Дисковод CD-ROM
Довольно легко заставить Linux проигрывать для вас CD диски: все, что вам нужно — это дисковод CD-ROM, колонки или наушники, CD-диск с музыкой и немного трудолюбия. Если вы устанавливали Linux на компьютер, в котором уже стоял CD-дисковод, то все необходимые настройки, скорее всего, сделаны автоматически. Если же вы поставили CD-ROM после установки Linux, то надо научить Linux распознавать этот дисковод. Для этого в каталоге /dev должна иметься ссылка (линк) на устройство. Если ее нет, создайте, выполнив следующие команды:
[root]# cd /dev
[root]# ln -s hdc cdrom
где вместо hdc вы, естественно, должны указать ваш CD-дисковод. Если не знаете, что тут указать, то внимательно просмотрите те сообщения, которые Linux выдает при загрузке. Для этого не требуется перезагружаться, протокол загрузки сохранен в файле /var/log/dmesg и выдается на экран по команде dmesg.

Рис. 9.12. CD Player
После этого можно запустить программу управления проигрыванием CD-дисков, например xplaycd. В графической оболочке KDE имеется простой проигрыватель CD-дисков с названием "CD Player" (рис. 9.12). Вызвать его можно через меню оболочки KDE.
Драйверы устройств
Как уже говорилось выше, одной из основных задач операционной системы является управление аппаратной частью. Ту программу или тот кусок программного кода, который предназначен для управления конкретным устройством, и называют обычно драйвером устройства. Необходимость драйверов устройств в операционной системе объясняется тем, что каждое отдельное устройство воспринимает только свой строго фиксированный набор специализированных команд, с помощью которых этим устройством можно управлять. Причем команды эти чаще всего предназначены для выполнения каких-то простых элементарных операций. Если бы каждое приложение вынуждено было использовать только эти команды, писать приложения было бы очень сложно, да и размер их был бы очень велик. Поэтому приложения обычно используют какие-то команды высокого уровня (типа "записать файл на диск"), а о преобразовании этих команд в управляющие последовательности для конкретного устройства заботится драйвер этого устройства. Поэтому каждое отдельное устройство, будь то дисковод, клавиатура или принтер, должно иметь свой программный драйвер, который выполняет роль транслятора или связующего звена между аппаратной частью устройства и программными приложениями, использующими это устройство.
В Linux драйверы устройств бывают трех типов.
Драйверы первого типа являются частью программного кода ядра (встроены в ядро). Соответствующие устройства автоматически обнаруживаются системой и становятся доступны для приложений. Обычно таким образом обеспечивается поддержка тех устройств, которые необходимы для монтирования корневой файловой системы и запуска компьютера. Примерами таких устройств являются стандартный видеоконтроллер VGA, контроллеры IDE-дисков, материнская плата, последовательные и параллельные порты.
Драйверы второго типа представлены модулями ядра. Они оформлены в виде отдельных файлов и для их подключения (на этапе загрузки или впоследствии) необходимо выполнить отдельную команду подключения модуля, после чего будет обеспечено управление соответствующим устройством. Если необходимость в использовании устройства отпала, модуль можно выгрузить из памяти (отключить). Поэтому использование модулей обеспечивает большую гибкость, так как каждый такой драйвер может быть переконфигурирован без остановки системы. Модули часто используются для управления такими устройствами как SCSI-адаптеры, звуковые и сетевые карты.
Файлы модулей ядра располагаются в подкаталогах каталога /lib/modules. Обычно при инсталляции системы задается перечень модулей, которые будут автоматически подключаться на этапе загрузки. Список загружаемых модулей хранится в файле /etc/modules. А в файле /etc/modules.conf находится перечень опций для таких модулей. Редактировать этот файл "вручную" не рекомендуется, для этого существуют специальные скрипты (типа update-modules).
Для подключения или отключения модулей в работающей системе имеются специальные утилиты.
lsmod — выдает список загруженных в данный момент модулей.
insmod — служит для загрузки или "установки" модуля из командной строки.
Пример:
insmod joystick
rmmod — служит для выгрузки или "удаления" модуля .
Пример:
rmmod joystick
modprobe — автоматически загружает модули. Для того, чтобы отобразить текущую конфигурацию всех модулей можно воспользоваться командой: modprobe –c.
Примечание
Хотя файлы модулей имеют суффикс .o, при использовании этих команд ссылки на модули указываются без упоминания этого суффикса. Например: при упоминании модуля, файл которого называется "joystick.o", вы должны использовать в командной строке просто "joystick".
И, наконец, для третьего типа драйверов устройств программный код драйвера поделен между ядром и специальной утилитой, предназначенной для управления данным устройством. Например, для драйвера принтера ядро отвечает за взаимодействие с параллельным портом, а формирование управляющих сигналов для принтера осуществляет демон печати lpd (который использует для этого специальную программу-фильтр, о чем подробнее будет рассказано ниже, в разд. 9.6). Другие примеры драйверов этого типа — драйверы модемов и X-сервер (драйвер видеоадаптера), о котором шла речь в главе 7.
Но надо специально отметить, что во всех трех случаях непосредственное взаимодействие с устройством осуществляет ядро или какой-то модуль ядра. А пользовательские программы взаимодействуют с драйверами устройств через специальные файлы, расположенные в каталоге /dev и его подкаталогах. То есть взаимодействие прикладных программ с аппаратной частью компьютера в ОС Linux осуществляется по следующей схеме:
устройство <-> ядро <-> специальный файл устройства <-> программа пользователя
Такая схема обеспечивает единый подход ко всем устройствам, которые с точки зрения приложений выглядят как обычные файлы.
Файл /etc/printcap
Файл /etc/printcap — это главная база данных системы печати LPD. Принтер будет получать задания на печать только в том случае, если он (принтер) описан в этом файле. Поэтому для получения возможности использовать принтер вы должны добавить очередь печати к lpd, т. е. создать новый буферный подкаталог в каталоге /var/spool/lpd и добавить соответствующую запись в файл /etc/printcap.
Запись в файле /etc/printcap выглядит примерно так:
# ЛОКАЛЬНЫЙ djet500
lp|dj|deskjet:\
:sd=/var/spool/lpd/dj:\
:mx#0:\
:lp=/dev/lp0:\
:sh:
Каждый элемент файла /etc/printcap начинается со строки, задающей имена принтера (их может быть несколько), разделяемые вертикальной чертой. Затем следует ряд параметров конфигурации, разделенных двоеточиями (обычно каждый параметр заключается в двоеточия с обеих сторон). Каждый параметр имеет вид xx=строка или xx#число, где xx — двухсимвольное имя параметра, а строка и число — присваиваемые ему значения. Если никакого значения не присваивается, переменная является булевой, и ее присутствие означает "истина". Допускаются пустые операторы: два рядом стоящих двоеточия. Строки, начинающиеся символом #, содержат комментарий. Обратная косая черта в конце строки означает, что в следующей строке идет продолжение текущей строки.
Приведенный выше пример записи определяет принтер называемый lp, dj, или deskjet, его спул размещается в директории /var/spool/lpd/dj, максимальный размер задания не имеет ограничения, печать производится на устройство /dev/lp0, и страница с заголовком (с именем пользователя, который отправил задание на печать, и другой информацией) не добавляется в начало задания печати.
Подробнее о том, как создавать такие записи, можно прочитать на справочной странице для printcap. Но о некоторых самых важных (и обязательных) параметрах стоит рассказать здесь, хотя бы просто для примера.
sd=буферный_каталог. У каждого принтера должен быть свой буферный каталог. Все буферные каталоги должны находиться в одном каталоге (обычно это /var/spool/lpd) и иметь имена, совпадающие с полными именами обслуживаемых ими принтеров. Буферный каталог нужен даже в том случае, если описываемый принтер подключен к другой машине: задания находятся на локальной машине до тех пор, пока они не будут переданы на печать.
lp=имя_устройства. В таком виде этот параметр должен задаваться только для локального принтера. Если принтер находится на другой машине, вместо имени устройства указывается имя уникального файла, который существует и расположен на локальном диске. Чтобы принтер мог возвращать через указанный файл информацию о своем состоянии, необходимо задать в элементе булеву переменную rw, чтобы устройство было открыто и для чтения, и для записи.
rm и rp. Во многих случаях в качестве печатающего устройства используется сетевой принтер, подключенный к какому-то другому компьютеру в локальной (или даже глобальной) сети. В таком случае на вашей машине в файле /etc/printcap должны присутствовать две переменные rm и rp. В переменной rm определяется машина, на которую должны посылаться задания, а переменная rp задает имя принтера на этой машине.
mx. Переменная mx используется для задания максимального размера (в байтах) печатаемого файла. Этот параметр может использоваться системными администраторами для того, чтобы предотвратить отрицательные последствия распространенной ошибки начинающих пользователей, состоящей в посылке на печать двоичных файлов (которые обычно имеют большую длину). Поскольку такие файлы могут содержать произвольные символы, в том числе символы, которые служат в качестве управляющих команд для принтера, печать двоичных файлов может приводить, например, к неоправданному расходованию бумаги и другим неприятным последствиям. На локальном принтере персонального компьютера этот параметр можно и не задавать. Я привел его для того, чтобы отметить, что для этого параметра, как и для всех других числовых параметров, значение должно отделяться от имени параметра знаком #, например, mx#0. Если написать mx=0, то такая запись не вызовет сообщений об ошибке, но она не изменяет значения переменной mx.
Еще один очень существенная группа параметров — это параметры of, if и nf. Но о них надо поговорить особо, что мы и сделаем чуть ниже в подразделе "Фильтры". Однако вначале рассмотрим программу, которая позволяет осуществить настройку принтера и создать файл /etc/printcap/.
Фильтры
Когда задание на печать дождется своей очереди, lpd создает ряд программных каналов между буферным файлом и печатающим устройством для передачи данных, подлежащих печати. Посередине этой цепочки lpd устанавливает процесс-фильтр, в задачи которого входит просмотр и дополнительная обработка потока данных, направляемых на принтер. Процессы-фильтры могут выполнять над данными различные преобразования, в частности, форматирование и поддержку различных протоколов, которые могут понадобиться для работы с данным принтером.
Фильтр — это, как правило, просто сценарий shell, который вызывает ряд конвертирующих программ. Фильтр можно указать в командной строке вызова программы lpr. Если в командной строке фильтр не указан, то используются фильтры, заданные параметрами if, of и nf соответствующей записи в файле /etc/printcap. Если в этой записи присутствует переменная if, а параметра of нет, то устройство (принтер) будет открываться один раз для каждого задания, а фильтр будет посылать одно задание на принтер и завершать работу. Если есть of, а if нет, то lpd однократно откроет устройство и вызовет программу-фильтр для посылки сразу всех заданий, стоящих в очереди. Это полезно для печати на тех устройствах, соединение с которыми требует большого времени. Одновременного использования параметров of и if следует избегать, а из двух предыдущих вариантов рекомендуется выбирать использование параметра if. Соответствующий элемент в записи файла /etc/printcap может иметь примерно такой вид:
:if=/var/spool/lpd/dj/filter:\
Если никакого фильтра вообще не задано, то вывод на печать может выглядеть очень некрасиво. Например, при печати обычного текстового файла вывод может выглядеть примерно так:
This is line one.
This is line two.
This is line three.
Печать файла в формате PostScript выдаст листинг команд PostScript, напечатанных с этим "лестничным эффектом", а не полезный вывод. В руководстве "Printing HOWTO" приводится следующий пример простого фильтра, предназначенного только для того, чтобы устранить "лестничный эффект":
#!perl
# Предыдущая строка должна содержать полный путь к perl
# Скрипт должен быть исполнимым: chmod 755 filter
while(<STDIN>){chop $_; print "$_\r\n";};
# вы можете также добавить в конец прогон страницы: print "\f";
Этот текст надо сохранить в виде файла /var/spool/lpd/dj/filter, после чего будут нормально печататься обычные текстовые файлы.
Но печать простых ASCII-файлов — это только частный случай печати. В большинстве случаев в настоящее время печатаются файлы в других форматах, например, PostScript. Проблема вывода таких файлов на печать тоже решается путем использования фильтра, только гораздо более сложного. Таких фильтров разработано уже достаточно много, но самый важный из них — программа ghostscript.
Форматирование жесткого диска
Низкоуровневое форматирование жесткого диска под Linux невозможно. Впрочем, в этом нет особой необходимости, поскольку современные диски выпускаются отформатированными на низком уровне.
Форматирование на высоком уровне заключается в создании на диске разделов и файловой системы. Для создания разделов под Linux используются программы fdisk, cfdisk и sfdisk. Как сообщает man-страница к программе fdisk, программа cfdisk позволяет создать качественную таблицу разделов, но имеет некоторые ограничения. Программа fdisk, хотя и позволяет произвести разбиение диска в большинстве случаев, но содержит несколько ошибок. Ее главное преимущество в том, что она поддерживает разделы DOS, BSD и других систем. Программа sfdisk работает более корректно, чем fdisk, и она гораздо мощнее и fdisk, и cfdisk, но имеет неудобный пользовательский интерфейс. Так что man-страница рекомендует пытаться применять эти программы в следующем порядке: cfdisk, fdisk, sfdisk.
