех файлов, за исключением самого последнего, не составит никакого труда.
Скопируем ISO-образ защищенного диска в файл и рассмотрим его каталог еще раз (листинг 8.4).:
Листинг 8.4. Подследственный фрагмент "препарируемого" образа файла
0000E040: 00 01 01 01 54 00 94 01 ¦ 00 00 00 00 01 91 63 CD OOOT Ф¦ OСc=
0000E050: FF 66 66 FF CD 63 00 00 ¦ 00 00 00 00 00 00 00 00 ff =c
0000E060: 01 00 00 01 32 00 30 00 ¦ 31 00 20 00 2D 00 20 00 O O2 0 1 -
0000E070: 50 00 65 00 72 00 73 00 ¦ 6F 00 6E 00 61 00 6C 00 P e r s o n a l
0000E080: 20 00 4A 00 65 00 73 00 ¦ 75 00 73 00 2E 00 6D 00 J e s u s . m
0000E090: 70 00 33 00 3B 00 31 00 ¦ 46 00 6B 08 00 00 00 00 p 3 ; 1 F k•
0000E0A0: 08 6B 15 8C 99 00 00 99 ¦ 8C 15 67 06 1D 17 0B 1C •k§МЩ ЩМ§g¦-¦>L
0000E0B0: 0C 00 00 00 01 00 00 01 ¦ 24 00 30 00 32 00 20 00 + O O$ 0 2
0000E0C0: 2D 00 20 00 53 00 65 00 ¦ 65 00 20 00 59 00 6F 00 - S e e Y o
0000E0D0: 75 00 2E 00 6D 00 70 00 ¦ 33 00 3B 00 31 00 50 00 u . m p 3 ; 1 P
Листинг 72 подследственный фрагмент препарируемого образа файла
Наименьший номер стартового сектора файла, следующий за сектором 0191h, равен 086Bh. Таким образом, файл "01 – – Personal Jesus.mp3" не может содержать более 086Bh -? 0191h === 6DAh секторов или 1754 * 2048 === 3 .592 .192 байт. Конечно, это несколько завышенная оценка и действительный размер файла на 1,5полтора Ккилобайта короче, но такое расхождение уже не критично. Большинство мультимедийных файлов будут вполне нормально обрабатываться даже при наличии некоторого количества постороннего "мусора" на "хвосте". Исправив образ файла, запишем его на диск или просто усечем файл до необходимых размеров с помощью любой подручной утилиты типа "Добермана Пинчера" ("Pinch of File").
А что делать, если вас не устраивает столь низкая стойкость подобной защиты? Ну… кое-что вы можете сделать.
Например, уменьшить стартовые сектора некоторых файлов, "убивая тем самым сразу двух зайцев". Во-первых, файл с некорректно заданным сектором уж точно не будет нормально обрабатываться ассоциированным с ним приложением (что и не удивительно, ведь действительное начало файла теперь окажется глубоко в его середине), во-вторых, алгоритм определения оригинальных длин по разнице соседних стартовых секторов даст глубоко неверный результат и восстановленный файл окажется обрезанным.
Защитный механизм, "знающий" на сколько секторов сдвинуто действительное смещение файла относительно его начала, должен либо переместить файловый указатель вызовом функции SetFilePointer, либо "проглотить" "мусорные" данные с помощью функции ReadFile. Оба способа практически равнозначны и каждый из них имеет свои сильные и слабые стороны. Функция SetFilePointer работает значительно быстрее, но слишком заметена (для хакеров), напротив, с вызовом функции ReadFile еще предстоит разобраться какие данные он читает —– значимые или нет.
Рассмотрим, как выглядит процесс взлома на практике. Поскольку, писать полноценный MP3-плейер мне было откровенного лениво (да и места он бы занял немеряно), то вся обработка данных сводится к выводу оригинального содержимого файла на экран (листинг 8.5). Перед первым запуском программы, стартовый сектор защищенного файла должен быть уменьшен на величину _NSEC_, а размер увеличен по меньшей мере на 2048*_NSEC_ байт, верхнего же ограничения на максимальную длину нет (все 32-бита поля длины — ваши).
Листинг 8.5. [crackme.27AF7A2Dh] Демонстрация обработки файлов с искаженными атрибутами стартового сектора и длины
/*----------------------------------------------------------------------------
*
* crack me 27AF7A2D
* =================
*
* демонстрационный пример обработки файлов с умышленно уменьшенным номером
* номером стартового сектора и увеличенной длиной; позиционирование файлового
* указателя осуществляется вызовом функции fseek, потому этот crackme очень
* очень легко взломать (см. так же ..... - как более стойкий пример реализации
* реализации той же защиты)
*
* Build 0x001 @ 02.07.2003
----------------------------------------------------------------------------*/
#include <stdio.h>
// настройки программы
// ===================
// имя открываемого файла (если защита находится на CD, то полный путь к файлу
// очевидно указывать не обязательно)
#define _FN_ "M:\\Depeche Mode\\01 - Personal Jesus.mp3"
// количество секторов на которые смещено начало файла
#define _NSEC_ 4
// оригинальный размер файла
#define _FSIZ_ 3591523
// размер пользовательской части сектора
#define SECTOR_SIZE 2048
// ширина экрана в символах (нужна для вывода дампа)
#define _SCREEN_LEN_ 80
// размер обрабатываемого блока
#define BLOCK_SIZE 0x666
// поиск минимума двух чисел
#define _MIN(a,b) ((a<b)?a:b)
// ВЫВОД HEX-ДАМПА НА ЭКРАН
//-------------------------
// src - указатель на выводимые данные
// n - кол-во выводимых на экран байт
print_hex(unsigned char *src, int n)
{
int a; static p = 1;
for (a=1; a <= n; a++)
printf("%02x%s",src[a-1],(p++%(_SCREEN_LEN_/3-1))?" ":"\n");
}
main()
{
int a;
FILE *f;
long p = _FSIZ_;
char buf[BLOCK_SIZE];
// TITLE
fprintf(stderr, "crackme 27af7a2d by Kris Kaspersky\n");
// пытаемся открыть файл
if ((f = fopen(_FN_, "rb")) == 0)
{
fprintf(stderr, "-ERR: can not open %s\n",_FN_);
return -1;
}
// пропускам _NSEC_ лишних секторов, находящихся в начале файле
fseek(f, _NSEC_*SECTOR_SIZE, SEEK_SET);
// читаем файл блоками, тщательно следя за тем, чтобы не вылететь
// за пределы его оригинального размера
while(p)
{
// внимание! для обработки файлов с искаженным размером категорически
// не рекомендуется использовать функцию fgetc, поскольку в большин-
// стве своих реализаций она обрабатывает файл не байтам, но блоками
// заранее неизвестного размера. Т.е. она осуществляет прозрачную
// буферизацию ввода, опираясь на установленный размер файла как на
// эталонный. Если же установленный размер файла искажен, то нет
// никаких гарантий, что функция fgetc не залезет за пределы диска
// со всеми отсюда вытекающими последствиями (особенно это вероятно,
// если обрабатываемый файл - последний на лазерном диске), так что
// используйте fread, а еще лучше ReadFile, который уж точно не
// полезет в пекло поперед батьки
fread(buf, 1, a = _MIN(p,BLOCK_SIZE), f);
// читаем очередной блок
print_hex(buf,a);
p-= a // выводим его на экран
}
}
Листинг 73 [crackme.27AF7A2Dh] Демонстрация обработки файлов с искаженными атрибутами стартового сектора и длины. Перед первым запуском программы, стартовый сектор защищенного файла должен быть уменьшен на величину _NSEC_, а размер увеличен по меньшей мере на 2048*_NSEC_ байт, верхнего же ограничения на максимальную длину нет (все 32-бита поля длины – ваши).
