Распределение памяти
Ядро постоянно располагается в оперативной памяти, наряду с выполняющимся в данный момент процессом (или частью его, по меньшей мере). В процессе компиляции программа-компилятор генерирует последовательность адресов, являющихся адресами переменных и информационных структур, а также адресами инструкций и функций. Компилятор генерирует адреса для виртуальной машины так, словно на физической машине не будет выполняться параллельно с транслируемой ни одна другая программа.
Когда программа запускается на выполнение, ядро выделяет для нее место в оперативной памяти, при этом совпадение виртуальных адресов, сгенерированных компилятором, с физическими адресами совсем необязательно. Ядро, взаимодействуя с аппаратными средствами, транслирует виртуальные адреса в физические, т.е. отображает адреса, сгенерированные компилятором, в физические, машинные адреса. Такое отображение опирается на возможности аппаратных средств, поэтому компоненты системы UNIX, занимающиеся им, являются машинно-зависимыми. Например, отдельные вычислительные машины имеют специальное оборудование для подкачки выгруженных страниц памяти. Главы и посвящены более подробному рассмотрению вопросов, связанных с распределением памяти, и исследованию их соотношения с аппаратными средствами.
Comments:
Copyright ©
СМЕНА ТЕКУЩЕГО И КОРНЕВОГО КАТАЛОГА
Когда система загружается впервые, нулевой процесс делает корневой каталог файловой системы текущим на время инициализации. Для индекса корневого каталога нулевой процесс выполняет алгоритм iget, сохраняет этот индекс в пространстве процесса в качестве индекса текущего каталога и снимает с индекса блокировку. Когда с помощью функции fork создается новый процесс, он наследует текущий каталог старого процесса в своем адресном пространстве, а ядро, соответственно, увеличивает значение счетчика ссылок в индексе.
Алгоритм chdir () изменяет имя текущего каталога для процесса. Синтаксис вызова системной функции chdir: chdir(pathname);
где pathname - каталог, который становится текущим для процесса. Ядро анализирует имя каталога, используя алгоритм namei, и проверяет, является ли данный файл каталогом и имеет ли владелец процесса право доступа к каталога. Ядро снимает с нового индекса блокировку, но удерживает индекс в качестве выделенного и оставляет счетчик ссылок без изменений, освобождает индекс прежнего текущего каталога (алгоритм iput), хранящийся в пространстве процесса, и запоминает в этом пространстве новый индекс. После смены процессом текущего каталога алгоритм namei использует индекс в качестве начального каталога при анализе всех имен путей, которые не берут начало от корня. По окончании выполнения системной функции chdir счетчик ссылок на индекс нового каталога имеет значение, как минимум, 1, а счетчик ссылок на индекс прежнего текущего каталога может стать равным 0. В этом отношении функция chdir похожа на функцию open, поскольку обе функции обращаются к файлу и оставляют его индекс в качестве выделенного. Индекс, выделенный во время выполнения функции chdir, освобождается только тогда, когда процесс меняет текущий каталог еще раз или когда процесс завершается.
Процессы обычно используют глобальный корневой каталог файловой системы для всех имен путей поиска, начинающихся с "/". Ядро хранит глобальную переменную, которая указывает на индекс глобального корня, выделяемый по алгоритму iget при загрузке системы. Процессы могут менять свое представление о корневом каталоге файловой системы с помощью системной функции chroot. Это бывает полезно, если пользователю нужно создать модель обычной иерархической структуры файловой системы и запустить процессы там. Синтаксис вызова функции: chroot(pathname);
где pathname - каталог, который впоследствии будет рассматриваться ядром в качестве корневого каталога для процесса. Выполняя функцию chroot, ядро следует тому же алгоритму, что и при смене текущего каталога. Оно запоминает индекс нового корня в пространстве процесса, снимая с индекса блокировку по завершении выполнения функции. Тем не менее, так как умолчание на корень для ядра хранится в глобальной переменной, ядро освобождает индекс прежнего корня не автоматически, а только после того, как оно само или процесс-предок исполнят вызов функции chroot. Новый индекс становится логическим корнем файловой системы для процесса (и для всех порожденных им процессов) и это означает, что все пути поиска в алгоритме namei, начинающиеся с корня ("/"), возьмут начало с данного индекса и что все попытки войти в каталог ".." над корнем приведут к тому, что рабочим каталогом процесса останется новый корень. Процесс передает всем вновь порождаемым процессам этот каталог в качестве корневого подобно тому, как передает свой текущий каталог.