Однако, на мой взгляд, интерфейс любой из этих программ не предназначен для начинающих пользователей. Поэтому для создания разделов на диске я бы рекомендовал использовать программу Partition Magic фирмы Power Qwest. Несколько слов о ней было сказано в главе 2, как и о разбиении диска, поэтому на этом вопросе более не будем останавливаться.
После разбиения диска на разделы надо создать файловую систему в разделах, предназначенных для использования под Linux,. Для этого используется команда mkfs. С ее помощью можно создать не только файловую систему типа ext2fs, но и файловые системы других типов. Типичный пример запуска этой команды:
[root]# mkfs –t тип /dev/hda3
где тип — тип создаваемой файловой системы, например, ext2, а /dev/hda3 — указание форматируемого раздела диска ().
Чтобы использовать mkfs, не обязательно иметь права суперпользователя, достаточно иметь право записи в файл соответствующего устройства.
Внимание!
Команда mkfs очень опасна! Она перезаписывает область диска, в которой хранятся inodes. Так что если вы ошибетесь в указании раздела диска, вы можете уничтожить ценные для вас данные.
После создания файловой системы ее надо смонтировать в общее дерево каталогов. Делается это с помощью команды mount, которую мы уже рассматривали, так что повторяться не стоит. Единственное, что можно отметить, так это то, что смонтировав первый раз диск или раздел, в котором вы только что создали файловую систему, вы увидите, что она пуста, т. е. не содержит никаких файлов и каталогов, кроме единственного каталога с именем lost+found. Этот каталог должен существовать в каждой файловой системе, поскольку он выполняет служебную роль: при проверке файловой системы командой fsck в этом каталоге собираются "потерянные" файлы и подкаталоги. О команде fsck мы еще поговорим, но до этого рассмотрим кратко вопрос об оптимизации работы жесткого диска, которая выполняется с помощью команды hdparm.
Изменение раскладки клавиатуры для текстового режима
В дистрибутиве Red Hat загрузка таблицы раскладки клавиатуры и системного фонта производится в файле /etc/rc.d/rc.sysinit. Но лезть в этот файл и корректировать его содержимое для изменения раскладки не требуется. Дело в том, что файлы с различными раскладками находятся в каталоге /lib/kbd/keymaps/i386/qwerty или /usr/lib/kbd/keymaps/i386/qwerty, а выбор конкретного файла раскладки задается файлом /etc/sysconfig/keyboard. Этот файл можно отредактировать вручную, а можно — с помощью программы kbdconfig.
Команда kbdconfig прописывает новое значение в файл /etc/sysconfig/keyboard и загружает указанную таблицу в оперативную память. Того же эффекта можно добиться, если прописать имя новой таблицы в файл /etc/sysconfig/keyboard и выполнить команду
[root]# /etc/rc.d/init.d/keytable start
Оба этих варианта позволяют переключиться на новую раскладку "на ходу".
Если же только откорректировать содержимое файла /etc/sysconfig/keyboard, то перезагрузка таблицы произойдет только после перезапуска компьютера или после выполнения команды (в примере загружается раскладка из файла ru-win.map):
[root]# loadkeys /usr/lib/kbd/keymaps/i386/qwerty/ru-win.map
Впрочем, переключение "на ходу" вряд ли требуется делать, поскольку обычно человек привыкает к одной раскладке, и пальцы сами находят привычные клавиши, так что всякое изменение тут только осложнит работу. Поэтому имеет смысл поэкспериментировать один раз с различными раскладками, выбрать наиболее удобную (считай, привычную) и на этом можно успокоиться.
При установке русифицированных дистрибутивов Linux (по крайней мере Black Cat) обычно выбирается раскладка ru1 (точка на <Shift>+<7>, запятая на <Shift>+<6>). Для тех, кто привык работать в Windows, может оказаться более привычной раскладка как в Windows (в русском регистре точка и запятая находятся рядом с правой кнопкой <Shift>). Для таких пользователей имеется раскладка ru_ms. Если вас не удовлетворяют эти варианты, то можете выбрать любую из имеющихся в вашей системе, либо найти что-либо подходящее в Интернет. Предположим, что вы нашли и скачали файл ru_win_ctrl.map.gz от IP Labs (http://www.iplabs.ru/Linux/ru_win_ctrl.map.gz). Остается только положить этот файл в /usr/lib/kbd/keytables/i386/qwerty/, запустить kbdconfig и выбрать ru_win_ctrl.
После установки новой таблицы раскладки клавиатуры иногда возникают затруднения в определении того, какая именно клавиша или комбинация клавиш переключает из режима ввода английских символов в режим ввода русских. Гадать тут не надо, достаточно просмотреть файл таблицы раскладки клавиатуры. Обычно в самом начале файла эта комбинация указывается открытым текстом, правда, в большинстве случаев английским. (Если вы забыли, какая именно таблица загружена, то посмотрите файл /etc/sysconfig/keyboard).
Клавиатура
Клавиатура к вашему компьютеру уже, скорее всего, подключена, вопрос может состоять только в том, чтобы настроить ее. Настройка клавиатуры заключается в настройке таких вещей, как: раскладка клавиатуры; скорость повтора посылаемых клавиатурой сигналов в случае удержания клавиш пользователем; длительность интервала задержки от момента нажатия клавиши до того момента, когда клавиатура начинает повторять посылку сигналов.
Два последних параметра (скорость повтора и время задержки) устанавливаются с помощью специальной команды kbdrate.
Команда fsck
Описание команды fsck, наверное, правильное было бы отнести к разделу о файловых системах, но, поскольку ее предназначение состоит в том, чтобы по возможности восстановить работоспособность дисковой подсистемы, мы рассматриваем ее в разделе о настройке жесткого диска.
Основная функция программы fsck заключается в восстановлении логической непротиворечивости файловой системы, созданной в разделе жесткого диска. При выполнении этой команды производится поиск следующих ошибок: сектора, которые используются одновременно двумя файлами; сектора, которые включены в список свободных секторов, хотя они содержат часть какого-то файла; сектора, которые не содержат информации, но не включены в список свободных секторов; индексные дескрипторы файлов (inodes), не указанные ни в одном каталоге; неверная общая информация в суперблоке и т. д.
Формат запуска команды следующий:
[root]# fsck [опции] [–t fstype] [--fs-options] filesystem
где fstype — тип проверяемой файловой системы, а в качестве filesystem можно указать либо имя устройства (например, /dev/hda4), либо точку монтирования (/, /opt, /mnt/wint) (Примечание: в man-странице по fsck сказано, что можно еще использовать метку (label) файловой системы, либо UUID, но, что такое два последних варианта, я пояснить не берусь).
Вообще говоря, команда fsck не является самостоятельной утилитой, она просто предоставляет единый интерфейс вызова специализированных программ для проверки файловых систем разных типов. Эти программы называются fsck.fstype (например, fsck.ext2) и команда fsck при запуске производит поиск соответствующей специфической программы сначала в /sbin, затем в /etc/fs и /etc, и, наконец, в каталогах, перечисленных в переменной PATH. Опции, указанные после двойного дефиса, передаются команде fsck.fstype.
Из собственных опций команды fsck (они указываются сразу после имени) стоит отметить опции –A, –a, –r и –N. Если указать опцию –a, то при обнаружении ошибок в файловой системе будет производиться их автоматическое исправление. Указание опции –A приводит к тому, что команда просмотрит файл /etc/fstab и за один прогон проверит все перечисленные в нем файловые системы. Опция –r переключает команду в интерактивный режим работы, т. е. перед тем, как произвести какие-то изменения, будет выдаваться запрос на подтверждение действия. Задание опции –N приводит к тому, что никаких изменений в файловой системе производится не будет, будет только сказано, что должно быть сделано.
При загрузке ОС Linux в некоторых случаях происходит автоматический запуск команды fsck. Основных причин для выполнения fsck на этапе загрузки системы две: некорректный выход из системы в предыдущий раз (например, резкое отключение питания или неисправность аппаратуры) и достижение заданного порога для количества выполнений операции размонтирования файловой системы. При каждом выполнении операций монтирования-размонтирования файловой системы в ее суперблоке (см. главу 16) делаются специальные отметки. Если последнее размонтирование завершилось корректно, то файловая система помечается как "чистая" (clean) и число операций монтирования-размонтирования увеличивается на единицу. Если корректного размонтирования не было, то файловая система помечена как "грязная" (dirty). На этапе загрузки ОС проверяется, являются ли все файловые системы "чистыми", и если нет, то для "грязных" систем выполняется команда fsck. Кроме того, даже если все системы "чистые", но достигнут порог для числа операций монтирования/размонтирования, запускается та же команда с опцией –A. Как было сказано выше, при этом производится проверка всех файловых систем, перечисленных в файле /etc/fstab. Порядок, в котором проверяются файловые системы, определяется числами, указанными в последнем поле каждой строки файла /etc/fstab. Файловые системы проверяются в порядке возрастания этих номеров. Первым всегда следует проверять корневой раздел. Если две файловые системы расположены на разных дисках, им может быть присвоен один и тот же номер. Это приводит к тому, что они будут проверяться одновременно, а, значит, сократится общее время проверки. Но если файловые системы расположены на одном и том же физическом устройстве (например, в разных разделах), то совпадение номеров вызовет только замедление процедуры проверки, так как головки диска должны будут совершать лишние перемещения.
Иногда требуется запустить fsck и вручную. При этом лучше всего предварительно перевести систему в однопользовательский режим и размонтировать проверяемые файловые системы (или смонтировать их в режиме "только для чтения"). Например, запуск fsck в разделе /usr обычно требуется тогда, когда файловая система разрушена и тогда любые дальнейшие действия в разрушенной системе могут привести к полному краху, а, значит, fsck должна быть запущена как можно скорее. Обычно о необходимости перехода в однопользовательский режим говорит также то, что fsck не может автоматически восстановить файловую систему при загрузке. Такое случается относительно редко, обычно при выходе из строя жесткого диска или при попытках установить какую-либо экспериментальную версию ядра, но все же об этом надо знать, чтобы не растеряться в затруднительной ситуации.
К сожалению, в процессе восстановления файловой системы приходится полностью полагаться на возможности программы fsck. Начинающему пользователю не стоит самостоятельно пытаться произвести какие-то действия в поврежденной файловой системы, потому что вы рискуете перевести ядро в паническое состояние (kernel panic).
Если fsck обнаруживает "потерянные файлы", т. е. такие файлы, которые не указаны ни в одном из каталогов, она помещает их в каталог lost+found на верхнем уровне проверяемой файловой системы. Поскольку имена файлов регистрируются только в родительском каталоге, то в данном случае их "истинные" имена неизвестны, и команда присваивает им имена, совпадающие с номерами их индексных дескрипторов.
Команда hdparm
Команда hdparm служит для того, чтобы получить или установить некоторые параметры IDE-интерфейса жесткого диска (ов). С помощью этой команды можно попытаться оптимизировать работу с жестким диском. Однако имейте в виду, что команда эта не безопасна. Если задать значение параметра, которое не поддерживается аппаратным обеспечением, можно потерять данные на диске.
Данные о том, в каких случаях стоит использовать эту команду, весьма противоречивы. Одни авторы уверяют, что с ее помощью добиться чуть ли не 10-кратного увеличения скорости обмена данными с жестким диском, другие утверждают, что можно потратить много времени на настройку интерфейса жесткого диска, а в результате получить лишь незначительное увеличение скорости работы. По-видимому, получаемый выигрыш определяется, в основном, моделью жесткого диска, так что сами решайте, имеет ли смысл этим заниматься. Но, как утверждает Rob Flickenger , если у вас IDE или EIDE диск, выпущенный не более 2 лет назад, то заняться оптимизацией стоит!
Экспериментировать с этой командой рекомендуется получив права суперпользователя, причем лучше, если система запущена в однопользовательском режиме. Поскольку существует опасность потери данных, перед использованием команды hdparm необходимо сделать резервную копию ценной информации, и каждый раз перед ее запуском выполнять команду sync, чтобы сбросить на диск данные, находящиеся временно в буферах.
Формат запуска команды прост:
[user]$ hdparm опция устройство
Если после указания опции не указывать нового значения для соответствующего параметра, то будет просто выдано его действующее значение. А если запустить команду без указания опций вообще, то будут выведены значения основных параметров, действующих при работе с данным устройством (IDE-диском). Вывод выглядит примерно следующим образом:
[user]$ hdparm /dev/hda
/dev/hda:
multcount = 0 (off)
I/O support = 0 (default 16-bit)
unmaskirq = 0 (off)
using_dma = 0 (off)
keepsettings = 0 (off)
nowerr = 0 (off)
readonly = 0 (off)
readahead = 8 (on)
geometry = 1870/255/63, sectors = 30043440, start = 0
Обычно это значения, устанавливаемые по умолчанию. Как видите, большинство возможностей просто отключено. Это и естественно, поскольку разработчики дистрибутивов выбирают такие значения параметров, при которых будут работать любые типы дисков. А уж об оптимизации параметров для вашего диска придется позаботиться вам самим!