Обнаружив, что основные атрибуты файла искажены (то есть файл попросту не читается), хакер очевидно захочет определить смещение первого действительного байта и оригинальный размер файла.
Применим отладчик Soft-Ice. "… Винии поплевал на лапки для храбрости и набрал заветную команду soft-ice." (почти по Щербакову)(листинг 8.6).
Листинг 8.6. Протокол работы с Soft-Ice
:bpx CreateFileA ; ставим точку останова на CreateFileA
:x ; выходим из айса
…
Break due to BPX KERNEL32!CreateFileA (ET=3.37 seconds)
; отладчик всплывает, значит, CreateFileA кем-то только что была вызвана
; но вот кем? пытаемся определить это по имени открываемого файла
:d esp->
4 ; смотрим первый слева аргумент, передаваемый функции
0010:0040706C 4D 3A 5C 44 65 70 65 63-68 65 20 4D 6F 64 65 5C M:\Depeche Mode\
0010:0040707C 30 31 20 2D 20 50 65 72-73 6F 6E 61 6C 20 4A 65 01 - Personal Je
0010:0040708C 73 75 73 2E 6D 70 33 00-4D 3A 5C 44 65 70 65 63 sus.mp3.M:\Depec
; ага! это как раз то что нам нужно!
:p ret ; выходим из функции
:? Eax ; подсматриваем значение дескриптора открытого файла
00000030 0000000048 "0" ; дескриптор равен 0x30 (или 48 в десятичной нотации)
:bpx SetFilePointer if (esp->
4 == 0x30);
:bpx ReadFile if (esp->
4 == 0x30)
; устанавливаем точки останова на основные файловые функции SetFilePointer и ReadFile,
; ReadFile, заставляя отладчик всплывать тогда и только тогда, когда им передается
; "наш" дескриптор! (специальное замечание для разработчиков защиты: господа,
; давайте же, право, себя так легко обмануть! открывайте файл несколько раз подряд и
; и попеременно работайте с ним через различные дескрипторы, - это сильно затрудняет
; затрудняет анализ)
:x ; выходим из отладчика
…
Break due to BPX KERNEL32!SetFilePointer IF ((ESP->
4)==0x30) (ET=76.19 microseconds)
; это сработала точка останова на SetFilePointer, теперь нам необходимо подсмотреть
; значение offset на которое смещается указатель и origin – чтобы определить
; относительно какой части файла осуществляется отсчет
:? esp->
8 ; смотрим второй слева аргумент функции
00002000 0000008192 " " ; указатель смещается на 0x2000 байт относительно…
:? esp->
0C ; смотрим третий слева аргумент функции
00000000 0000000000 " " ; …относительно начала файла (SEEK_SET)
:p ret ; выходим из отладчика
…
; больше функция SetFilePointer не вызывается, но зато наблюдается многократные
; вызовы функции ReadFile. Для анализа защитного кода мы не будем давать P RET
; (как это рекомендуют делать некоторые хакерские руководства). Ведь ReadFile
; скорее всего вызывается не напрямую, а из библиотечной функции-обертки,
; анализ которой нам ничего не даст. Лучше посмотрим стек вызовов…
…
:stack ; смотрим стек вызовов
12F8C8 401E1C KERNEL32!ReadFile
12F8F8 4010E5 crackme!.text+0E1C
12FFC0 77E87903 crackme!.text+00E5
12FFF0 0 KERNEL32!SetUnhandledExceptionFilter+005C
; адрес 55E87903h очевидно принадлежит недрам операционной системы и потому нам
; не интересен, адрес 401E1Ch (адрес возврата из ReadFile) там как же неинтересен,
; поскольку, как мы уже и говорили, скорее всего принадлежит библиотечной функции-
; обертке, а вот на адрес 4010E5h имеет смысл взглянуть:
:u 4010E5
001B:00401072 MOV EDI, 36CD63 ; EDI := 36CD63
001B:004010C8 CMP EDI,00000666 ; \ ß (1)
001B:004010CE MOV ESI,EDI ; +- ESI := _min(0x666, EDI)
001B:004010D0 JL 004010D7 ; +
001B:004010D2 MOV ESI,00000666 ; /
001B:004010D7 PUSH EBX ; …
001B:004010D8 PUSH ESI ; кол-во читаемых элементов
001B:004010D9 LEA EAX,[ESP+14] ; получаем указатель на буфер
001B:004010DD PUSH 01 ; размер одного элемента
001B:004010DF PUSH EAX ; передаем указать на буфер
001B:004010E0 CALL 00401141 ; эта функция вызывает ReadFile
001B:004010E5 LEA ECX,[ESP+1C] ; получаем указатель на буфер
001B:004010E9 PUSH ESI ; …
001B:004010EA PUSH ECX ; …
001B:004010EB CALL 00401000 ; обрабатываем прочитанные данные
001B:004010F0 ADD ESP,18 ; вычищаем ненужные аргументы из стека
001B:004010F3 SUB EDI,ESI ; EDI := EDI - _min(0x666, EDI)
001B:004010F5 JNZ 004010C8 ; мотаем цикл, пока есть что обрабатывать (1) à
001B:004010F7 POP ESI ; …
; изучение окрестностей адреса 4010E5 позволяет за считанные минуты восстановить
; алгоритм обработки файла. файл читается кусками по 0x666 байт до тех пор пока
; этих байт не наберется ровно 0x36CD63 (или 3.591.523 в десятичной нотации)
Листинг 74 протокол работы с soft-ice
Таким образом, после открытия файла его указатель смещается вперед на 0x2000 байт (4 сектора), а затем из файла считывается 3 .591 .523 байт данных, после чего его обработка прекращается. Следовательно, защищенный файл может быть восстановлен так…
Попробуйте его проиграть каким ни будь MP3-плейером. Если все было сделано правильно, то вы окунетесь в ритмичные звуки Depeche Mode, не омраченные более никакими защитами! Под такую музыку очень хорошо заниматься усилением защитных механизмов, а усиливать здесь есть чего!