Comments:
Copyright ©
АБСТРАКТНЫЕ ОБРАЩЕНИЯ К ФАЙЛОВЫМ СИСТЕМАМ
Уайнбергером было введено понятие "тип файловой системы" для объяснения механизма работы принадлежавшей ему сетевой файловой системы (см. краткое описание этого механизма в [Killian 84]) и в позднейшей версии системы V поддерживаются основополагающие принципы его схемы. Наличие типа файловой системы дает ядру возможность поддерживать одновременно множество файловых систем, таких как сетевые файловые системы () или даже файловые системы из других операционных систем. Процессы пользуются для обращения к файлам обычными функциями системы UNIX, а ядро устанавливает соответствие между общим набором файловых операций и операциями, специфичными для каждого типа файловой системы.
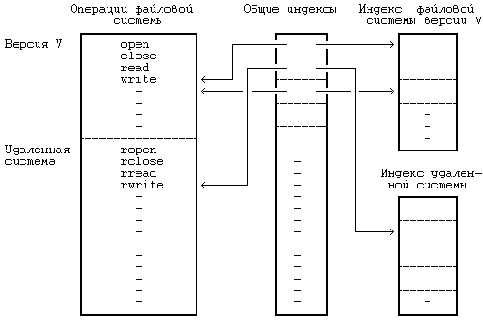
Рисунок 5.34. Индексы для файловых систем различных типов
Индекс выступает интерфейсом между абстрактной файловой системой и отдельной файловой системой. Общая копия индекса в памяти содержит информацию, не зависящую от отдельной файловой системы, а также указатель на частный индекс файловой системы, который уже содержит информацию, специфичную для нее. Частный индекс файловой системы содержит такую информацию, как права доступа и расположение блоков, а общий индекс содержит номер устройства, номер индекса на диске, тип файла, размер, информацию о владельце и счетчик ссылок. Другая частная информация, описывающая отдельную файловую систему, содержится в суперблоке и структуре каталогов. На Рисунке 5.34 изображены таблица общих индексов в памяти и две таблицы частных индексов отдельных файловых систем, одна для структур файловой системы версии V, а другая для индекса удаленной (сетевой) системы. Предполагается, что последний индекс содержит достаточно информации для того, чтобы идентифицировать файл, находящийся в удаленной системе. У файловой системы может отсутствовать структура, подобная индексу; но исходный текст программ отдельной файловой системы позволяет создать объектный код, удовлетворяющий семантическим требованиям файловой системы UNIX и назначающий свой "индекс", который соответствует общему индексу, назначаемому ядром.
Файловая система каждого типа имеет некую структуру, в которой хранятся адреса функций, реализующих абстрактные действия. Когда ядру нужно обратиться к файлу, оно вызывает косвенную функцию в зависимости от типа файловой системы и абстрактного действия (). Примерами абстрактных действий являются: открытие и закрытие файла, чтение и запись данных, возвращение индекса для компоненты имени файла (подобно namei и iget), освобождение индекса (подобно iput), коррекция индекса, проверка прав доступа, установка атрибутов файла (прав доступа к нему), а также монтирование и демонтирование файловых систем. будет проиллюстрировано использование системных абстракций при рассмотрении распределенной файловой системы.