Для начала посмотрим, какую еще информацию о диске и параметрах интерфейса можно получить с помощью команды hdparm.
Опция -i позволяет получить информацию о модели жесткого диска, его серийном номере и некоторых других параметрах.
Опция -g выводит информацию о геометрии диска (число цилиндров/головок/секторов), его размере (числе секторов), и начальном смещении (номер сектора, с которого начинается используемое пространство, обычно 0).
Опция –T позволяет протестировать скорость обмена данными с кэшем (т. е. скорость работы подсистемы память-ЦПУ-буфер кэш).
Опция –е служит для тестирования скорости непосредственно записи на диск (а не в кэш-память).
Поскольку опции в команде можно комбинировать, давайте, выполним команду
[root]# hdparm -Tt /dev/hda
Результатом будут примерно такие строки (для вашего диска цифры, конечно, будут другими):
/dev/hda:
Timing buffer-cache reads: 128 MB in 1.34 seconds = 95.52 MB/sec
Timing buffered disk reads: 64 MB in 17.86 seconds = 3.58 MB/sec
Эти данные позволяют судить о производительности подсистемы ввода-вывода вашего жесткого диска. Если ваш диск не очень давнего выпуска, можно попытаться поднять производительность этой подсистемы, используя следующие опции команды hdparm:
С помощью опции –c вы имеете возможность воздействовать на формат обмена данными между процессором и жестким диском. По умолчанию используется значение 16 бит, но если после –c указать 1 или 3, то произойдет переключение на один из режимов 32-битной передачи. Режим, имеющий номер 3, считается более надежным, хотя и работает чуть медленнее.
Используя опцию –d 1 можно активизировать режим DMA (Direct Memory Access — прямой доступ к памяти). Однако, чтобы это имело смысл, ядро должно быть скомпилировано с поддержкой DMA.
Опция –m задает многосекторный режим ввода-вывода. Число после опции указывает максимальное количество секторов, которые можно передать вместе. Это ускоряет передачу больших файлов. Максимально допустимое значение этого параметра для вашей модели жесткого диска указано под ключевым словом MaxMultSect в перечне параметров, выдаваемых командой hdparm –i.
С помощью опции –p можно настраивать режим PIO (программируемый ввод-вывод). Чем выше число (можно использовать значения в интервале от 0 до 5), тем быстрее осуществляется передача данных. Повышение этого параметра ничего не дает при работе с медленным диском, но повышает опасность потери данных, так что подходите к его использованию осторожно.
Включение опции –u приводит к тому, что снимается запрет на обработку других прерываний, установленный на время обработки дискового прерывания. Это означает, что во время ожидания запрошенных с диска данных ядро сможет принять и обработать другие запросы (например, полученные от сетевых устройств или модема). Это должно положительно сказаться на общей производительности системы, но не все аппаратные конфигурации способны работать в таком режиме!
Давайте попробуем осторожно улучшить настройки подсистемы ввода-вывода данных для жесткого диска. Изменяйте значения параметров по одному, и после каждого изменения проверяйте результат с помощью команды
hdparm –tT /dev/hda.
В случае зависания компьютера или каких-то других неприятностей (вы к ним готовы, не так ли!), перезагружайте компьютер (снова в однопользовательском режиме) и пробуйте другое значение для параметра, изменявшегося последним. Поскольку задаваемые вами установки нигде не зафиксировались, вы будете каждый раз начинать с одной и той же точки. Приведу для иллюстрации тот результат, на котором я решил остановить эксперименты:
[root]# hdparm -X66 -d1 -u1 -m16 -c3 /dev/hda
/dev/hda:
setting 32-bit I/O support flag to 3
setting multcount to 16
setting unmaskirq to 1 (on)
setting using_dma to 1 (on)
setting xfermode to 66 (UltraDMA mode2)
multcount = 16 (on)
I/O support = 3 (32-bit w/sync)
unmaskirq = 1 (on)
using_dma = 1 (on)
[root]# hdparm -tT /dev/hda
/dev/hda:
Timing buffer-cache reads: 128 MB in 1.43 seconds =89.51 MB/sec
Timing buffered disk reads: 64 MB in 3.18 seconds =20.13 MB/sec
Как видите, скорость обмена данными возросла у меня примерно в 6 раз!
Как уже было сказано, после выполнения команды hdparm с любым набором опций вновь установленные значения действуют только в текущем сеансе работы системы, а после перезагрузки оптимизированные установки будут потеряны. Поэтому после завершения экспериментов надо еще записать вызов команды с подобранными значениями опций в один из системных скриптов загрузки, например, в /etc/rc.d/rc.sysinit (в ALT Linux Junior 1.0 для настройки IDE-дисков имеется специальный скрипт /etc/rc.d/scripts/idetune). Желательно перед этим убедиться, что система ведет себя стабильно и даже выполнить команду проверки состояния файловой системы на данном устройстве (см. разд. 9.5.4).
В заключение заметим, что кроме опций, влияющих на производительность подсистемы ввода-вывода (имейте в виду, что далеко не все они были рассмотрены выше), команда hdparm имеет еще ряд опций, позволяющих управлять энергопотреблением и другими характеристиками дисковой подсистемы. Полный список всех опций команды hdparm смотрите на соответствующей man-странице (man 8 hdparm).
Команда kbdrate
Скорость повтора задается в символах в секунду и может принимать только определенные значения в пределах от 2 до 30 символов в секунду. Но задать (после опции –r) вы можете любое значение в этих пределах, программа сама выберет ближайшее допустимое значение. Число после опции -d задает задержку в миллисекундах (допустимы значения от 250 до 1000 с шагом 250). Чтобы не устанавливать эти значения после каждого перезапуска компьютера, можно добавить в файл /etc/rc.d/rc.sysinit сроку следующего вида:
/sbin/kbdrate -s -r 16 -d 500
где опция -s просто подавляет вывод ненужных в данном случае сообщений. Если эту команду выполнить без указания параметров, для скорости повтора и задержки будут установлены значения по умолчанию: для скорости повтора — 10,9 символов в секунду, а для задержки — 250 миллисекунд.
Еще один вопрос, относящийся к настройке клавиатуры, — это способ изменения положения переключателей NumLock, CapsLock и ScrollLock. Для этого можно воспользоваться командой setleds. Например, для того, чтобы переключатель NumLock был по умолчанию включен, добавьте в файл /etc/rc.d/rc.sysinit следующие строки:
for tty in /dev/tty[1-9]*; do
setleds -D +num < $tty
done
Изменение раскладки клавиатуры — это вопрос значительно более сложный. Но, поскольку этот вопрос имеет большое значение как вообще для настройки клавиатуры, так и для решения проблемы русификации, его необходимо рассмотреть подробнее.
И начать придется с краткого изложения проблем кодировки символов.
Конфликты по прерываниям
Сначала надо определить, какое прерывание использует ваша мышь, и убедиться, что она не конфликтует с каким-нибудь другим устройством. Этот момент очень важен, потому что под Linux мышь не может использовать одно и то же прерывание с каким-либо другим устройством, даже если все прекрасно работает под управлением другой ОС. Так что проверьте документацию на все подключенные у вас периферийные устройства, чтобы знать, какие прерывания они используют!
Список занятых (используемых) на данный момент прерываний можно получить, выполнив команду
[user]$ cat /proc/interrupts
или просмотрев файл /proc/interrupts.
В большинстве случаев IRQ4 используется первым последовательным портом (/dev/ttyS0), IRQ3 — вторым последовательным портом (/dev/ttyS1, предполагается, что у вас есть такие устройства, если нет — вы можете использовать их IRQ). IRQ5 используется некоторыми SCSI-устройствами, а IRQ12 — некоторыми сетевыми картами. Если ваша сетевая карта использует IRQ12, а ваша мышь — типа PS/2, то у вас будут проблемы, поскольку вы вынуждены будете использовать IRQ12 только для порта PS/2. Для мышей ATI-XL, Inport и Logitech ядро по умолчанию использует прерывание IRQ5, так что если вы не хотите перекомпилировать ядро, вам придется использовать для мыши именно это прерывание. Впрочем, последние версии ядра позволяют задать опции командной строки, определяющие прерывание, которое будут использовать мыши типа Inport и Logitech. Мыши типа PS/2 всегда используют прерывание IRQ12, и не существует способа изменить это, так что в случае конфликтов надо перенастраивать другие периферийные устройства.
Модуль XKB
В последних версиях дистрибутивов Linux устанавливается дополнительный модуль работы с клавиатурой — XKB. Модуль XKB точно также сообщает программе только скан-код и свое "состояние". Но в отличие от "старого" модуля (который называют "core protocol", или "core-модуль") XKB имеет более сложную таблицу символов, другой набор "модификаторов" и некоторые дополнительные параметры "состояния клавиатуры". Поэтому для полноценной работы с XKB, библиотека X-lib должна содержать модифицированные процедуры интерпретации скан-кодов (процедуры, "знающие" о XKB). Естественно, все версии X-Window, у которых X-сервер "укомплектован" модулем XKB, имеют и соответствующую библиотеку X-lib. Таким образом, XKB фактически делится на две части — модуль, встроенный в X-сервер, и набор подпрограмм, входящих в библиотеку X-lib.
Однако, поскольку существуют программы, которые были рассчитаны на работу со старой библиотекой X-lib, "не подозревающей" о существовании XKB, возникает "проблема совместимости". То есть, модуль XKB должен уметь общаться как со "своей" X-lib, так и со "старой" (работающей в соответствии с "core protocol"). Естественно, "общение" не ограничивается только передачей сообщений о нажатии/отпускании клавиш. Процедуры X-lib могут обращаться к X-серверу с различными запросами (например — взять таблицу символов) и командами (например, поменять в этой таблице расположение символов). На все эти запросы и команды модуль XKB должен реагировать так, чтобы даже "старая" X-lib могла работать правильно (насколько это возможно).
При старте X-сервера, модуль XKB зачитывает все необходимые данные из текстовых файлов, которые образуют "базу данных" настроек XKB. Строго говоря, большинство из этих файлов сам модуль XKB не читает. Он вызывает программу xkbcomp, которая переводит содержимое этих файлов в двоичный формат, понятный непосредственно модулю XKB. Но для настройки это не так уж важно, поскольку вызов xkbcomp происходит автоматически, незаметно для пользователя.
База данных, необходимых модулю XKB, находится в каталоге /usr/X11R6//lib/X11/xkb и состоит из 5 компонентов, расположенных в подкаталогах с именами:
keycodes
Здесь расположены таблицы, которые просто задают символические имена для скан-кодов. Например
<TLDE>= 49;
<AE01> = 10;
types
Здесь описываются возможные типы клавиш. Тип клавиши определяет как должно меняться значение, выдаваемое клавишей в зависимости от модификаторов (<Control>, <Shift> и т. п.). Так, например, "буквенные" клавиши относятся к типу ALPHABETIC, что означает, что они имеют разное значение в зависимости от состояния <Shift> и <Caps Lock>. А клавиша <Enter> имеет тип ONE_LEVEL, что означает, что ее значение всегда одно и то же, независимо от состояния модификаторов.
compat (сокращение от compability)
Здесь описывается "поведение" модификаторов. В модуле XKB имеется несколько внутренних переменных, которые, в конечном счете, и определяют, какой символ будет генерироваться при нажатии клавиши в конкретной ситуации. Так вот, в файлах из каталога compat как раз описывается, как должны меняться эти переменные при нажатии различных клавиш-модификаторов. В этом же разделе обычно описывается и поведение "лампочек-индикаторов" на клавиатуре.
symbols
Это каталог содержит таблицы, в которых для каждого скан-кода (задаваемого именем скан-кода, определенным в keycodes) перечисляются все значения (symbols), которые должна выдавать клавиша. Естественно, количество различных значений зависит от типа клавиши (которые описываются в types), а какое именно значение будет выдано в конкретной ситуации, определяется состоянием модификаторов и их "поведением" (которое описывается в compat).
geometry
Здесь описываются варианты "геометрии" клавиатуры, т. е. расположение клавиш на клавиатуре. Эти описания нужны не столько самому X-серверу, сколько прикладным программам, которые рисуют изображение клавиатуры.
Надо сказать, что в каждом из этих каталогов имеется несколько файлов (иногда, довольно много) с разными настройками. Более того, каждый файл внутри себя может содержать несколько блоков (секций, разделов) вида
тип_компонента "имя_блока" {........};
Поэтому, для того, чтобы выбрать конкретную настройку, ее обычно указывают в виде имя_файла(имя_блока), например, us(pc104). В то же время, обычно один из блоков в файле (не обязательно самый первый) помечается флагом default. Это означает, что если указать только имя файла, то будет выбран именно этот блок.