"Хитрая" обработка защищенных файлов подразумевает использование как минимум трех дескрипторов для каждого файла: два из них обрабатывают действительно полезные данные, а третий "замысловато пляшет" по файлу, читая бессмысленный "мусор". Этот "мусор" передается громоздкой и жутко запутанной процедуре, выполняющий сложные, но реально никак не используемые вычисления. "Скормив" такой процедуре первые _NSEC_ секторов защищенного файла, мы создадим обманчивую видимость, что обработка файла начинается с его начала (ну… или почти начала, разработчику защиты ничего не стоит переместить указатель на любую понравившуюся ему позицию).
Реально используемые дескрипторы должны открываться после возращения "подсадного", т. к. большинство хакеров отслеживают лишь первый вызов функции CreateFileA, открывающийоткрывающей заданный файл, и игнорируют все остальные (многим просто не приходит с голову, что один и тот же файл может открываться дважды).
Позиционирование на первый значимый байт лучше всего осуществлять не функцией SetFilePointer, а путем чтения "мусорных" данных с последующей имитацией их обработки. В грамотно сконструированной защите определить где кончается мусор и начинаются действительно значимые данные очень и очень сложно. Однако, и запрограммировать такую защиту нелегко (а ведь ее еще и отлаживать придется!), поэтому для простоты можно ограничиться тем, что начало значимых данных совпадает с первым байтом очередного читаемого блока.
Оригинальную длину файла хранить в виде константы крайне нежелательно, т. к. при анализе программы все константы сразу же бросаются в глаза и нужное значение быстро находится даже тупым перебором (большинство программ содержат не так уж много констант, соизмеримых по величине с длинами обрабатываемых файлов). Храните не длину файла, ано длину его "хвоста", т. е. остаток, полученный от деления оригинальной длины на размер обрабатываемых блоков.
Естественно, размер блоков и их количество блоков так же придется где-то хранить, но… проанализировать взаимосвязь трех констант значительно труднее одной!
Учитывая все вышесказанноеранее сказанное, мы сможем значительно усилить нашу защиту. Один из вариантов ее реализации может выглядеть, например, так как показано в листинге 8.7.:
Листинг 8.7. [crackme.CEE99D84h.c] Программная реализация защитного механизма, основанного на искаженном оглавлении диска
// размер "хвоста" последнего блока
#define TAIL_SIZE (_FSIZ_ % BLOCK_SIZE)
// кол-во целых блоков
#define N_BLOCKS (_FSIZ_ / BLOCK_SIZE /2)
// ХОЛОСТАЯ ОБРАБОТКА ДАННЫХ
// -------------------------
// желательно сделать эту функцию как можно более сложной и запутанной,
// чтобы факт ее холостой работы был не так очевиден
threshing(unsigned char *src, int n)
{
int a, sum=0;for (a = 0; a< n; a++) sum += src[a]; return sum;
}
main()
{
int a = 0;
long p = _FSIZ_;
FILE *f_even, *f_uneven, *f_threshing;
char buf[BLOCK_SIZE + (_NSEC_*SECTOR_SIZE)];
// TITLE
fprintf(stderr, "crackme 27af7a2d by Kris Kaspersky\n");
// пытаемся открыть файл
// f_threshing лучше всего открывать первым, т.к. первый же встретившийся
// хакеру вызов CreateFileA должен давать "подсадной" дескриптор
if ( ((f_threshing = fopen(_FN_, "rb")) == 0) ||
((f_even = fopen(_FN_, "rb")) == 0) ||
((f_uneven = fopen(_FN_, "rb")) == 0))
{ fprintf(stderr, "-ERR: can not open %s\n",_FN_);
return -1;}
// устанавливаем f_even
fread(buf, 1, _NSEC_*SECTOR_SIZE, f_even);
// имитируем пропуск NSEC*SECOR_SIZE/2 байт (вдруг хакер на это купится?)