Comments:
Copyright ©
Алгоритм
Сразу после переключения контекста ядро запускает алгоритм планирования выполнения процессов (), выбирая на выполнение процесс с наивысшим приоритетом среди процессов, находящихся в состояниях "резервирования" и "готовности к выполнению, будучи загруженным в память". Рассматривать процессы, не загруженные в память, не имеет смысла, поскольку не будучи загружен, процесс не может выполняться. Если наивысший приоритет имеют сразу несколько процессов, ядро, используя принцип кольцевого списка (карусели), выбирает среди них тот процесс, который находится в состоянии "готовности к выполнению" дольше остальных. Если ни один из процессов не может быть выбран для выполнения, ЦП простаивает до момента получения следующего прерывания, которое произойдет не позже чем через один таймерный тик; после обработки этого прерывания ядро снова запустит алгоритм планирования.
| алгоритм schedule_process входная информация: отсутствует выходная информация: отсутствует { выполнять пока (для запуска не будет выбран один из про- цессов) { для (каждого процесса в очереди готовых к выполнению) выбрать процесс с наивысшим приоритетом из загру- женных в память; если (ни один из процессов не может быть избран для выполнения) приостановить машину; /* машина выходит из состояния простоя по преры- /* ванию */ } удалить выбранный процесс из очереди готовых к выполне- нию; переключиться на контекст выбранного процесса, возобно- вить его выполнение; } |
Рисунок 8.1. Алгоритм планирования выполнения процессов
Алгоритмы приостанова и возобновления выполнения
На приведен алгоритм приостанова процесса. Сначала ядро повышает приоритет работы процессора так, чтобы заблокировать все прерывания, которые могли бы (путем создания конкуренции) помешать работе с очередями приостановленных процессов, и запоминает старый приоритет, чтобы восстановить его, когда выполнение процесса будет возобновлено. Процесс получает пометку "приостановленного", адрес приостанова и приоритет запоминаются в таблице процессов, а процесс помещается в хеш-очередь приостановленных процессов. В простейшем случае (когда приостанов не допускает прерываний) процесс выполняет переключение контекста и благополучно "засыпает". Когда приостановленный процесс "пробуждается", ядро начинает планировать его запуск: процесс возвращает сохраненный в алгоритме sleep контекст, восстанавливает старый приоритет работы процессора (который был у него до начала выполнения алгоритма) и возвращает управление ядру.
| алгоритм wakeup /* возобновление приостановленного про- цесса */ входная информация: адрес приостанова выходная информация: отсутствует { повысить приоритет работы процессора таким образом, что- бы заблокировать все прерывания; найти хеш-очередь приостановленных процессов с указанным адресом приостанова; для (каждого процесса, приостановленного по указанному адресу) { удалить процесс из хеш-очереди; сделать пометку о том, что процесс находится в состо- янии "готовности к запуску"; включить процесс в список процессов, готовых к запус- ку (для планировщика процессов); очистить поле, содержащее адрес приостанова, в записи таблицы процессов; если (процесс не загружен в память) возобновить выполнение программы подкачки (нуле- вой процесс); в противном случае если (возобновляемый процесс более подходит для ис- полнения, чем ныне выполняющийся) установить соответствующий флаг для планировщи- ка; } восстановить первоначальный приоритет работы процессора; } |
Рисунок 6.32. Алгоритм возобновления приостановленного процесса
Чтобы возобновить выполнение приостановленных процессов, ядро обращается к алгоритму wakeup (), причем делает это как во время исполнения алгоритмов реализации стандартных системных функций, так и в случае обработки прерываний. Алгоритм iput, например, освобождает заблокированный индекс и возобновляет выполнение всех процессов, ожидающих снятия блокировки. Точно так же и программа обработки прерываний от диска возобновляет выполнение процессов, ожидающих завершения ввода-вывода. В алгоритме wakeup ядро сначала повышает приоритет работы процессора, чтобы заблокировать прерывания. Затем для каждого процесса, приостановленного по указанному адресу, выполняются следующие действия: делается пометка в поле, описывающем состояние процесса, о том, что процесс готов к запуску; процесс удаляется из списка приостановленных процессов и помещается в список процессов, готовых к запуску; поле в записи таблицы процессов, содержащее адрес приостанова, очищается. Если возобновляемый процесс не загружен в память, ядро запускает процесс подкачки, обеспечивающий подкачку возобновляемого процесса в память (подразумевается система, в которой подкачка страниц по обращению не поддерживается); в противном случае, если возобновляемый процесс более подходит для исполнения, чем ныне выполняющийся, ядро устанавливает для планировщика специальный флаг, сообщающий о том, что процессу по возвращении в режим задачи следует пройти через алгоритм планирования (). Наконец, ядро восстанавливает первоначальный приоритет работы процессора. При этом на ядро не оказывается никакого давления: "пробуждение" (wakeup) процесса не вызывает его немедленного исполнения; благодаря "пробуждению", процесс становится только доступным для запуска.