Полная конфигурация XKB задается в секции ImputDevice, определяющей клавиатуру, файла конфигурирования пакета XFree86, т. е. в файле /etc/X11/XF86Config-4. При этом имеется три способа задания конфигурации клавиатуры в этом файле.
Первый способ задания конфигурации заключается в том, что вы можете указать непосредственно каждый из компонентов, например
Option "XkbKeycodes" "xfree86" Option "XkbTypes" "default" Option "XkbCompat" "default" Option "XkbSymbols" "us(pc104)" Option "XkbGeometry" "pc(pc104)"
Как легко догадаться, это означает, что: описание keycodes берется из файла "xfree86" в подкаталоге keycodes, причем из файла будет выбран тот блок, который помечен в нем флагом default; описание types берется из файла "default" в подкаталоге types; описание compat берется из файла "default" в подкаталоге compat; описание symbols берется из файла "us" в подкаталоге symbols, причем будет выбран блок "pc104"; описание geometry берется из файла "pc" в подкаталоге geometry, блок "pc104";
Надо заметить, что в любом блоке (в любых компонентах) может встретиться инструкция include "имя_файла(имя_блока)" (естественно, имя_блока может отсутствовать) что означает, что в текущий блок должно быть вставлено другое описание из указанного файла (указанного блока). Поэтому полное описание может неявно включать в себя данные из многих других файлов, кроме тех, которые вы явно укажете в файле конфигурации X-сервера.
Второй способ задания конфигурации клавиатуры заключается в том, что вы можете указать одной инструкцией сразу полный набор настроек. Такие наборы называются keymaps и, также как и обычные компоненты конфигурации XKB, располагаются в отдельных файлах (которые, тоже содержат в себе несколько именованных блоков) в подкаталоге keymap.
Обычно, в каждом блоке в файлах из keymap просто указывается из каких файлов XKB должен извлечь соответствующие компоненты (хотя, в принципе, там может быть и полное описание всех компонентов), например xkb_keymap "ru" { xkb_keycodes { include "xfree86" }; xkb_types { include "default" }; xkb_compatibility { include "default" }; xkb_symbols { include "en_US(pc105)+ru" }; xkb_geometry { include "pc(pc102)" }; };
Обратите внимание, что в одной инструкции include может быть указано несколько файлов (блоков) через знак "+". Понятно, что это означает, что должны быть вставлены последовательно все указанные файлы.
Таким образом, в файле конфигурации X-сервера можно вместо пяти компонентов указать сразу один из готовых наборов keymap, например
Option "XkbKeymap" "xfree86(ru)"
Кроме того, эти два способа можно комбинировать. Например, если вы выбрали один из подходящих наборов keymap, но вас не устраивает один из компонентов, например geometry, то в файле конфигурации можно указать
Option "XkbKeymap" "xfree86(ru)"
Option "XkbGeometry" "pc(pc104)"
При этом, в соответствии с первой инструкцией, все компоненты будут взяты из keymap "xfree86(ru)", а вторая инструкция "перепишет" geometry, не затрагивая остальные компоненты.
Третий способ несколько отличается от предыдущих. Набор настроек можно указывать не перечислением компонентов, а с помощью задания "правил" (Rules), "модели" (Model), "схемы" (Layout), "варианта" (Variant) и "опций" (Option).
В этом наборе только Rules представляют собой некий файл (эти файлы тоже находятся в отдельном подкаталоге rules каталога /usr/X11R6//lib/X11/xkb), в котором находится таблица правил — "как выбрать все пять компонентов настроек XKB в зависимости от значений Model, Layout и т. д.". Все остальные параметры представляют собой просто "ключевые слова": Model обычно определяет тип "железа" — клавиатуры; Layout — язык или, точнее, алфавит, который "навешивается" на кнопки клавиатуры; Variant — различные варианты размещения знаков алфавита (заданных Layout'ом); Options — обычно меняет "поведение" или "расположение" модификаторов Control и Group (переключатель групп — это переключатель "языка", например, русский/латинский).
По этим словам модуль XKB при старте ищет в таблицах "правил" подходящие файлы настроек (keycodes, types, compat, symbols и geometry). Другими словами, Rules определяет некоторую функцию, аргументами которой являются Model, Layout, Variant и Options, а значение, которое возвращает эта функция, представляет собой полный набор из компонентов настроек XKB — keycodes, types, compat, symbols и geometry (или полная keymap).
Итак, если вы используете третий способ указания конфигурации XKB, то в файле конфигурации X-сервера, надо задать параметры XkbRules, XkbModel, XkbLayout и, если вам нужно что-то не совсем стандартное — XkbVariant и XkbOptions.
Например, Option "XkbRules" "xfree86" Option "XkbModel" "pc104" Option "XkbLayout" "ru" Option "XkbVariant" "" Option "XkbOptions" "ctrl:ctrl_ac"
означает, что модуль XKB должен в соответствии с правилами, описанными в файле ./rules/xfree86, выбрать настройки для клавиатуры типа "pc104" (104 кнопки), русского алфавита (английский алфавит будет включен "по умолчанию"), вариант — "стандартный" (т. е., этот параметр можно было не писать) и, наконец, дополнительные опции для вашей "раскладки клавиатуры" — "ctrl:ctrl_ac".
Что означают различные опции, а также какие "модели" и "схемы" определены в "правилах" (и что они означают), можно посмотреть в файле xfree86.lst (или другом файле *.lst, если вы выбрали "правила", отличные от xfree86), который находится в той же директории, что и файл "правил", т. е. в подкаталоге rules.
Небольшое отступление о клавише — переключателе "рус/лат". В первых вариантах модуля XKB раскладка "русской" клавиатуры включала в себя и "переключатель групп" — рус/лат, "подвешенный" на клавишу CapsLock. С одной стороны это было удобно: в простейшем случае достаточно было выбрать "русскую раскладку" и вы автоматически получали и клавишу для переключения "на русский". Но, с другой стороны, это было неудобно для тех, кто предпочитает в качестве переключателя рус/лат другую клавишу (или комбинацию клавиш). Конечно, выбрать другой переключатель не составляло труда, но при этом оставался и переключатель на CapsLock, что многим не нравилось. Для того, чтобы убрать его, надо было "залезть" в соответствующий файл и вручную подправлять соответствующую раскладку.
В конце концов (начиная с версии 3.3.4) сами разработчики Xfree86 убрали этот "переключатель" из "русской раскладки". Но, в связи с этим появились и некоторые проблемы — теперь клавишу-переключатель надо явно "заказывать" при конфигурировании XKB.
Мышь
Существуют два основных типа мышей — подключаемые через последовательный порт (serial mice) и подключаемые к шине (bus mice). Большинство компьютеров оборудуются в настоящее время мышами второго типа. Дальнейший текст относится к bus-мышам и основан на Busmouse HOWTO Криса Багвелла (Chris Bagwell), версии 1.91 от 15 июня 1998 г.
Настройка lpd с помощью программы printconf-gui
Настройка системы LPD состоит в том, что обеспечивается возможность создавать очереди файлов и отправлять задания из этих очередей на принтер. Такую настройку можно произвести вручную, и я надеюсь, что приведенное выше описание позволяет это сделать. Однако в большинстве дистрибутивов имеются специальные утилиты, облегчающие конфигурацию подсистемы печати. В дистрибутиве Red Hat версии 6 такая утилита называлась printtoool, а в версии 7.1 вместо printtool включена утилита printconf-gui, которую можно вызвать из меню оболочки KDE. Эта утилита поддерживает ведение конфигурационного файла /etc/printcap, создание областей спулинга и выбор фильтров. Если в файле /etc/printcap не имеется ни одной записи о принтерах, то главное окно программы printconf-gui выглядит так, как показано на рис. 9.2.
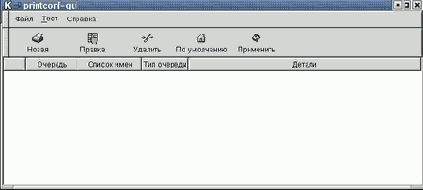
Рис. 9.2. Основное окно printconf-gui
Как видите, в меню программы имеется команда Новая, после выбора которой мы видим следующее окно (рис. 9.3), в котором можно ввести имя очереди (которое будет и именем принтера, а поэтому должно быть уникальным), а также его синонимы (aliases).

Рис. 9.3. Задание имени очереди

Рис. 9.4. Выбор типа принтера и задание устройства
Щелкнув по команде меню Тип очереди в левом поле окна, вы получите возможность выбрать тип принтера и задать имя специального файла устройства. Тип очереди выбирается из выпадающего списка. Можно выбрать один из следующих типов: Локальный принтер — принтер, непосредственно присоединенный к вашему компьютеру через параллельный или USB-порт; Unix Printer (lpd Spool) — принтер, присоединенный к другому UNIX-компьютеру, доступ к которому осуществляется по сети TCP/IP (например, принтер, присоединенный к другому Linux-компьютеру); Windows Printer (SMB Share) — принтер, присоединенный к другой системе, работающей под ОС Windows или имеющей установленный сервер Samba (SMB); Novell Printer (NCP Queue) — принтер, присоединенный к другой системе, использующей технологию Novell's NetWare и протокол NCP; JetDirect Printer — принтер, непосредственно подключенный к сети, а не к какому-то компьютеру.
Мы рассмотрим только случай подключения локального принтера, а остальные варианты вы можете изучить с помощью имеющейся в программе подсказки (экранная кнопка Справка).
После выбора типа принтера и указания имени устройства щелкните по строке Printer Driver в левой колонке, и вы увидите список известных программе драйверов, упорядоченный по фирмам-производителям (рис. 9.5):

Рис. 9.5. Выбор драйвера
Если щелкнуть по треугольному значку слева от имени фирмы, раскроется список драйверов для принтеров данного производителя. На рис. 9.6 видна часть списка принтеров, производимых фирмой Hewlett Packard.

Рис. 9.6. Принтеры фирмы Hewlett Packard
Щелчок по кнопке с надписью Printer Notes… приводит к появлению окна с краткой информацией о выбранном принтере (рис. 9.7).
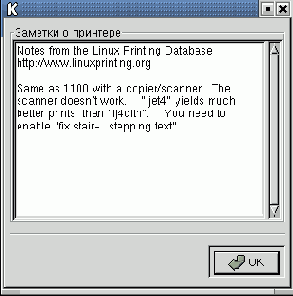
Рис. 9.7. Заметки о принтере
Ну, и последнее окно в этом ряду (рис. 9.8) позволяет задать некоторые параметры для выбранного принтера: режим печати (нормальный, экономичный, высокое качество), разрешение печати, размер бумаги, и т. п.
Завершив ввод, нажмите кнопку OK. После этого введенные вами данные будут сохранены в базе данных в файле /etc/printcap.
Команда Правка основного меню программы позволяет таким же способом отредактировать установки для принтера, который уже был описан ранее.
После того, как вы добавили в базу данных новый принтер или отредактировали установки ранее заведенного, обязательно необходимо перезапустить демон lpd. Для этого можно воспользоваться кнопкой Применить в основном окне программы.

Рис. 9.8. Задание параметров печати
Теперь можно попытаться распечатать пробную страничку, воспользовавшись командой Тест главного меню программы. Вам будет предложено 3 варианта тестовой страницы: Print PostScript Test Page, Print A4 PostScript Test Page, или Print ASCII Test Page. Скорее всего, тестовая страница у вас распечатается без проблем. Но если вы попробуете распечатать страницу текста из какого-либо приложения, тем более, если используются разные шрифты, да еще с кириллицей, то результат, к сожалению, может оказаться не таким радующим. Дело в том, что мы пока настроили только "нижний" слой подсистемы печати, обеспечивающий передачу потока байт от ядра ОС в параллельный порт или на сетевой принтер. Но проблема управления самим принтером (а не параллельным портом) пока не решена. В системе LPD эта проблема решается с помощью фильтров.
Настройка мыши
Далее необходимо проверить настройки в некоторых конфигурационных файлах. Вначале убедитесь, что существует файл /etc/sysconfig/mouse, и что в нем записано что-то вроде:
MOUSETYPE="Microsoft"
XMOUSETYPE="Microsoft"
XEMU3=yes
Естественно, что тип мыши должен соответствовать вашей мыши, у меня, например, это "PS/2".
Чтобы вырезать и вставлять куски текста в консоли, должен быть установлен сервер мыши gpm.
Проверьте, что сервер мыши gpm запущен, для чего дайте команду:
[user]$ ps -A | grep gpm
Если в результате вы получите непустую строку, то драйвер работает. Если же процесс gpm не найден, надо проверить наличие скрипта /etc/rc.d/init.d/gpm, в котором должна найтись строка вызова демона gpm. Эта строка может иметь примерно такой вид:
daemon gpm -t $MOUSETYPE -d 2 -a 5 -B 132 # two-button mouse
(смысл параметров см. на странице man gpm).