// на самом же деле, все NSEC*SECTOR_SIZE первый байт файла идут в муор-
// ное ведро
threshing(buf + _NSEC_*SECTOR_SIZE/2,_NSEC_*SECTOR_SIZE/2);
// устанавливаем f_uneven
fread(buf, 1, _NSEC_*SECTOR_SIZE+BLOCK_SIZE, f_uneven);
// имитируем пропуск NSEC*SECOR_SIZE/3 байт
threshing(buf + _NSEC_*SECTOR_SIZE/3, 2*_NSEC_*SECTOR_SIZE/3+BLOCK_SIZE);
// устанавливаем threshing, пуская хакера по ложному следу
fseek(f_threshing,_NSEC_*SECTOR_SIZE/4,SEEK_SET);
// читаем файл блоками, тщательно следя за тем, чтобы не вылететь
// за пределы его оригинального размера
for (a=0; a < N_BLOCKS; a++)
{
// читаем данные в холостую
fread(buf, 1, BLOCK_SIZE, f_threshing);
threshing(buf,BLOCK_SIZE);
// читаем четный действительный блок
fread(buf, 1, BLOCK_SIZE, f_even);
print_hex(buf,BLOCK_SIZE);
// пропуск нечтного блока для дескрпитора f_even
fread(buf, 1, BLOCK_SIZE, f_even);
threshing(buf,BLOCK_SIZE);
// читаем нечетный действительный блок
fread(buf, 1, BLOCK_SIZE, f_uneven);
print_hex(buf,BLOCK_SIZE);
// пропуск уже четного блока для дескрпитора f_uneneven
fread(buf, 1, BLOCK_SIZE, f_uneven);
threshing(buf,BLOCK_SIZE);
}
// дочитываем хвост
fread(buf, 1, TAIL_SIZE, f_even);
print_hex(buf, TAIL_SIZE);
}
Листинг 75 [crackme.CEE99D84h.c] программная реализация защитного механизма, основанного на искаженном оглавлении диска
Попробуйте взломать эту защиту. Что, не получается? Попытка отследить вызовы файловых функций SetFilePoiner и ReadFile ничего не дает, т. к. данные считываются глубоко нелинейным образом и способов быстрого отделения "зерен" от "плевел" здесь не существует. Такие защиты вообще не "ломаются" в отладчике, —– тут требуется помощь дизассемблера, но и с дизассемблером на скорый успех рассчитывать не приходится. Сложность и запутанность алгоритма обработки данных значительно усложняет анализ программы и на определение действительных границ файла даже у профессионала может уйти несколько часов (а в некоторых случаях и дней!). По соображениям экономии места дизассемблерные листинги и описание процесса взлома здесь не приводятся, поскольку в них нет ничего интересного —– просто тупая рутина и все. Единственная зацепка —– функция Threshing, имитирующая обработку данных. Как только хакер поймет, что результаты ее работы никак не используются в программе, он тут же продвинется далеко вперед. Контрольные точки останова на чтение/записи памяти позволяют быстро и элегантно определить: происходит ли обращение к заданным ячейкам или нет. Короче говоря, нет ничего тайного, что при помощи отладчика Soft-Ice и дизассемблера IDA Pro не стало бы явным…
Механизмы защиты
В этой главе рассматриватся различные механизмыанатомия защит от несанкционированного копирования CD с объяснением принципов их работы, примерами программной реализации и демонстрацией как эти защиты могут быть нейтрализованы.
Классификация защит (или здесь не вам Англия – копать надо глубже): Классифицировать защиты от несанкционированного доступа можно по разным критериям (на редкость умная фраза, конечно, но надо же как-то начать).
Наиболее важными из них является следующие:
q стойкость ко взлому (копируется штатным копировщиком; копируется специализированным копировщиком или допускает эмуляцию защищенного носителя; не копируется в автоматическом режиме вообще);
q принцип защиты (нестандартная разметка диска; привязка к физическим характеристикам конкретного носителя);
q степень совместимости с программно/аппаратной средой (защитный механизм полностью соответствует стандарту и совместим со всем стандартным оборудованием; защитный механизм формально не нарушает стандарт, но закладывается на никем не гарантированные особенности реализации оборудования; защитный механизм явно нарушает стандарт, закладываясь на вполне определенный модельный ряд оборудования);
q уровень реализации (программный —– создание мастер-диска осуществляет на штатном оборудовании; аппаратный —– создание мастер-диска требует специального оборудования);
q интерфейс взаимодействия с приводом (стандартная библиотека языков Си и/или Паскаль; API операционной системы; низкоуровневый доступ к оборудованию);
q объект защиты (защита от копирования всего диска целиком, защита от пофайлового копирования, защита цифрового "грабежа" аудио контента).
Что касается стойкостиь ко взлому, то: абсолютной защиты от копирования оптических носителей не существует, да и не может существовать в принципе, поскольку, коль скоро диск можно прочитать, можно его и скопировать.
Конечно, при наличии достойной аппаратной защиты, насильно вмонтированной в чипсет привода, процедура взлома рискует оказаться весьма непростой, а то и вовсе нереализуемый на штатном оборудовании. Но что помешает хакеру модифицировать прошивку своего привода или внести в него определенные конструктивные изменения, заблокировав защиту? Достаточно вспомнить нашумевшую историю с чипами MOD чипами, чтобы все иллюзии держателей авторских прав рассеялись словно дым.
Бороться с профессиональными взломщиками —– абсолютно бессмысленно. Этотй бой еще не выигрывал еще никто. Чем стремительнее совершенствуются защитные механизмы, тем соблазнительнее выглядит их взлом. Даже самые совершенные защиты ломаются —– это только вопрос времени, стимула и вложенных во взлом денег (а финансовый потенциал пиратов поистине безграничен —– имейте ввиду).
Поэтому защищаться следует не от хакеров, а от квалифицированных пользователей. По минимуму, защищенный диск не должен копироваться никакими штатными копировщиками (Ahead Nero, Roxio Easy CD Creator), а по максимуму —– и специализированными копировщиками защищенных дисков тоже (Alcohol 120%, Clone CD). Впрочем, некопируемость бывает она очень разной бывает. Физические дефекты поверхности на бытовом оборудовании не копируются в принципе, но легко имитируются искажением контрольной суммы сектора, которая, впрочем, умными защитами элементарно распознается (правда, для этого защита должна спуститься с уровня API на несколько ступень вглубь, получив прямой доступ к железу, что не есть хорошо в плане конфликтности и безопасности).
Еще сложнее справиться с эмуляцией оригинального носителя. Некоторые продвинутые копировщики (например, Alcohol 120%Алкоголь) создают виртуальный привод, ведущий себя точь-в-точь как защищенный диск, старательно воспроизводя все ну, или практически все, физические характеристики поверхности. Отсюда: трудоемкость копирования оригинального носителя определяется отнюдь не сложностью имитации тех или иных ключевых особенностей, ано скрытностью их размещения.