Все, о чем говорилось выше, касается простейшего случая выполнения алгоритмов sleep и wakeup, поскольку предполагается, что процесс приостанавливается до наступления соответствующего события. Во многих случаях процессы приостанавливаются в ожидании событий, которые "должны" наступить, например, в ожидании освобождения ресурса (индексов или буферов) или в ожидании завершения ввода-вывода, связанного с диском. Уверенность процесса в неминуемом возобновлении основана на том, что подобные ресурсы могут быть предоставлены только во временное пользование. Тем не менее, иногда процесс может приостановиться в ожидании события, не будучи уверенным в неизбежном наступлении последнего, в таком случае у процесса должна быть возможность в любом случае вернуть себе управление и продолжить выполнение. В подобных ситуациях ядро немедленно нарушает "сон" приостановленного процесса, посылая ему сигнал. Более подробно о сигналах мы поговорим в следующей главе; здесь же примем допущение, что ядро может (выборочно) возобновлять приостановленные процессы по сигналу и что процесс может распознавать получаемые сигналы.
Например, если процесс обратился к системной функции чтения с терминала, ядро не будет в состоянии выполнить запрос процесса до тех пор, пока пользователь не введет данные с клавиатуры терминала (). Тем не менее, пользователь, запустивший процесс, может оставить терминал на весь день, при этом процесс останется приостановленным в ожидании ввода, а терминал может понадобиться другому пользователю. Если другой пользователь прибегнет к решительным мерам (таким как выключение терминала), ядро должно иметь возможность восстановить отключенный процесс: в качестве первого шага ядру следует возобновить приостановленный процесс по сигналу. В том, что процессы могут приостановиться на длительное время, нет ничего плохого. Приостановленный процесс занимает позицию в таблице процессов и может поэтому удлинять время поиска (ожидания) путем выполнения определенных алгоритмов, которые не занимают время центрального процессора и поэтому выполняются практически незаметно.
Чтобы как- то различать между собой состояния приостанова, ядро устанавливает для приостанавливаемого процесса (при входе в это состояние) приоритет планирования на основании соответствующего параметра алгоритма sleep. То есть ядро запускает алгоритм sleep с параметром "приоритет", в котором отражается наличие уверенности в неизбежном наступлении ожидаемого события. Если приоритет превышает пороговое значение, процесс не будет преждевременно выходить из приостанова по получении сигнала, а будет продолжать ожидать наступления события. Если же значение приоритета ниже порогового, процесс будет немедленно возобновлен по получении сигнала .