Если сервер gpm работает, то выделять и вставлять куски текста можно следующим образом. Нажмите левую кнопку и выделяйте текст. Когда дойдете до конца нужного куска текста, отпустите кнопку. Потом нажмите правую кнопку в том месте, где вы хотите осуществить вставку. Можно даже в другой виртуальной консоли. То же самое можно проделать в X Window, но для вставки нужно нажимать среднюю клавишу, или обе, если у вас двухкнопочная мышь.
Несколько практических рекомендаций по настройке модуля XKB
Самый простой способ — использовать программу для автоматической настройки X-Window. В XFree86 версии 3 такая программа называется XF86Setup. Она использует третий метод задания конфигурации XKB. При этом "по умолчанию" используются "правила" (XkbRules) — xfree86. Вам нужно будет только выбрать "модель" (XkbModel), "схему" (XkbLayout) и "способ переключения групп" (переключатель "РУС/ЛАТ").
Кроме того, при желании вы можете изменить "положение клавиши Ctrl". Естественно, в конфигурации это будет выглядеть как соответствующие строчки XkbOptions. Итак, запустите программу XF86Setup, выберите раздел Keyboard. В этом разделе выберите из меню Model (тип клавиатуры) и Layout (язык). Не забудьте отметить в отдельных списках (в правой части) подходящий "переключатель групп" и, если хотите — "расположение Ctrl". При выходе из программы она запишет соответствующие строчки в файл конфигурации Xfree86 в секции Keyboard.
А теперь рассмотрим то, как можно задать эти настройки путем прямого редактирования секции InputDevice (Keyboard) файла /etc/X11/XF86Config.
Прежде всего, надо сказать, что "ключевыми словами" в этих настройках будут:
xfree86 — название "архитектуры" X-Window;
pc101 (pc104, pc105 и т.п.) — тип клавиатуры (количество кнопок);
ru — название "раскладки клавиатуры" с русским алфавитом.
Проще всего сразу задать конфигурацию клавиатуры с помощью keymap. В файлах конфигурации есть набор "полных keymap'ов" для архитектуры xfree86, отличающихся "языком". Все они лежат в файле xfree86, а название блока внутри файла отражает название "языка" (точнее — алфавита) — xfree86(us), xfree86(fr), xfree86(ru) и т. д. Полный список keymap-файлов можно посмотреть в файле /usr/X11R6//lib/X11/xkb/keymap.dir.
Для "русифицированной" клавиатуры вполне подойдет
Option "XkbKeymap" "xfree86(ru)"
К сожалению, после исключения CapsLock как переключателя рус/лат из русской раскладки (см. замечание в конце предыдущего раздела) получилось так, что "полная keymap" для русского языка осталась вообще без какого-либо переключателя "по умолчанию". Но вы можете добавить его вручную. Для этого придется найти в файле /keymap/xfree86 блок "ru". И дописать в строчку xkb_symbols ссылку на описание соответствующего переключателя групп. Для CapsLock это будет — group(caps_toggle). То есть, строчка xkb_symbols будет выглядеть как
xkb_symbols { include "en_US(pc105)+ru+group(caps_toggle)"};
Полный список возможных переключателей групп (т. е. возможных переключателей "рус/лат") можно найти в файле /usr/X11R6//lib/X11/xkb/symbols/group (проведите в этом файле поиск по ключевому слову xkb_symbols).
Теперь рассмотрим случай, когда для задания конфигурации клавиатуры используется третий способ — через "правила", "модель", "схему" и т. д. Как было сказано выше:
название "правил" (rules) соответствует "архитектуре" (xfree86);
"модель" (model) соответствует типу клавиатуры (pc101, pc102 и т.п.);
"схема" (layout) отражает "язык" (ru).
Поэтому, подходящая конфигурация будет выглядеть примерно так:
Option "XkbRules" "xfree86"
Option "XkbModel" "pc104"
Option "XkbLayout" "ru"
С помощью строки XkbOptions можно подобрать "поведение" управляющих клавиш. Возможные значения XkbOptions и их смысл можно подсмотреть в файле /rules/xfree86.lst в той части, которая начинается строкой "! option".
Не забудьте, что, как и в предыдущем случае, надо явно выбрать переключатель групп. Для CapsLock это будет
Option "XkbOptions" "grp:caps_toggle"
И, наконец, рассмотрим первый способ — описание отдельных компонентов настройки (keycodes, compat, types, symbols, geometry).
Если вы не знаете с чего начать, подсмотрите соответствующий набор в keymap. Или попробуйте "вычислить" его через rules/model/layout. Чаще всего подойдут следующие значения:
для keycodes выбрать файл xfree86;
для types и compat подойдут файлы default ("по умолчанию") или complete ("полная");
geometry, скорее всего, "pc", а количество кнопок задается названием блока в файле pc — pc(pc101), pc(pc102), pc(pc104). Полный список "геометрий" имеется в файле /usr/X11R6/lib/X11/xkb/geometry.dir.
А вот на symbols обратите особое внимание. Файл symbols/ru описывает только "буквенные" клавиши. Если вы укажете только его, то у вас не будут работать все остальные кнопки (включая Enter, Shift/Ctrl/Alt, F1-F12 и т. д.). Поэтому symbols должен состоять по крайней мере из двух файлов — en_US(pc101) (в скобках — тип клавиатуры) и, собственно, ru. Полный список symbols — в файле /usr/X11R6/lib/X11/xkb/symbols.dir.
Сюда же надо добавить и описание подходящего "переключателя рус/лат" (как уже говорилось, их перечень — в файле symbols/group).
Для первого метода список может выглядеть так
Options "XkbKeycodes" "xfree86" Options "XkbTypes" "complete" Options "XkbCompat" "complete" Options "XkbSymbols" "en_US(pc101)+ru+group(alt_shift_toggle)" Options "XkbGeometry" "pc(pc101)"
Если вам хочется задать дополнительные изменения "поведения" управляющих клавиш (то, что в третьем методе задается XkbOptions), то подсмотрите подходящую "добавку" в rules/xfree86.lst и "приплюсуйте" ее в строчку XkbSymbols. Например,
XkbSymbols "en_US(pc101)+ru+group(shift_toggle)+ctrl(ctrl_ac)"
На этом мы ограничим описание методов настройки клавиатуры, а точнее — настройки модуля XKB. Если вы хотите разобраться с этим детальнее, то обратитесь к исходному материалу И. Паскаля .
Нумерация
Сначала приведем дополнительные сведения о нумерации жестких дисков в системе Linux (табл. 9.3).
Таблица 9.3. Нумерация жестких дисков
Тип жесткого диска
Первые жесткие диски на обоих IDE-контроллерах получают младшие номера 0, а вторые диски — номера 64 (и имена /dev/hda и /dev/hdb). По этим номерам происходит обращение ко всему диску в целом, независимо от количества разделов на этом диске. Разделы на дисках получают, соответственно, следующие по порядку номера: первый раздел на первом диске — номер 1 и имя /dev/hda1, второй раздел — номер 2 и имя /dev/hda2 и так далее.
Более двух дисков на IDE-контроллере не бывает, и более двух контроллеров на персональные компьютеры обычно не ставят, так что всего бывает не более 4 IDE-дисков (/dev/hd[a-d]).
Аналогично, целые SCSI-диски получают младшие номера 0, 16, 32 и так далее, и имена /dev/sd[a-g]. Разделы на этих дисках получают младшие номера, следующие по порядку за младшим номером всего диска: первый раздел на диске /dev/sda получает младший номер 1 (и имя /dev/sda1), первый раздел на диске /dev/sdb получает младший номер 17 (и имя /dev/sdb1), и так далее.
Определение типа мыши
Вы должны знать две важных характеристики своей мыши: какой у нее интерфейс и какой она использует протокол.
Интерфейс — это совокупность аппаратных параметров мыши, включающая такие параметры, как используемые мышью прерывания, порты ввода-вывода и количество контактов в разъеме. Ядро Linux поддерживает 4 типа интерфейсов bus-мыши: Inport (Microsoft), Logitech, PS/2 и ATI-XL. Не существует однозначного алгоритма определения типа интерфейса мыши.
Мыши типа Inport обычно подключаются к интерфейсной карте на материнской плате. Если разъем, который подключается к интерфейсной карте, круглый, имеет 9 контактов и желобок (направляющую выемку) с одной стороны, то вполне возможно, что у вас мышь типа Inport. Если только не Logitech, поскольку эти мыши внешне имеют те же характеристики. Различить их можно только если у вас сохранилась упаковка или руководство, в котором указан тип мыши.
Мыши типа PS/2 подключаются не к плате расширения, а к специальному разъему (PS/2 Auxiliary Device port) на контроллере клавиатуры. Этот разъем имеет 6-контактов (6-pin mini DIN connector), и похож на разъем для подключения клавиатуры.
Мыши типа ATI-XL — это вариант мышей типа Inport. Они подключаются к комбинированной карте, являющейся видео-адаптером и контроллером мыши. Если только вы не знаете точно, что у вас видеоадаптер ATI-XL (и следовательно мышь ATI-XL), то, скорее всего, у вас мышь другого типа.
Протокол — это чисто программная характеристика мыши. Большинство мышей Inport, Logitech и ATI-XL используют протокол ''BusMouse'', а мыши типа PS/2 используют протокол ''PS/2''.
Печать на удаленный принтер
Если ваш компьютер подключен к локальной сети, то не обязательно иметь принтер, непосредственно к нему подключенный, можно пользоваться принтером, подключенным к какому-то другому компьютеру. Настройка такого принтера на вашем компьютере требует только указания того, к какому компьютеру в сети подключен принтер (это делается с помощью задания переменных rm и rp в файле /etc/printcap, о чем было сказано выше). Если использовать утилиту printconf-gui, то достаточно при выборе типа очереди (см. рис. 9.4) выбрать вариант "UNIX printer (lpd Queue)", если это другой Linux-компьютер. Если принтер подключен к Windows-компьютеру или отдан в сеть через Samba-сервер, то, естественно, надо выбирать тип очереди "Принтер Windows (ресурс Samba)"
На удаленном компьютере должен быть разрешен доступ к этому принтеру. В Linux это делается с помощью файла /etc/lpd.perms (см. соответствующую страницу руководства man).
PostScript и Ghostscript
К сожалению пользователей, фирмы-производители принтеров долгое время не могли достигнуть согласия в вопросе о выборе управляющих сигналов для производимых ими устройств. В результате для каждого принтера до сих пор необходим особый драйвер. Однако со времен так называемой "революции настольных издательских систем" 80-х годов в качестве в качестве стандартного языка управления принтером постепенно утвердился язык PostScript, разработанный фирмой Adobe Systems, Inc. И не только в UNIX-среде, а в издательском деле вообще.
Этот язык представляет собой специальный язык программирования для описания выводимой на печать страницы с текстом или графикой. Adobe Systems, Inc., изначально разработавшая стандарт на PostScript, открыла его для свободного распространения. Отметим еще, что формат PDF (Формат Переносимого Документа Adobe) — это в действительности чуть больше чем несколько преобразованный PostScript в сжатом файле.
Идея, заложенная в основу разработки PostScript, проста: все, что можно напечатать, описывается с помощью специального языка программирования, принтер же должен этот язык понимать. И принтеры, "понимающие" язык PostScript, т. е. имеющие встроенный PostScript-интерпретатор (так называемые PostScript-принтеры), быстро появились. К сожалению, они оказались стабильно дороже обычных принтеров. Тогда были разработаны программные PostScript-интерпретаторы, которые берут данные в формате PostScript и преобразуют в специфический для данного принтера управляющий код. Это дает вам виртуальный PostScript-принтер и позволяет использовать принтеры, не имеющие аппаратного интерпретатора.
Вероятно, одним из лучших программных интерпретаторов языка PostScript является Ghostscript (http://www.cs.wisc.edu/~ghost/), или просто gs. Он существует в двух вариантах. Коммерческая версия Ghostscript, называемая Aladdin Ghostscript или AFPL Ghostscript, свободна для персонального использования, но не может распространяться с коммерческими дистрибутивами Linux. В составе последних доступен GNU Ghostscript, представляющий собой тот же gs, только версией ниже и с другим лицензионным соглашением. На сегодняшний день можно загрузить версию AFPL Ghostscript 7.0, тогда как версия GNU Ghostscript — 5.5. В составе Ghostscript имеется внушительный набор фильтров — аппаратно ориентированных модулей, позволяющих получать изображение на различных устройствах. Устройствах, а не принтерах, поскольку Ghostscript может обеспечить вывод на любое графическое устройство. Именно gs присутствует в качестве фильтра в /etc/printcap — конфигурационном файле lpd. Опции запуска gs в качестве фильтра определяются типом принтера.