Другими словами, необходимо найти такой набор отличительных признаков, факт присутствия которого было бы чрезвычайно трудно обнаружить. Хорошим кандидатом на эту роль выглядят каналы подкода нечитаемых секторов —– в силу конструктивных особенностей оптических приводов, точность позиционирования на субканальные данные невелика и результат SCSI/ATAPI-команды READ SUBCHANNEL не только непредсказуем, но еще и не воспроизводим! При каждом ее выполнении она возвращает субканальные данные сектора N ± d + k, где N —– адрес запрошенного сектора, d —– случайная, а k —– систематическая погрешность привода. Таким образом, на "грабеж" субканальных данных всех секторов уйдет очень много времени, а, если, субканальные данные умышленно перепутаны и/или искажены, задача их копирования становится вообще нереальной. Скопировать такой диск практически невозможно —– ни существующими, ни последующими копировщиками.
Стойкость защиты к битовому взломуbit-hack'у в общем-то не критична. Какой бы "крутой" она не была, ее все равно взломают —– был бы стимул! Поэтому речь идет лишь о затруднении копирования оригинальных носителей штатными или хакерскими средствами. А как можно затруднить копирование?
Во времена господства MS-DOS и 3,5"/5,25" накопителей на гибких магнитных дисках (или приводов floppy) широко использовалась такие приемы защиты, как нестандартная разметка диска и создание трудновоспроизводимых дефектов диска, которые могли быть реализованы как на аппаратном, так и на программном уровне. Под "аппаратным" уровнем в данном контексте понимается нестандартное оборудование, используемое для записи защищенного диска (например, устройство, формирующее лазерные метки, путем испарения магнитного покрытия в строго определенных местах или же банальный конденсатор перменной емкости (КПЕ), подключенный параллельно к кварцу для изменения его частоты, а, значит, и длины дорожки). "Программные" же методики защиты ограничивались лишь штатным оборудованием, значительно снижая накладные расходы на тиражирование оригинальных дисков (при небольших партиях это было весьма актуально).
Самое забавное, что стойкость аппаратных защит была ничуть не выше программных и все они ломались программными методами, зачастую в полностью автоматическом режиме.
Вообще говоря, все существующие методики защиты лазерных дисков можно разделить на два типа:
q нестандартная разметка диска;
q и привязка к физическим характеристикам конкретного носителя.
Защиты первого типа живут за счет нарушения стандартов, в то время как подавляющее большинство "честных" программ эти самые стандарты стараются соблюдать. В результате, защищенный диск не может быть скопирован штатным способом, на что держатели авторских прав, собственно, и рассчитывают. Идея нестандартных разметок не нова и широко использовалась еще во времена "древних" компьютеров таких как "Амига", , "Спектурмов" и прочих древних компьютеров. Устоять против "человека -с -мозгами" такая защита все равно не могла, а вот проблемы, которые она вызывала у легальных пользователей, уже давно вошли в анналы. Любое, даже самое незначительное отступление от стандартов, лишает вас всяких гарантий того, что диск вообще будет читаться! Большое количество разнородного оборудования, присутствующего на рынке, не позволяет протестировать защищенные диски на всех существующих моделях приводов, а, значит, есть риск, что обладатели не протестированных моделей столкнуться с серьезными проблемами. И с ростом тяжести нарушения стандарта, этот риск многократно усиливается.

Рис. 61.1. Классификация защитных механизмов
Защита диска от проигрывания в компьютерных приводах CD-ROM, так же называемая защитой от цифрового воспроизведения —– самый гнусный тип защиты из всех защитных механизмов вообще. Основная цель защиты —– предотвратить несанкционированное копирование диска и его "грабеж" в MP3, в тоже самое время никак не препятствуя его нормальному проигрыванию. Очевидно, что требования, предъявляемые к защите, взаимоисключающие, поскольку, воспроизведение аудиодиска в общем случае его "грабеж" и есть.
Куда подаются "сграбленные" данные (на вход ЦАП или MP3-компрессора) это уже не суть важно, т. к. провод не сообщает диску через какие электронные цепи он его читает (со своим завтраком не разговаривают!)
Правда, на практике все обстоит не совсем так. Бытовые аудио проигрыватели и компьютерные приводы CD-ROM имеют множество конструктивных различий и по разному интерпретируют одну и туже информацию, записанную на CD. Да и сами компьютерные приводы CD-?—ROM'ы'ы чаще всего воспроизводят аудиодиски через специальный аудио-тракт, природа которого заметно отличается от цифрового канала чтения данных. Таким образом, создание защитного механизма сводится к преднамеренному внесению в структуру диска таких искажений, которые бы проявлялись лишь в режиме цифрового "грабежа" данных, а во всех остальных случаях оставались незамеченными.
Как уже говорилось ранеевыше, любые искажения структуры диска, выходящие за рамки стандарта, делают диск нестандартным, а поведение нестандартных дисков на произвольном оборудовании —– непредсказуемо! Причем, обработка нестандартных аудиодисков значительно отличается от обработки нестандартных дисков с данными. Защитный механизм, помещенный в исполняемый файл и, по сути своей являющийся программой, знает все об искажениях формата защищенного диска и знает как его следует обрабатывать. От читающего провода требуется лишь одно —– не мешать и делать то, и только то, что ему скажут. Аудиодиск, обрабатывающийся микропрограммой самого привода, — – это совсем другое дело, ибо представляет не исполняемый код, ано данные и эти данные приходится обрабатывать внешней
программе ("прошивке" привода), которая спроектирована в соответствии со стандартом и любые отклонения от данного вправе трактовать как "non-audio disk or no disk present". Огромное количество "разношерстной" цифровой техники чрезвычайно затрудняет задачу тестирования защитных механизмов на совместимость.