Проверка того, имеет ли процесс уже сигнал при входе в алгоритм sleep, позволяет выяснить, приостанавливался ли процесс ранее. Например, если значение приоритета в вызове алгоритма sleep превышает пороговое значение, процесс приостанавливается в ожидании выполнения алгоритма wakeup. Если же значение приоритета ниже порогового, выполнение процесса не приостанавливается, но на сигнал процесс реагирует точно так же, как если бы он был приостановлен. Если ядро не проверит наличие сигналов перед приостановом, возможна опасность, что сигнал больше не поступит вновь и в этом случае процесс никогда не возобновится.
Когда процесс "пробуждается" по сигналу (или когда он не переходит в состояние приостанова из-за наличия сигнала), ядро может выполнить алгоритм longjump (в зависимости от причины, по которой процесс был приостановлен). С помощью алгоритма longjump ядро восстанавливает ранее сохраненный контекст, если нет возможности завершить выполняемую системную функцию. Например, если из-за того, что пользователь отключил терминал, было прервано чтение данных с терминала, функция read не будет завершена, но возвратит признак ошибки. Это касается всех системных функций, которые могут быть прерваны во время приостанова. После выхода из приостанова процесс не сможет нормально продолжаться, поскольку ожидаемое событие не наступило. Перед выполнением большинства системных функций ядро сохраняет контекст процесса, используя алгоритм setjump и вызывая тем самым необходимость в последующем выполнении алгоритма longjump.
Встречаются ситуации, когда ядро требует, чтобы процесс возобновился по получении сигнала, но не выполняет алгоритм longjump. Ядро запускает алгоритм sleep со специальным значением параметра "приоритет", подавляющим исполнение алгоритма longjump и заставляющим алгоритм sleep возвращать код, равный 1. Такая мера более эффективна по сравнению с немедленным выполнением алгоритма setjump перед вызовом sleep и последующим выполнением алгоритма longjump для восстановления первоначального контекста процесса. Задача заключается в том, чтобы позволить ядру очищать локальные структуры данных. Драйвер устройства, например, может выделить свои частные структуры данных и приостановиться с приоритетом, допускающим прерывания; если по сигналу его работа возобновляется, он освобождает выделенные структуры, а затем выполняет алгоритм longjump, если необходимо. Пользователь не имеет возможности проконтролировать, выполняет ли процесс алгоритм longjump; выполнение этого алгоритма зависит от причины приостановки процесса, а также от того, требуют ли структуры данных ядра внесения изменений перед выходом из системной функции.
(****) Словами "выше" и "ниже" мы заменяем термины "высокий приоритет" и "низкий приоритет". Однако на практике приоритет может измеряться числами, более низкие значения которых подразумевают более высокий приоритет.
Comments:
Copyright ©
Анализ потоков
Ричи упоминает о том, что им была предпринята попытка создания потоков только с процедурами "вывода" или только с процедурами обслуживания. Однако, процедура обслуживания необходима для управления потоками данных, так как модули должны иногда ставить данные в очередь, если соседние модули на время закрыты для приема данных. Процедура "вывода" так же необходима, поскольку данные должны иногда доставляться в соседние модули незамедлительно. Например, строковому интерфейсу терминала нужно вести эхо-сопровождение ввода данных на терминале в темпе с процессом. Системная функция write могла бы запускать процедуру "вывода" для следующей очереди непосредственно, та, в свою очередь, вызывала бы процедуру "вывода" для следующей очереди и так далее, не нуждаясь в механизме диспетчеризации. Процесс приостановился бы в случае переполнения очередей для вывода. Однако, со стороны ввода модули не могут приостанавливаться, поскольку их выполнение вызывается программой обработки прерываний, иначе был бы приостановлен совершенно безобидный процесс. Связь между модулями не должна быть симметричной в направлениях ввода и вывода, хотя это и делает схему менее изящной.