Работа с клавиатурой в графическом режиме
В графическом режиме работа с клавиатурой организована значительно сложнее. Подробное описание этого вопроса можно найти в обстоятельном (но, к сожалению, очень трудном для понимания) материале Ивана Паскаля "X Keyboard Extension" . Приведем очень краткий конспект основных положений этого материала.
Как было сказано выше, при работе в системе X Window клавиатура передает этой системе чистые скан-коды. Клавиатурный модуль X-сервера передает сообщение о нажатии (и отпускании) кнопки прикладной программе. В этом сообщении указывается только скан-код нажатой кнопки и "состояние клавиатуры" — набор битовых "флагов", который отражает состояние клавиш-модификаторов (<Shift>, <Control>, <Alt>, <CapsLock> и т.п.). "Клиентская" программа должна сама решить — какой код символа, соответствующий скан-коду, надо выбрать при таком сочетании битов-модификаторов. Разумеется, при создании программ никто не пишет каждый раз программу для интерпретации скан-кодов. Для этих целей существуют специальные подпрограммы в библиотеке X-lib. Процедуры из X-lib, зная скан-код и "состояние клавиатуры", выбирают подходящий символ в соответствии с таблицей символов, которая хранится в X-сервере и которую они обычно "запрашивают" у X-сервера при старте программы. Эта таблицу можно менять с помощью утилиты xmodmap. Действующая таблица выводится командой xmodmap –pk.
Шрифты для Ghostscript
Для пакета Ghostscript разработаны PostScript-шрифты, которые обеспечивают высокое качество печати на не-PostScript принтерах. Такие шрифты наверняка найдутся на вашем дистрибутивном диске в виде пакета ghostscript-fonts. Однако именно со шрифтами и связано большинство проблем, которые возникают при настройке принтера.
Дело в том, что программе Ghostscript надо точно знать, где расположены шрифты для нее. Но поскольку стандарт FHS (Filesystem Hierarhy Standard), о поддержке которого заявили все составители дистрибутивов, пока еще не утвердился окончательно, структура каталогов в Linux меняется от версии к версии даже в пределах одного дистрибутива. Поэтому файлы шрифтов могут оказаться где угодно. Очень часто — не там, где их будет искать Ghostscript. В результате при попытке распечатать какой-либо документ вы можете получить далеко не то, что ожидали: от несоответствия внешнего вида распечатанного документа вашему замыслу до искажения или отсутствия фрагментов текста, требующего, в соответствии с PostScript-файлом, того самого шрифта, который не смог загрузить Ghostscript. Положение усугубляется тем, что, по крайней мере, часть документов включает кириллицу, а некоторые дистрибутивы не имеют в каталогах, сканируемых по умолчанию Ghostscript, шрифтов с кириллицей.
Преодолеть эти трудности в принципе не сложно. Но, прежде чем рассказать, как это сделать, надо сказать, что в Linux имеется программа ghostview (gv), назначение которой — принять вывод ghostscript и вывести изображение на экран. Это дает инструмент, обеспечивающий возможность предварительного просмотра ("print preview") для любого приложения, генерирующего PostScript-файлы. С помощью gv вы сможете определить, связаны ли ваши проблемы с выбором типа принтера или c работой gs в целом. Видите на экране, но не получаете на печати — попробуйте другой фильтр (выберите другой принтер), не видите ничего "путного" — продолжаем разбираться с настройкой ghostscript.
Теперь надо отметить, что программу Ghostscript можно запускать не только в качестве фильтра для LPD, но и из командной строки (для этого надо дать команду gs). Этой возможностью и воспользуемся для целей отладки.
Вначале запустите команду gs с опцией –help. В результате вы получите, во-первых, краткий информативный список опций и доступных драйверов (заметим, что этот список является списком только вкомпилированных, а не всех доступных драйверов), и, во-вторых, перечень путей поиска. Этот список можно, конечно, изменить, но для этого надо перекомпилировать программу. Если же вы не хотите заниматься компиляцией, надо поместить файлы шрифтов именно в эти каталоги.
Но этого еще недостаточно для того, чтобы Ghostscript могла использовать шрифты. Дело в том, что эта программа обращается к шрифтам по именам, записываемым в той нотации, в которой допускается их использование в PostScript-файлах. Соответствие между такими названиями шрифтов и именами реальных файлов шрифтов задается файлом Fontmap (или Fontmap.GS), который располагается в каталоге /usr/share/ghostscript/N.NN, где N.NN — номер версии программы ghostscript (на данный момент — 5.50). Каждая строка (кроме строк комментариев) этого файла состоит из трех элементов.
Первым стоит имя, под которым шрифт будет известен программе Ghostscript, причем перед этим именем должен стоять слэш (/), либо имя должно быть заключено в круглые скобки;
Далее следует имя файла шрифта либо синоним (aliace) имени шрифта. Если указывается имя файла шрифта, то оно должно быть заключено в круглые скобки и записано с указанием расширения (обычно это gsf, но допускаются также pfa и pfb), а также должно соответствовать правилам формирования имен файлов в MS-DOS, т. е. состоять из букв (в нижнем регистре), цифр и знаков подчеркивания. Если же это синоним, то указывается имя одного из уже известных программе Ghostscript шрифтов, причем перед этим именем должен стоять слэш (/).
Завершает строку точка с запятой, перед которой должен стоять, по крайней мере, один пробел или знак табуляции.
Пути к файлам шрифтов в файле Fontmap не указаны. Если вы не использовали предлагаемые руководством средства принудительной "ориентации" ghostscript (параметры командной строки и переменные окружения), то gs будет использовать "пути по умолчанию", заданные при компиляции. В этих каталогах должны иметься файлы fonts.dir, которые содержат описание фонтов в данном каталоге (подробнее о файлах fonts.dir вы можете прочитать в разд. 11.4).
Таким образом, в зависимости от потребностей вы можете либо внести в Fontmap необходимый шрифт (предварительно поместив соответствующий файл в один из доступных программе каталогов и указав имя файла в добавляемой строке), либо назначить в качестве синонима нужного шрифта имя одного из уже известных программе шрифтов. Например, сделать шрифт /Courier синонимом изначально известного программе шрифта /NimbusMonL-Regu (которому, в свою очередь соответствует файл (n022024l.pfb)). Если задача — в основном печатать файлы, PostScript-содержимое которых вне вашего контроля, — подберите синонимы для нужных шрифтов из числа известных программе. Если PostScript-файл генерируется под вашим контролем — просто выбирайте один из имеющихся в системе шрифтов. Разумеется, не забыв при этом описать его в Fontmap.
После этого выполните команду
[user]$ gv filename.ps
Если вы при этом увидите на экране весь текст из файла filename.ps, вы можете попытаться отпечатать файл и на принтере. Если же вместо текста увидите пустой лист или шрифт вам не нравится, продолжайте экспериментировать с настройкой шрифтов. Но предварительно прочитайте статью , которая послужила основой для моего рассказа о шрифтах для Ghostscript, и в которой вы найдете несколько дополнительных подсказок. Кроме того, в Интернете имеются два очень полезных ресурса и , куда будет не вредно заглянуть.
Создание собственной раскладки
Если вас не устраивает ни одна из тех раскладок клавиатуры, которые имеются в каталоге /usr/lib/kbd/keytables/i386/qwerty/, можете попробовать подправить ту раскладку, которая ближе всего к вашему идеалу. Попробуем показать, как это делается, на примере выбора клавиши переключения между русской и латинской клавиатурой (этот совет позаимствован у Романа Минакова, pharao@kma.mk.ua).
Для переключения между русской и латинской клавиатурой часто используется правая клавиша <Ctrl>, в то время как на любой более-менее современной IBM-клавиатуре есть три клавиши, которые, как правило, в Linux не задействованы. Вот одну из них и приспособим для переключения алфавитов. Для начала надо узнать какой у них код. Запускаем команду showkey с опцией --keycodes (запуск showkey, естественно, производится с консоли и необходимо предварительно выйти из mc) и последовательно (слева направо) нажимаем эти три клавиши, чтобы узнать их коды:
[root]# showkey --keycodes
kb mode was XLATE
press any key (program terminates after 10s of last keypress)...
keycode 125 press
keycode 125 release
keycode 126 press
keycode 126 release
keycode 127 press
keycode 127 release
Числа 125, 126, 127 и есть коды этих клавиш. Далее переходим в каталог /usr/lib/kbd/keytables/i386/qwerty, находим файл, который используется в данный момент (что-то типа ru1.map, если в каталоге /usr/lib/kbd/keytables/i386/qwerty вы найдете только ru1.map.gz, то выполните предварительно разархивацию: gunzip ru1.map.gz).
Для того, чтобы заставить клавишу работать как временный переключатель с русского на латинский (пока клавиша удерживается), надо придать ей значение AltGr, а чтобы она использовалась как постоянный переключатель — AltGr_Lock. Находим внутри ru1.map:
keycode 125 =
keycode 126 =
keycode 127 =
и меняем на:
keycode 125 =
keycode 126 = AltGr
keycode 127 = AltGr_Lock
Далее надо изменить установки тех клавиш, которые ранее использовались для переключения. Например, если в качестве постоянного переключателя использовалась клавиша <Ctrl> (код клавиши 97), находим строку
keycode 97 =
и вписываем:
keycode 97 = Control
В итоге получаем: клавиша, расположенная возле правой клавиши <Ctrl>, — фиксированный переключатель "рус/лат", а та что рядом с правой клавишей <Alt> — временный переключатель "рус/лат" (т. е. действующий только на то время, пока удерживается в нажатом положении соответствующая клавиша).
После редактирования сохраняем файл под новым именем (например, mymap.kmap) и записываем это имя в /etc/sysconfig/keyboard.
Специальные файлы устройств
Однако, в отличие от обычных файлов, специальные файлы устройств в действительности есть только указатели на соответствующие драйверы устройств в ядре. По сравнению с обычными файлами файлы устройств имеют три дополнительных атрибута, которые характеризуют устройство, соответствующее данному файлу:
Класс устройства. В ОС Linux различают устройства блок-ориентированные и байт-ориентированные. Блок-ориентированные (или блочные) устройства, например, жесткий диск, передают данные блоками. Байт-ориентированные (или символьные) устройства, например, принтер и модем, передают данные посимвольно, как непрерывный поток байтов. Взаимодействие с блочными устройствами может осуществляться лишь через буферную память, а для символьных устройств буфер не требуется. Кроме этих двух классов устройств имеются еще два — небуферизованные байт-ориентированные устройства и именованные каналы (FIFO).
Старший номер устройства, обозначающий тип устройства, например, жесткий диск или звуковая плата. Текущий список старших номеров устройств можно найти в файле /usr/include/linux/major.h. Вот небольшая выдержка из этого списка
Таблица 9.1. Старшие номера некоторых устройств
Старший номер
Файлы устройств одного типа имеют одинаковые имена и различаются по номеру, прибавляемому к имени. Например, все файлы сетевых плат Ethernet имеют имена, начинающиеся на eth: eth0, eth1 и т. д.
Младший номер устройства применяется для нумерации устройств одного типа, т. е. устройств с одинаковыми старшими номерами.
Если вы заглянете в каталог /dev и выполните команду ls –l, вы увидите, что эта команда вместо размера файла в байтах, как для обычного файла, выводит два числа, разделенных запятой. Это и есть старший и младший номера данного устройства. Эти номера задаются в соответствии с таблицей устройств, определенной разработчиками ядра.
Старшие номера известных ядру устройств можно увидеть, выполнив команду
[user]$ cat /proc/devices
Если вы решили подключить к системе какое- то новое устройство, необходимо вначале проверить, что в каталоге /dev имеется специальный файл (или ссылка на специальный файл) для этого устройства. Специальные файлы устройств создаются с помощью команды mknod (но, естественно, использовать команду mknod без необходимости и полного понимания последствий не стоит). Эта команда имеет следующий формат:
mknod [опции] имя_устройства тип_устройства старший_номер младший_номер
где тип_устройства может принимать одно из четырех значений: b — блок-ориентированное устройство; c — байт-ориентированное (символьное) устройство; u — небуферизованное байт-ориентированное устройство; p — именованный канал.
Для блок-ориентированных и байт-ориентированных устройств (b, c, u) нужны и старший и младший номера, для именованных каналов номера не используются. В следующем примере создается специальный файл для терминала, подключенного к порту COM3, который в Linux обозначается как /dev/ttyS2:
[root]# mknod -m 660 /dev/ttyS2 c 4 66
(устройства-терминалы представляют собой байт-ориентированные устройства со старшим номером 4 и младшими номерами, которые начинаются с 64).
Но вот о чем стоит подумать, так это о том, как дать пользователям права, необходимые для доступа к устройствам. Эти права устанавливаются через атрибуты специальных файлов. Можно, например, дать всем пользователям полные права (chmod 666) на доступ к таким устройствам, как /dev/cdrom, /dev/floppy, /dev/modem и так далее. Можете поступить иначе, создав группу "cdrom", сделать /dev/cdrom принадлежащим группе cdrom, а потом добавлять пользователей в эту группу по мере необходимости. Аналогичную процедуру можно применить к другим устройствам.