и…
Фактически защита от копирования аудиодисков превращается в защиту от их воспроизведения. Зачастую такие диски отказываются работать даже на обыкновенных аудио плеерах, не говоря уже про компьютерные приводы CD-ROM'ы'ы, на которых если они и воспроизводятся то только через аудио тракт, который мало помалу уже начинает отмирать. Так операционные системы Windows 2000 илиK Windows /XP во всю используют цифровое воспроизведение аудиодисков, а на Mac'ах это, судя по слухам, и вовсе их основной режим. Не собираясь рассуждать о достоинствах цифрового воспроизведения перед аналоговым (это тема совсем другой книги), отметим лишь то, что каждый пользователь вправе сам выбирать наиболее предпочтительный способ прослушивания. А потому, взлом таких защит не то что незаконное, но даже благородное дело!
Компания PHILPS (один из изобретателей технологии CDкомпактов) открыто выступает против любых нарушений стандарта и запрещает маркировать защищенные диски логотипом "CD". Законодательство многих стран (в том числе и России) придерживается такого же мнения. Защищенный нестандартным форматом диск должен содержать недвусмысленное предупреждение, что приобретаемыйая вами кусок пластика только с виду похожа на компакт- диск, но в действительности таковым не является.
Ностальгия
"Во времена Спектрума с дисководом (9х годы) одна фирма, которая выпускала компьютерныйх журнал (не могу вспомнить название за давностью событий) придумала вот что —– на микросхему контроллера дисковода подается определенная тактовая частота, исходя из которой он и оперирует. А поскольку метод записи там MFM, т. е. FM, то от частоты зависит длина дорожки. Обычно (если я правильно помню) длина дорожки была около 6200 байт (это неформатированная длина). Так вот —– эта фирма (наверное, скорее – группа товарищсчей :) делала на диске дорожку длиной, например, 5000 байт (т. е. меньше). За счет ФАПЧ в контроллере она читалась вполне нормально, но длина в 5000 байт сохранялась.
Так вот — такую защиту скопировать было невозможно на стандартном компьютере (это понятно). Но я как раз-то писал именно копировщик таких защищенных дисков… :) И придумал соответственно на время копирования такой — дорожки подключать параллельно кварцу в контроллере КПЕ, крутя который следовало добиваться нужной длины (на экране все отображалось)" Bob Johnson
Методы низкоуровневого управления приводами
"Как правильно уложить парашют"
Пособие. Издание 2-е, исправленное
Секторный уровень взаимодействия всегда привлекал как создателей защитных механизмов, так и разработчиков утилит, предназначенных для копирования защищенных дисков. Еще большие перспективы открывает чтение/запись "сырых" (RAW) секторов — это наиболее низкий уровень общения с диском, какой только штатные приводы способны поддерживать. Большинство защитных механизмов именно так, собственно, и работает. Одни из них прячут ключевую информацию в каналы подкода, другие тем или иным образом искажают коды ECC/EDC коды(Error Correcting Code/Error Detection and Correction)[n2k83] , третьи используют нестандартную разметку и т. д. и т. п.
Существует множество способов для работы с диском на секторном уровне, и далее описаны с добрый десяток из них. Большая часть рассматриваемых здесь методик рассчитана исключительно на Windows NT/2000/XP и не работает в операционных системах Windows 9x, которым, по-видимому, придется разделить судьбу мамонтов, а потому интерес к ним стремительно тает как со стороны пользователей, так и со стороны программистов. Конечно, какое-то время они еще продержатся "на плаву", но в долгосрочной перспективе я бы не стал на них рассчитывать, особенно учитывая тот факт, что Windows 9x не в состоянии поддерживать многопроцессорные системы, а победоносное шествие Hyper-Threading уже не за горами.
Примечание
Технология Hyper-Threading — это реализация одновременной многопоточности (Simultaneous Multi-Threading, SMT). Эта технология фактически является промежуточной между многопоточной обработкой, осуществляемой в мультипроцессорных системах, и параллелизмом на уровне инструкций, осуществляемом в однопроцессорных системах.
В силу того, что секторный уровень доступа к диску изначально ориентирован на создателей ("ломателей") защитных механизмов, данный раздел "выкрашен" ярко-хакерской краской и рассказывает не только о самих методиках низкоуровневого управления устройствами, но и описывает технику взлома каждого из них.
"Как правильно уложить парашют"
Пособие. Издание 2-е, исправленное
Секторный уровень взаимодействия всегда привлекал как создателей защитных механизмов, так и разработчиков утилит, предназначенных для копирования защищенных дисков. Еще большие перспективы открывает чтение/запись "сырых" (RAW) секторов – это наиболее низкий уровень общения с диском, какой только штатные приводы способны поддерживать. Большинство защитных механизмов именно так, собственно, и работает. Одни из них прячут ключевую информацию в каналы подкода, другие тем или иным образом искажают коды ECC/EDC, третьи используют нестандартную разметку и т. д. и т. п.
Существует множество способов для работы с диском на сектором уровне, и ниже будет описан добрый десяток из них. Большая часть рассматриваемых здесь методик рассчитана исключительно на Windows NT/W2K/XP и не работает в операционных системах Windows 9x, которымой, по-видимому, придется разделить судьбу мамонтов, а потому интерес к нимей стремительно тает как со стороны пользователей, так и со стороны программистов. Конечно, какое-то время ониа еще продержитсяпродержатся на плаву, но в долгосрочной перспективе я бы не стал на нихее закладываться, особенно учитывая тот факт, что Windows 9x не в состоянии поддерживать многопроцессорные системы, а победоносное шествие Hyper-Threading уже не за горами.
В силу того, что секторный уровень доступа к диску изначально ориентирован на создателей (ломателей) защитных механизмов, данный раздел выкрашен ярко-хакерской краской и рассказывает не только о самих методиках низкоуровневого управления устройствами, но и описывает технику взлома каждого из них. Забегая вперед, заметим, что сломать можно все!