Также было бы желательно реализовать каждый модуль в виде отдельного процесса, но использование большого количества модулей привело бы к переполнению таблицы процессов. Модули наделяются специальным механизмом диспетчеризации - программным прерыванием, независимым от обычного планировщика процессов. По этой причине модули не могут приостанавливать свое выполнение, так как они приостанавливали бы тем самым произвольный процесс (тот, который прерван). Модули должны хранить внутри себя информацию о своем состоянии, что делает лежащие в их основе программы более громоздкими, чем если бы приостановка выполнения была разрешена.
В реализации потоков можно выделить несколько отклонений или несоответствий:
Учет ресурсов процесса в потоках затрудняется, поскольку модулям необязательно выполняться в контексте процесса, использующего поток. Ошибочно предполагать, что все процессы одинаково используют модули потоков, поскольку одним процессам может потребоваться использование сложных сетевых протоколов, тогда как другие могут использовать простые строковые интерфейсы. Пользователи имеют возможность переводить терминальный драйвер в режим без обработки, в котором функция read возвращает управление через короткий промежуток времени в случае отсутствия данных (например, если newtty.c_cc[VMIN] = 0 на ). Эту особенность сложно реализовать в потоковой среде без подключения специальной программы на уровне заголовка потока. Потоки выступают средствами линейной связи и не могут позволить производить с легкостью мультиплексирование на уровне ядра. В примере использования окон, рассмотренном в предыдущем разделе, выполнялось мультиплексирование на уровне пользовательского процесса.
Несмотря на эти несоответствия, с потоками связываются большие надежды в совершенствовании разработки модулей драйвера.
|
/* предположим, что дескрипторы файлов 0 и 1 уже относятся к физическому терминалу */ для(;;) /* цикл */ { выбрать(ввод); /* ждать ввода из какой-либо линии */ прочитать данные, введенные из линии; переключить(линию с вводимыми данными) { если выбран физический терминал: /* данные вводятся по ли- нии физического терми- нала */ если(считана управляющая команда) /* например, создание нового окна */ { открыть свободный псевдотерминал; пойти по ветви нового процесса: если(процесс родительский) { выдвинуть интерфейс сообщений в сторону mpx; продолжить; /* возврат в цикл "для" */ } /* процесс-потомок */ закрыть ненужные дескрипторы файлов; открыть другой псевдотерминал из пары, выбрать stdin, stdout, stderr; выдвинуть строковый интерфейс терминала; запустить shell; /* подобно виртуальному терминалу */ } /* "обычные" данные, появившиеся через виртуальный терминал */ демультиплексировать считывание данных с физического тер- минала, снять заголовки и вести запись на соответствую- щий псевдотерминал; продолжить; /* возврат в цикл "для" */ если выбран логический терминал: /* виртуальный терминал связан с окном */ закодировать заголовок, указывающий назначение информации окна; переписать заголовок и информацию на физический терминал; продолжить; /* возврат в цикл "для" */ } } |
Comments:
Copyright ©
АРХИТЕКТУРА ОПЕРАЦИОННОЙ СИСТЕМЫ UNIХ
Как уже ранее было замечено (см. [Christian 83], стр.239), в системе UNIX создается иллюзия того, что файловая система имеет "места" и что у процессов есть "жизнь". Обе сущности, файлы и процессы, являются центральными понятиями модели операционной системы UNIX. На Рисунке 2.1 представлена блок-схема ядра системы, отражающая состав модулей, из которых состоит ядро, и их взаимосвязи друг с другом. В частности, на ней слева изображена файловая подсистема, а справа подсистема управления процессами, две главные компоненты ядра. Эта схема дает логическое представление о ядре, хотя в действительности в структуре ядра имеются отклонения от модели, поскольку отдельные модули испытывают внутреннее воздействие со стороны других модулей.