Таблицы кодировки символов
В человеческом мире информация представляется последовательностями символов. Каждый символ имеет каноническое изображение, которое позволяет однозначно идентифицировать данный символ. Шрифты задают разные варианты начертания символов.
В вычислительных машинах для представления информации используются цепочки байтов. Поэтому для перевода информации из машинного представления в человеческий необходимы таблицы кодировки символов — таблицы соответствия между символами определенного языка и кодами символов.
Самой известной таблицей кодировки является код ASCII (Американский стандартный код для обмена информацией), который был разработан для передачи текстов по телеграфу задолго до появления компьютеров. Этот код является 7 битовым, т. е. для кодирования символов английского языка, служебных и управляющих символов используются только 128 7-битовых комбинаций. При этом первые 32 комбинации (кода) служат для кодирования управляющих сигналов (начало текста, конец строки, перевод каретки, звонок, конец текста и т. д.).
При разработке первых компьютеров фирмы IBM этот код был использован для представления символов в компьютере. Поскольку в исходном коде ASCII было всего 128 символов, для их кодирования хватило тех однобайтовых кодов, у которых 8-й бит равен 0. Во второй половине кодовой таблицы (значения байта с 8-м битом равным 1) фирма IBM разместила символы псевдографики, математические знаки и некоторые символы из языков, отличных от английского (немецкие умляуты, французские диакритические знаки, символы греческого алфавита и т.п.). Эту кодовую таблицу стали называть кодировкой IBM.
Когда IBM-совместимые персональные компьютеры стали использовать в других странах, потребовалось обеспечить обработку информации на языках, отличных от английского. Для того, чтобы полноценно поддерживать другие языки, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так для скандинавских стран была предложена таблица 865 (Nordic), для арабских стран — таблица 864 (Arabic), для Израиля — таблица 862 (Israel) и так далее. В этих таблицах часть кодов из второй половины кодовой таблицы использовалась для представления символов национальных алфавитов (за счет исключения некоторых символов псевдографики). Для представления символов кириллицы была введена кодировка IBM-866.
Однако с русским языком ситуация развивалась особым образом. Очевидно, что замену символов во второй половине кодовой таблицы можно произвести разными способами. В других европейских странах сумели найти единое решение, а для русского языка появилось несколько разных таблиц кодировки символов кириллицы: IBM-866, CP-1251, KOI8-R, ISO-8859-5. Все они одинаково изображают символы первой половины таблицы (от 0 до 127) и различаются представлением символов русского алфавита и псевдографики во второй половине.
Одна из самых известных кодовых таблиц для кириллицы получила название альтернативной (по отношению к кодировке IBM-866, наверное). Она была разработана фирмой Microsoft для MS-DOS. При ее разработке постарались сделать так, чтобы результирующая таблица была насколько это возможно совместима с кодировкой IBM. Поэтому альтернативная кодировка — это кодировка IBM, в которой все специфические европейские символы в верхней половине были заменены на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портило вид программ, использующих для работы текстовые окна, что было очень существенным фактором для работы в среде MS-DOS, основой которой был именно текстовый режим.
Кодировка KOI-8 была разработана изначально с ориентировкой на UNIX. Так как UNIX в своей основе сетевая ОС, то основной идей при создании KOI-8 была идея об обеспечении перемещения кириллической информации по сети. Но для передачи-то использовался 7-битный стандарт ASCII. Разработчики поместили кириллические символы в верхней части таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что, если в тексте, написанном в KOI-8, мы убираем восьмой бит каждого символа, то мы все еще имеем "читабельный" текст, хотя он и написан английскими символами! Не удивительно, что KOI8-R быстро стал фактически стандартом для кириллицы в Интернет, что и нашло отражение в RFC 1489 ("Registration of a Cyrillic Character Set"). Автором этого документа является Андрей А. Чернов, который проделал огромный объем работы, чтобы превратить KOI-8 в стандарт Интернет.
Международная организация по стандартизации (ISO) внесла свою лепту в создание различных кодировок кириллицы, когда ввела семейство стандартов, известных как ISO 8859-X. Это семейство есть совокупность 8-битных кодировок, где младшая половина каждой кодировки (символы с кодами 0—127) соответствует ASCII, а старшая половина определяет символы для различных языков. Например: 8859-0 — новый европейский стандарт (так называемый Latin 0); 8859-1 — Европа, Латинская Америка (также известный как Latin 1); 8859-2 — Восточная Европа; 8859-5 — кириллица; 8859-8 — идиш.
Фирма Microsoft еще больше запутала ситуацию с кодировками для русского языка, когда при разработке Windows ввела кодировку CP-1251.
Таблицы кодировок, содержащие 256 символов, стали называть расширенными кодами ASCII (потому что в основе любой из них лежит 128-символьный код ASCII), кодовыми страницами или английским термином character set (который часто сокращают до charset).
Но в мире есть языки, такие как китайский или японский, для которых 256 символов в принципе недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках (например, при цитировании). Поэтому была разработана универсальная кодовая таблица UNICODE, содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т. д.). Очевидно, что одного байта недостаточно для кодирования такого большого множества символов. Поэтому в UNICODE используются 16-битовые (2-байтовые) коды, что позволяет представить 65 536 символов. К настоящему времени задействовано около 49 000 кодов (последнее значительное изменение — введение символа валюты EURO в сентябре 1998 г.). Для совместимости с предыдущими кодировками первые 128 кодов совпадают со стандартом ASCII. На рис. 9.1 схематично представлено размещение символов разных языков в кодовом пространстве UNICODE.
Рис. 9.1. Структура UNICODE.
В стандарте UNICODE кроме определенного двоичного кода (эти коды принято обозначать буквой U, после которой следуют знак + и собственно код в шестнадцатеричном представлении) каждому символу присвоено определенное имя. В следующей таблице приведено несколько примеров кодов и имен символов из стандарта UNICODE.
Таблица 9.2. Примеры именования кодов UNICODE
Символ
Еще одним компонентом стандарта UNICODE являются алгоритмы для взаимно-однозначного преобразования кодов UNICODE в последовательности байтов переменной длины. Необходимость таких алгоритмов обусловлена тем, что не все приложения умеют работать с UNICODE. Некоторые приложения понимают только 7-битовые ASCII-коды, другие приложения — 8-битовые (расширенные) ASCII-коды. Для представления символов, не поместившихся, соответственно, в 128 символьный или 256 символьный набор, такие приложения используют цепочки байтов переменной длины. Алгоритм UTF-7 служит для обратимого преобразования кодов UNICODE в цепочки 7-битовых ASCII-кодов, а UTF-8 — для обратимого преобразования кодов UNICODE в цепочки из расширенных 8-битовых ASCII-кодов. Подробнее об алгоритмах UTF-7 и UTF-8 и кодировках вообще вы можете прочитать в .
Отметим, что и ASCII, и UNICODE, и другие стандарты кодировки символов не определяют изображения символов, а только состав набора символов и способ его представления в компьютере. Кроме того (что, может быть, не сразу очевидно) они еще задают порядок перечисления символов в наборе, который очень важен, так как он влияет самым существенным образом на алгоритмы сортировки. Именно таблицу соответствия символов из какого-то определенного набора (скажем, символов, применяемых для представления информации на английском языке, или на разных языках, как в случае с UNICODE) и обозначают термином таблица кодировки символов или charset. Каждая стандартная кодировка имеет имя, например, KOI8-R, ISO_8859-1, ASCII. К сожалению, стандарта на имена кодировок не существует.
Традиционные средства печати UNIX
Исторически для печати в UNIX-системах существовали две системы печати: LPD (Line Printer Daemon) [RFC1179], разработанная для Berkeley UNIX (или BSD-система), и AT&T Line Printer system. Эти системы печати были созданы в 70-х годах для печати текстов на построчно-печатающих (линейных) принтерах. Принимая во внимание, что аппаратные средства печати (проще говоря, принтеры) с тех пор существенно изменились, можно было бы предположить, что существенно переработаны и программные средства для управления печатью. Однако, этого не произошло. Хотя и были созданы различные улучшенные системы печати [LPRng, Palladin, PLP], однако ни одна из этих новых разработок не изменяла фундаментальные возможности этих систем. Впрочем, как показало время и практика, возможности этих систем вполне достаточны и при небольших доработках удовлетворяют и современные потребности.
Как и во всех UNIX-системах, в Linux файл, предназначенный для печати, вначале пересылается во временную область (проще говоря, временный каталог), которая называется областью спулинга. Дело в том, что принтеры являются относительно медленными устройствами, и система заботится о том, чтобы не задерживать работу на время распечатки файла. Фоновый процесс — демон печати — постоянно сканирует область спулинга в ожидании файлов, предназначенных для печати. Для каждого принтера, подключенного к системе, заводится своя область спулинга. Таким образом, область спулинга представляет собой очередь заданий на печать, дожидающихся того момента, когда освободится соответствующий принтер и демон печати отправит данное задание на печать (в фоновом режиме).
В основу подсистемы печати в Linux положена BSD-система — LPD, а точнее, доработанный вариант этой системы LPRng. LPRng состоит из отдельных программ, которые обеспечивают выполнение отдельных функций подсистемы печати.
lpd — демон системы печати. Обычно запускается на этапе загрузки системы из файла rc, но может быть запущен и пользователем.
lpr — пользовательская команда печати. Программа lpr принимает подлежащие печати данные и помещает их в буферный каталог, где их находит lpd и выводит на печать. Программа lpr — единственная программа, которая может ставить новые задания в очередь печати. Другие программы, которым необходимо использовать печать, обращаются для этого к lpr.
lpq — программа, позволяющая просматривать очередь заданий, ожидающих печати на указанном принтере.
lpc — команда контроля системы lpd. С помощью lpc можно отключать принтеры, останавливать или переупорядочивать очереди печати и т.п. Некоторые из функций этой команды доступны пользователям, но в основном это средство для администратора.
lprm — эта команда позволяет удалить одно или несколько заданий из очереди печати. При этом стираются соответствующие файлы данных и из системы печати удаляются все ссылки на них.
Взаимодействие lpr и других программ этого набора с демоном lpd осуществляется с использованием сетевых средств, так что они могут запускаться и на других компьютерах. Рассмотрим вкратце, как осуществляется печать файла в системе LPD.
Когда вызывается программа lpr, она первым делом выбирает принтер, на который будет производиться печать. Этот выбор определяется либо параметром командной строки Pprinter, либо значением переменной окружения PRINTER, либо же используется общесистемный принтер, заданный по умолчанию (это принтер с именем lp). Как только lpr узнает, на какой принтер отправлять текущее задание, она ищет описание этого принтера в базе данных об имеющихся принтерах, которая хранится в файле /etc/printcap. Из этой базы lpr получает имя каталога (области спулинга), в который следует помещать задания для найденного принтера. Обычно этот буферный каталог имеет имя /var/spool/lpd/printer. Такой каталог (область спулинга) должен существовать, если вы хотите печатать на принтере с именем printer.
Для каждого задания программа lpr помещает в буферный каталог два файла: cfxxx и dfxxx, где xxx — номер текущего задания. Файл cfxxx содержит справочную информацию и информацию об обработке задания. Источником этих сведений являются командная строка запуска программы, переменные среды процесса, который запустил эту программу, и глобальная конфигурация системы. Файл dfxxx содержит данные, подлежащие печати.
После постановки задания в очередь lpr уведомляет демона lpd о появлении задания на печать. Взаимодействие lpr с lpd происходит через именованный сокет /dev/printer. Демон lpd тоже обращается к файлу /etc/printcap, чтобы узнать, какой принтер должен использоваться для печати, и является он локальным или удаленным. Если в /etc/printcap указано, что принтер подключен локально, lpd проверяет наличие демона печати, обрабатывающего соответствующую очередь. Дело в том, что для обработки каждой очереди lpd создает отдельную копию самого себя. Если такой копии еще не имеется, она создается и ей передается обработка очереди. Если соответствующий принтер подключен к другой машине, lpd устанавливает соединение с демоном lpd удаленной машины и пересылает туда файл данных и управляющий файл.
Обслуживание заданий печати осуществляется по правилу "первым пришел — первым обслужен" (FIFO). Системный администратор может при желании изменить порядок печати с помощью программы lpc.
Начиная с ядра 2.1.33 устройство lp является клиентом нового устройства parport. Введение parport решает некоторые проблемы, связанные с lp — теперь можно разделять параллельные порты с другими драйверами, динамически связывать порты с устройствами, не устанавливая жесткого соответствия между адресами I/O и номером порта и т. д. Подробнее об этом вы можете прочитать в статье .
Ввод символов с клавиатуры
В процессе ввода символов с клавиатуры можно выделить четыре соответствия или отображения (в математическом смысле этого слова).