Замечание
На самом деле, это утверждение не совсем верно. Некоторые из защит от копирования на бытовом оборудовании не могут быть взломаны в принципе. В частности, защиты аудиодисков, основанные на искажении TOC'a, приводят к нечитабельности такого диска компьютерными приводами CD-ROM, но на аудио-плеерах, не слишком дотошно анализирующих TOC, такой диск воспроизводится вполне нормально. Единственный способ скопировать такой диск в цифровом виде – пропадчить прошивку CD-ROM привода, убрав из нее ряд "лишних" проверок, либо же развинтить привод для осуществления горячей замены диска. Подробнее см. xxxx
Так что не стоит, право же, переоценивать стойкость механизмов, препятствующих несанкционированному копированию лазерных дисков. Если кому-то особо приспичит, вашу программу все равно взломают! Как? Вот об этом и будет рассказано ниже. Как говориться: кто предупрежден, – тот вооружен. Ну, а коль уж совсем невмоготу – используйте прямой доступ к портам ввода/вывода с прикладного уровня. Нет, вы не ослышались – в Windows NT это действительно возможно, и ниже будет рассказано как это сделать.
Забегая вперед, отметим, что сломать
Забегая вперед, отметим, что сломать можно все!
Замечание
На самом деле, это утверждение не совсем верно. Некоторые из защит от копирования на бытовом оборудовании не могут быть взломаны в принципе. В частности, защиты аудиодисков, основанные на искажении TOC (Table Of Contents), приводят к нечитабельности такого диска компьютерными приводами CD-ROM, но на аудио-плеерах, не слишком дотошно анализирующих TOC, такой диск воспроизводится вполне нормально. Единственный способ скопировать такой диск в цифровом виде — изменить код прошивки привода CD-ROM, убрав из него ряд "лишних" проверок, либо же развинтить привод для осуществления "горячей" замены диска. Подробнее см. xxxx[Y84] .
Так что не стоит, право же, переоценивать стойкость механизмов, препятствующих несанкционированному копированию лазерных дисков. Если кому-то особо приспичит, вашу программу все равно взломают! Как? Вот об этом и рассказано далее. Как говориться: кто предупрежден, — тот вооружен. Ну, а коль уж совсем невмоготу, то используйте прямой доступ к портам ввода/вывода с прикладного уровня. Нет, вы не ослышались — в Windows NT это действительно возможно, и далее рассказано как это сделать.
Microsoft Visual Studio Debugger
При установке среды разработки MicrosoftVisual Studio она регистрирует свой отладчик основным отладчиком критических ошибок по умолчанию. Это простой в использовании, но функционально ущербный отладчик, не поддерживающий даже такой банальной операции, как поиск hex-последовательности в оперативной памяти. Единственная "вкусность", отличающая его от "продвинутого" во всех отношениях Microsoft Kernel Debugger'a –— это возможность трассировки "упавших" процессов, выбросивших критическое исключение.
В опытных руках отладчик Microsoft Visual Studio Debugger способен творить настоящие чудеса, и одно из таких чудес –— это возобновление работы приложений, совершивших недопустимую операцию и при нормальном течении событий аварийно завершаемых операционной системой без сохранения данных. В любом случае, интерактивный отладчик (коим Microsoft Visual Studio Debugger и является) предоставляет намного более подробную информацию о сбое и значительно упрощает процесс выявления источников его возникновения. К сожалению, тесные рамки данной главы (и без того далеко отошедшей от основной темы книги!) не позволяют изложить всю методику поиска неисправностей целиком и приходится ограничиваться лишь узким кругом наиболее интересных (и наименее известных!) вопросов (см. разд. "Обитатели сумеречной зоны, или из морга в реанимацию" этой главы).
Для ручной установки Microsoft Visual Studio Debugger'а основным отладчиком критических ошибок добавьте в реестр следующие данные показанные в листинге 3.3.:
Листинг 3.3. Установка Microsoft Visual Studio Debugger основным отладчиком критических ошибок
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\AeDebug]
"Auto"="1"
"Debugger"="\"C:\\Prg Files\\MS VS\\Common\\MSDev98\\Bin\\msdev.exe\" -p %ld -e %ld"
"UserDebuggerHotKey"=dword:00000000
Листинг 3.4. Демонстрационная [Y88] программа, вызывающая сообщение о критической ошибкеЛистинг 3 установка Microsoft Visual Studio Debugger' a основным отладчиком критических ошибок
// функция возвращает сумму n символов типа char
// если ей передать null-pointer, она "упадет",
// хотя источник ошибки не в ней, а в аргументах,
// переданных материнской функцией
test(char *buf, int n)
{
int a, sum;
for (a = 0; a < n; a++) sum += buf[a]; // здесь возбуждается исключение
return sum;
}
main()
{
#define N 100
char *buf = 0; // инициализируем указатель на буфер
/* buf = malloc(100); */ // "забываем" выделить память, здесь ошибка
test(buf, N); // передаем null-pointer некоторой функции
}
Миссия: Искажение нумерации треков
Согластно стандартру ECMA-130, информационные треки должны нумероваться последовательно, начиная от единицы и кончая последним треком диска ("Track Numbers 01 to 99 shall be those of the Information Tracks in the User Data area. Consecutive Information Tracks shall be numbered consecutively. The first Information Track of the user Data area of a disk shall have Track Number 01"). Чувство здравого смысла разработчиков аппаратно-программного обеспечения придерживается такого же мнения и потому считается, что всякая система может закладываться на то, что за треком номер один следует либо трек с номером два, либо область Lead-outLead-Out (трек с номером AAh). Но ведь нумерация треков может быть легко искажена с таким расчетом, чтобы за первый треком располагался девятый или даже еще один "первый" трек!
Испытания показывают, что подавляющее большинство приводов и копировщиков на перенумерацию треков реагируют крайне неадекватно, порой вообще отказываясь распознавать такой диск или же отображая треки с данными как аудио. Неудивительно, что копирование искаженных дисков вызывает большие проблемы. Даже такие "зубры" как Clone CDCloneCD и Alcohol 120% Алкоголь оказывается не в состоянии разобраться с разметкой защищенного диска и полученные копии оказываются чудовищно искажены или же вовсе неработоспособны.