Схема на Рисунке 2.1 имеет три уровня: уровень пользователя, уровень ядра и уровень аппаратуры. Обращения к операционной системе и библиотеки составляют границу между пользовательскими программами и ядром, проведенную на Рисунке 1.1. Обращения к операционной системе выглядят так же, как обычные вызовы функций в программах на языке Си, и библиотеки устанавливают соответствие между этими вызовами функций и элементарными системными операциями, о чем более подробно см. в главе 6. При этом программы на ассемблере могут обращаться к операционной системе непосредственно, без использования библиотеки системных вызовов. Программы часто обращаются к другим библиотекам, таким как библиотека стандартных подпрограмм ввода-вывода, достигая тем самым более полного использования системных услуг. Для этого во время компиляции библиотеки связываются с программами и частично включаются в программу пользователя. Далее мы проиллюстрируем эти моменты на примере.
На рисунке совокупность обращений к операционной системе разделена на те обращения, которые взаимодействуют с подсистемой управления файлами, и те, которые взаимодействуют с подсистемой управления процессами. Файловая подсистема управляет файлами, размещает записи файлов, управляет свободным пространством, доступом к файлам и поиском данных для пользователей. Процессы взаимодействуют с подсистемой управления файлами, используя при этом совокупность специальных обращений к операционной системе, таких как open (для того, чтобы открыть файл на чтение или запись),close, read, write, stat (запросить атрибуты файла), chown (изменить запись с информацией о владельце файла) и chmod (изменить права доступа к файлу). Эти и другие операции рассматриваются в главе 5.
Подсистема управления файлами обращается к данным, которые хранятся в файле, используя буферный механизм, управляющий потоком данных между ядром и устройствами внешней памяти. Буферный механизм, взаимодействуя с драйверами устройств ввода-вывода блоками, инициирует передачу данных к ядру и обратно. Драйверы устройств являются такими модулями в составе ядра, которые управляют работой периферийных устройств. Устройства ввода-вывода блоками относятся программы пользователя ^ | +----------------------+ точка пере- | | библиотеки | сечения ---------|------- +----------------------+ - | - ^ Уровень пользователя - | - | --------------------------|---------------------|----------------- Уровень ядра v v +---------------------------------------------------+ | ^ обращения к операционной системе ^ | +------+------------------------------------+-------+ | | +-----------------+---------------+ +----------------+---------+ | v | | v | | | | | | подсистема управле- | | ............| | ния файлами | | . взаимо- .| | <---+-+ | . действие .| | | | | . процессов.| | ^ ^ | | | подсистема ............| | | | | | | ............| +-------+--------------+----------+ | | . планиров-.| | v +-+> управления . щик .| | +--------------+ | ............| | | буфер сверх- | | ............| | | оперативной | | процессами . распреде-.| | | памяти (кеш) | | . ление .| | +--------------+ | . памяти .| | ^ | ^ ............| | | | | | | v +-------+------------------+ +-------+----------------------+ | | v . | | | символ . блок | | | . | | +------------------------------+ | | | | | драйверы устройств | | | ^ | | +--------------+---------------+ | | | +--------------+------------------------------+------------------+ | v аппаратный контроль v | +----------------------------------------------------------------+ Уровень ядра ------------------------------------------------------------------ Уровень аппаратуры +----------------------------------------------------------------+ | технические средства (аппаратура) | +----------------------------------------------------------------+ Рисунок 2.1. Блок-схема ядра операционной системы
к типу запоминающих устройств с произвольной выборкой; их драйверы построены таким образом, что все остальные компоненты системы воспринимают эти устройства как запоминающие устройства с произвольной выборкой. Например, драйвер запоминающего устройства на магнитной ленте позволяет ядру системы воспринимать это устройство как запоминающее устройство с произвольной выборкой. Подсистема управления файлами также непосредственно взаимодействует с драйверами устройств "неструктурированного" ввода-вывода, без вмешательства буферного механизма. К устройствам неструктурированного ввода-вывода, иногда именуемым устройствами посимвольного ввода-вывода (текстовыми), относятся устройства, отличные от устройств ввода-вывода блоками.