- На клавиатуру нанесены (или наклеены) символы. Это первое соответствие: символ -> клавиша. Микропроцессор клавиатуры реализует второе соответствие: комбинация клавиш -> скан-код. Далее скан-код клавиатуры преобразуется в код символа, понятный приложению, например, ASCII-код или UNICODE; это третье соответствие: скан-код -> код символа, используемый приложением. И, наконец, для изображения символа на экране или принтере используется четвертое соответствие: ASCII-код -> изображение символа.
О наличии этих соответствий полезно помнить при рассмотрении вопросов взаимодействия пользователя с приложениями. А теперь вернемся к вопросу о том, как работает клавиатура.
Управление работой клавиатуры в текстовом режиме осуществляется драйвером терминала, который входит в состав ядра Linux. Драйвер терминала состоит как бы из двух отдельных драйверов: драйвера клавиатуры и драйвера экрана. Драйвер клавиатуры обрабатывает нажатия клавиш пользователем и передает результат прикладной программе, которая, в свою очередь, посылает экранному драйверу символы, которые должны быть отображены на экране.
При каждом нажатии на клавишу микропроцессор клавиатуры генерирует последовательность так называемых скан-кодов, которая представляет собой последовательность из двух или большего числа байтов. Эта последовательность передается драйверу клавиатуры, который может работать в одном из 4 режимов:
K_RAW, когда прикладной программе передается последовательность скан-кодов, сгенерированных клавиатурой. Этот режим используется при работе с приложениями, которые имеют собственный драйвер клавиатуры. Примером такого приложения является система X Window.
K_MEDIUMRAW, когда скан-код клавиши преобразуется в один из 127 возможных кодов, называемых кодами клавиш (keycodes). Каждый код клавиши состоит из кода нажатия клавиши и кода отпускания клавиши. Преобразование скан-кодов в коды клавиш осуществляется в соответствии с внутренней таблицей драйвера клавиатуры. Обычно эта таблица фиксирована, и изменять ее не требуется, хотя в системе существуют команды getkeycodes и setkeycodes, с помощью которых можно просмотреть или изменить некоторые соответствия в этой таблице. Эти команды используются только в том случае, если у вас программируемая клавиатура.
K_XLATE (или режим ASCII), когда код клавиши преобразуется в ASCII-код символа или некоторую последовательность ASCII-кодов символов в соответствии с таблицей раскладки клавиатуры, которая хранится в виде отдельного файла. Например, для Red Hat Linux 5.2 по умолчанию используется файл defkeymap.map в каталоге /usr/lib/kbd/keymaps/i386/qwerty. Команда dumpkeys выводит на экран содержание действующей в данный момент таблицы раскладки клавиатуры, а команда loadkeys загружает в драйвер таблицу раскладки клавиатуры из указанного файла.
K_UNICODE, когда скан-коды преобразуются в двухбайтовые коды таблицы UNICODE (этот режим пока используется очень редко).
Выбор режима работы драйвера терминала определяется прикладной программой, которая в данный момент времени выполняется компьютером. Чаще всего используется третий режим, когда код клавиши либо преобразуется в ASCII-код символа или строку таких кодов в соответствии с таблицей раскладки клавиатуры, либо выполняется действие, определенное для конкретной комбинации клавиш в таблице раскладки клавиатуры. Например, нажатие <Ctrl>+<Alt>+<Del> эквивалентно вызову команды shutdown -r 0, т. е. приводит к останову системы и перезагрузке компьютера.
Режим работы драйвера клавиатуры можно узнать или изменить с помощью команды kbd_mode. Однако не торопитесь менять режим, так как перевод драйвера клавиатуры в режим RAW или MEDIUMRAW может сделать его недоступным для большинства приложений, т. е. легко можно вообще потерять возможность ввода команд.
Не для всех клавиш и комбинаций клавиш процесс обработки проходит так прямолинейно, как это описано выше. Во-первых, имеется несколько особых клавиш, так называемых клавиш-переключателей. Это клавиши <Shift> (левая и правая), <Alt> (левая и правая), <Ctrl> (левая и правая), <Caps Lock>, <Num Lock>, <Ins>. Нажатие на клавишу-переключатель изменяет значение одного из разрядов (битов) в двухбайтовом слове, которое хранит состояние клавиш-переключателей. Поэтому драйвер клавиатуры вначале должен проанализировать состояние этого слова, а затем соответственно преобразовать коды.
Клавиша <Ins> является единственной из клавиш переключателей, нажатие которой не только заносит признак в слово состояния переключателей, но и порождает передачу соответствующего кода драйверу терминала.
С помощью ASCII-кодов можно представить 256 различных символов, а, значит, ASCII-коды можно сопоставить 256-ти кодам клавиш. Учитывая наличие клавиш переключателей, комбинаций клавиш существует гораздо больше. Поэтому некоторые комбинации клавиш драйвер клавиатуры преобразует в цепочки из нескольких байтов, так называемые Escape-последовательности, в которых два первых байта служат признаком Escape-последовательности, а последующие представляют собой собственно значащие байты. Escape-последовательности обычно представляют те комбинации клавиш, которые используются для управления работой программ, таких как стрелки, клавиши <Page Down>, <Page Up>, <Home>, <End>, <F1> — <F12>, <Ins>, <Del> и т. д.
В комплект Red Hat Linux входит программа showkey, которая показывает все три вида кодов, связанных с нажатиями клавиш. Если запустить эту программу с параметром -s, она будет показывать скан-коды нажатий клавиш (чтобы выйти из программы, надо просто выждать 10 секунд, не нажимая в это время ни одной клавиши). Ввод команды showkey -k приводит к выводу на экран кодов клавиш (выходим так же). Ввод команды showkey -m позволяет просмотреть ASCII-коды, которые выдаются драйвером клавиатуры после того, как скан-код клавиши будет оттранслирован с помощью таблицы раскладки клавиатуры. Попробуйте в этом режиме нажать <Ctrl>+<=> или <Ctrl>+<Esc>, и вы увидите, что не каждая комбинация клавиш порождает ASCII-код (попробуйте также клавиши-переключатели). В новых версиях программы showkey появилась опция –u, при которой отображаются коды UNICODE.
Примечания:
Если вы уже перешли в графический режим, то программа showkey может работать некорректно, о чем она вежливо сообщает при запуске. Обратите внимание на эти сообщения! Кстати, showkey неправильно работает не только в графическом режиме, но и при подключении через telnet и т.п.
Поскольку чаще всего используется режим преобразования в ASCII-коды, например, при работе в текстовом режиме и в эмуляторе терминала, таблица раскладки клавиатуры имеет такое большое значение. Возможно, вас не устраивает та раскладка, которая используется по умолчанию. Давайте рассмотрим, как ее поменять.
Zip-диск фирмы Iomega для параллельного порта
Для того, чтобы использовать Zip-дисковод, подключаемый к параллельному порту, вы можете использовать драйвер ppa, скомпилированный либо в составе ядра, либо в виде отдельного модуля. В последнем случае необходимо либо добавить строку insmod ppa в файл /etc/rc.d/rc.sysinit, либо просто каждый раз подключать нужный модуль той же командой insmod ppa. После этого вы будете иметь возможность смонтировать диск, установленный в ZIP-дисководе фирмы Iomega, с помощью обычной команды
mount -t vfat /dev/sda4 /mnt/zip.
Может оказаться, что команда insmod ppa не срабатывает (например, если не скомпилирован модуль поддержки ppa). В этом случае после выполнения команды insmod ppa появляется сообщение об ошибке, и получить доступ к Zip-диску этим способом не удается. У меня такая ситуация возникла после перехода с версии 5.2 дистрибутива Black Cat на версию 6.02.
Тем не менее, мне удалось получить доступ к Zip-дискам. Я нашел пакет lomega версии 1.0.1 (обратите внимание на название программы — lomega, а не iomega), созданный Джоном Хоком (John Hawk, e-mail: visionary@gtemail.net). Этот пакет дает возможность работать под Linux с дисками Zip и/или Jaz фирмы Iomega. После обычной процедуры установки tar-gz-пакета (которая выполнялась с правами суперпользователя), мне легко удалось (все еще с правами суперпользователя и при условии, что в дисководе имеется носитель) смонтировать ZIP-диск.
Для того, чтобы монтирование дисков могли выполнять обычные пользователи, необходимо (от имени root) выполнить следующие команды:
[root]# chown root:root /directory/lomega.
[root]# chmod +s /directory/lomega.
Помимо обычного способа доступа к диску командами mount/umount, можно запустить отдельную программу /usr/local/bin/lomega. Запускается она только в графическом режиме и представляет собой интерфейс для работы с Zip-диском. С помощью этой программы можно смонтировать и размонтировать Zip-диск, защитить диск от записи или снять эту защиту, а также извлечь носитель из дисковода простым щелчком мыши по соответствующей кнопке. Отметим только, что для того, чтобы установить защиту от записи, необходимо размонтировать диск.
В окне программы можно увидеть статус диска (смонтирован, размонтирован, защищен ли от записи), просмотреть содержимое файловой системы и отдельно — файлы на Zip-диске, а также сделать back-up выбранных файлов. Для этого надо просто отметить нужные файлы в окне программы и нажать экранную кнопку Back Up. После этого будет выведено диалоговое окно, в котором вы можете изменить предлагаемые по умолчанию параметры команды архивации tar. Таким образом, программа lomega предоставляет удобный интерфейс для архиватора tar.
Щелкнув правой кнопкой мыши в окне программы, вы получите выпадающее меню, с помощью которого можно выполнить много разных команд, в частности, удалить некоторые файлы и каталоги. При этом удаляемые файлы фактически не уничтожаются, а просто перемещаются в "корзину" (trash), откуда их, при необходимости, можно еще восстановить. Однако эта возможность сохраняется только до тех пор, пока вы не опустошили корзину командой "Empty Trash", которую можно вызвать через то же выпадающее меню.
Программа lomega использует конфигурационный файл /etc/lomega.conf. Структура этого файла подобна структуре файла /etc/fstab и не требует подробных пояснений.
При запуске программы можно задать в командной строке следующие опции:
-e — открывает окно файлового менеджера;
-v — просто выводит версию программы;
/dev/sda — указывает имя используемого устройства (должно иметься в файле lomega.conf).
Помимо двух уже описанных, имеется еще один способ получения доступа к Zip-диску из Linux: с помощью пакета mtools. Этот пакет, конечно, необходимо предварительно установить, а затем добавить следующую строку в файл /etc/mtools.conf:
drive z: file="/dev/sda4" exclusive
И все же основным способом подключения Zip-дисковода остается первый из трех описанных — с помощью модуля ppa. Упомянутые выше затруднения возникли у меня только с одной версией дистрибутива. После перехода на Red Hat 7.1 и ALT Linux Junior 1.0 (на двух разных компьютерах) я без затруднений подключаю Zip-диски стандартным способом.
Звуковая карта
Если у вас одна из последних версий Red Hat Linux, запустите программу sndconfig. Делать это надо от имени суперпользователя и только в консольном режиме. Первым делом эта программа попытается сама определить наличие у вас звуковой карты (рис. 9.9).
Рис. 9.9. Запуск программы sndconfig
Для этого она вызывает утилиту isapnptools. Если автоматически определить карту не удается, вам придется самому выбрать тип карты из списка (рис. 9.10).
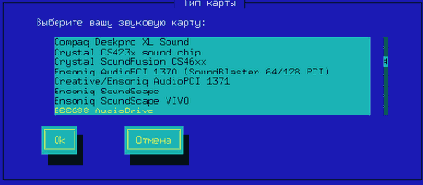
Рис. 9.10. Выбор типа звуковой карты
Далее программа спросит вас о таких установках звуковой карты, как адрес порта ввода/вывода (I/O base address), IRQ, DMA, и 16-bit DMA (рис. 9.12). Будьте готовы ответить на эти вопросы. Затем программа попробует воспроизвести 2 музыкальных фрагмента, после каждого из которых спросит вас, слышали ли вы что-нибудь. Если вы ответите положительно, будет создан файл /etc/modules.conf, и вам остается только установить программу-проигрыватель, вроде xmms (о программах воспроизведения чуть позже, в гл. 15).
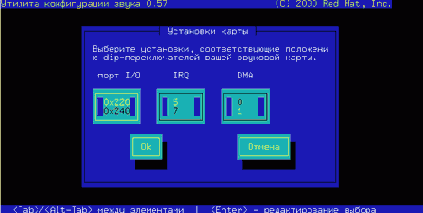
Рис. 9.11. Выбор параметров звуковой карты
У меня установка звуковой карты и программы x11amp (с дистрибутивного диска) прошли почти без запинки (пришлось только подобрать порт, предлагаемое по умолчанию значение почему-то оказалось неподходящим), после чего я смог прослушивать записи из mp3-файлов так же, как делал это раньше под Windows с помощью winamp. Кстати, программа x11amp теперь называется xmms.
Если у вас возникнут какие-то затруднения, обратитесь к "Звук в Linux HOWTO" .