Теоритически, диск с нарушенной нумераций треков должен копироваться без проблем, поскольку номера треков в абсолютной адресации вообще не участвуют и при работе с диском на секторном уровне копировщику достаточно лишь прочитать все содержимое диска от первого читаемого сектора до последнего, даже не подозреваяя о сущестовании треков вообще. Тем не менее, на практике все обстоит иначе и подавляющее большинство копировщиков копируют диск по трекам, а не по секторам. Причем, алгоритмы анализа TOC'a зачастую тупы до ужаса и не способны справиться даже с очевидными искажениями. Любые отклонения нумерации треков от нормальной нормально вполне записываются на диск тем же Clone CDCloneCD (за исключением трека, начинающегося с номера ноль, но об этом мы поговорим позже), но для чтения искаженного диска понадобиться программа "поумннее".
Из всех известных мне программ на это способен лишь мой собственный копировщик (ну или посекторное копирование диска "вручную"), так что для защиты дисков этаот методикапримчик —– самое то!
Однако, чтобы защищенный диск не вызывал никаких конфликтов с оборудованием легальных пользователей, следует дейстовать очень осторожно, ни в коем случае не прикасаясь к нумерации треков первой сессии (т. к. зачастую это ведет к полной нечитаемости диска, подробности вы найдете далее в одноименномй разд. главе ниже"Диск, начинающийся не с первого трека" этой главы). Приятное исключение составляет лишь создание фиктивного трека с номером подлинного трека, —– защита этого типа не конфликтует ни с каким доступным мне оборудованим и, судя по всему, не должна конфликтовать ни с каким оборудованием вообще, однако, полной уверенности в этом у меня нет. Нумерацию треков второй сессии можно изменять более или менее безболезненно. В худшем случае привод просто не "увидит" треки второй сессии, но первая сессия будет доступа ему целиком.
Для изменения нумерации треков достаточно лишь изменить номер указателяpoint'а, соответствующий оригинальному номеру искажаемого трека и скорректировать значение поля PMin указателяpoint'а A1h, хранящего номер последнего трека диска (если этого не сделать, то мы получим защиту типа "некорректный номер последнего трека"). Так же следует исправить раскладку треков, содержащуюся в конеце CCD-файла. Следующий пример (листинг 6.28) демонстрирует как создать разрыв между вторым и третьим треками, увеличив номер последнего с трех до девяти. Нечетные колонки, залитые серым цветом — оригинальное содержимое CCD-файла, справа приведены измененные колонки (непосредственно сами изменения выделены полужирным шрифтом):
Листинг 6.28. Образование разрыва между вторым и третьим треками.
|
[Entry 8] |
[Entry 8] |
[Entry 11] |
[Entry 11] |
[TRACK 1] |
[TRACK 1] |
|
Session=2 |
Session=2 |
Session=2 |
Session=2 |
MODE=1 |
MODE=1 |
|
Point=0xa1 |
Point=0xa1 |
Point=0x03 à |
Point=0x09 |
INDEX 1=0 |
INDEX 1=0 |
|
ADR=0x01 |
ADR=0x01 |
ADR=0x01 |
ADR=0x01 |
||
|
Control=0x04 |
Control=0x04 |
Control=0x04 |
Control=0x04 |
[TRACK 2] |
[TRACK 2] |
|
TrackNo=0 |
TrackNo=0 |
TrackNo=0 |
TrackNo=0 |
MODE=1 |
MODE=1 |
|
AMin=0 |
AMin=0 |
AMin=0 |
AMin=0 |
INDEX 1=0 |
INDEX 1=0 |
|
ASec=0 |
ASec=0 |
ASec=0 |
ASec=0 |
||
|
AFrame=0 |
AFrame=0 |
AFrame=0 |
AFrame=0 |
[TRACK 3] à |
[TRACK 9] |
|
ALBA=-150 |
ALBA=-150 |
ALBA=-150 |
ALBA=-150 |
MODE=1 |
MODE=1 |
|
Zero=0 |
Zero=0 |
Zero=0 |
Zero=0 |
INDEX 1=0 |
INDEX 1=0 |
|
PMin=3 à |
PMin=9 |
PMin=3 |
PMin=3 |
||
|
PSec=0 |
PSec=0 |
PSec=1 |
PSec=1 |
||
|
PFrame=0 |
PFrame=0 |
PFrame=33 |
PFrame=33 |
||
|
PLBA=8850 |
PLBA=-1 |
PLBA=13458 |
PLBA=13458 |
[Entry 8] [Entry 8] [Entry 11] [Entry 11] [TRACK 1] [TRACK 1]
Session=2 Session=2 Session=2 Session=2 MODE=1 MODE=1
Point=0xa1 Point=0xa1 Point=0x03 à Point=0x09 INDEX 1=0 INDEX 1=0
ADR=0x01 ADR=0x01 ADR=0x01 ADR=0x01
Control=0x04 Control=0x04 Control=0x04 Control=0x04 [TRACK 2] [TRACK 2]
TrackNo=0 TrackNo=0 TrackNo=0 TrackNo=0 MODE=1 MODE=1
AMin=0 AMin=0 AMin=0 AMin=0 INDEX 1=0 INDEX 1=0
ASec=0 ASec=0 ASec=0 ASec=0
AFrame=0 AFrame=0 AFrame=0 AFrame=0 [TRACK 3] à [TRACK 9]
ALBA=-150 ALBA=-150 ALBA=-150 ALBA=-150 MODE=1 MODE=1
Zero=0 Zero=0 Zero=0 Zero=0 INDEX 1=0 INDEX 1=0
PMin=3 à PMin=9 PMin=3 PMin=3
PSec=0 PSec=0 PSec=1 PSec=1
PFrame=0 PFrame=0 PFrame=33 PFrame=33
PLBA=8850 PLBA=-1 PLBA=13458 PLBA=13458
Листинг 20 образование разрыва между вторым и третьим треками; нечтные колонки, залитые серым цветом – оригинальное содержимое CCD-файла, справа приведены измененные колонки (непосредственно сами изменения выделены жирным шрифтом).
Поскольку, большинство дисков с данными имеют лишь по одному треку на каждую сессию, то для перенумерации треков в границе одной сессии обычно приходится прибегать к созданию фиктивного трека в настоящем. Эта методика уже рассматривалась ранеевыше (см. разд. "Фиктивный трек в настоящем треке" этой главыодноименную главу) и здесь мы не будем повторяться.