Подсистема управления процессами отвечает за синхронизацию процессов, взаимодействие процессов, распределение памяти и планирование выполнения процессов. Подсистема управления файлами и подсистема управления процессами взаимодействуют между собой, когда файл загружается в память на выполнение (см. главу 7): подсистема управления процессами читает в память исполняемые файлы перед тем, как их выполнить.
Примерами обращений к операционной системе, используемых при управлении процессами, могут служить fork (создание нового процесса), exec (наложение образа программы на выполняемый процесс), exit (завершение выполнения процесса), wait (синхронизация продолжения выполнения основного процесса с моментом выхода из порожденного процесса), brk (управление размером памяти, выделенной процессу) и signal (управление реакцией процесса на возникновение экстраординарных событий). Глава 7 посвящена рассмотрению этих и других системных вызовов.
Модуль распределения памяти контролирует выделение памяти процессам. Если в какой-то момент система испытывает недостаток в физической памяти для запуска всех процессов, ядро пересылает процессы между основной и внешней памятью с тем, чтобы все процессы имели возможность выполняться. В главе 9 описываются два способа управления распределением памяти: выгрузка (подкачка) и замещение страниц. Программу подкачки иногда называют планировщиком, т.к. она "планирует" выделение памяти процессам и оказывает влияние на работу планировщика центрального процессора. Однако в дальнейшем мы будем стараться ссылаться на нее как на "программу подкачки", чтобы избежать путаницы с планировщиком центрального процессора.
Модуль "планировщик" распределяет между процессами время центрального процессора. Он планирует очередность выполнения процессов до тех пор, пока они добровольно не освободят центральный процессор, дождавшись выделения какого-либо ресурса, или до тех пор, пока ядро системы не выгрузит их после того, как их время выполнения превысит заранее определенный квант времени. Планировщик выбирает на выполнение готовый к запуску процесс с наивысшим приоритетом; выполнение предыдущего процесса (приостановленного) будет продолжено тогда, когда его приоритет будет наивысшим среди приоритетов всех готовых к запуску процессов. Существует несколько форм взаимодействия процессов между собой, от асинхронного обмена сигналами о событиях до синхронного обмена сообщениями.
Наконец, аппаратный контроль отвечает за обработку прерываний и за связь с машиной. Такие устройства, как диски и терминалы, могут прерывать работу центрального процессора во время выполнения процесса. При этом ядро системы после обработки прерывания может возобновить выполнение прерванного процесса. Прерывания обрабатываются не самими процессами, а специальными функциями ядра системы, перечисленными в контексте выполняемого процесса.
Comments:
Copyright ©
БИБЛИОГРАФИЯ
[Babaoglu 81] Babaoglu, O., and W.Joy, "Converting a Swap-Based System to do Paging in an Architecture Lacking Page-Referenced Bits", Proceedings of the 8th Symposium on Operating Systems Principles, ACM Operating Systems Review, Vol. 15(5), Dec. 1981, pp. 78-86. [Bach 84] Bach, M.J., and S.J.Buroff, "Multiprocessor UNIX Systems", AT&T Bell Laboratories Technical Journal, Oct. 1984, Vol. 63, No. 8, Part 2, pp. 1733-1750. [Barak 80] Barak, A.B. and Aapir, "UNIX with Satellite Processors", Software - Practice and Experience, Vol. 10, 1980, pp. 383-392. [Beck 85] Beck, B. and B.Kasten, "VLSI Assist in Building a Multiprocessor UNIX System", Proceedings of the USENIX Association Summer Conference, June 1985, pp. 255-275. [Berkeley 83] UNIX Programmer's Manual, 4.2 Berkeley Software Distribution, Virtual VAX-11 Version, Computer Science Division, Department of Electrical Engineering and Computer Science, University of California at Berkeley, August 1983. [Birrell 84] Birrell, A.D. and B.J.Nelson, "Implementing Remote Procedure Calls", ACM Transactions on Computer Systems, Vol. 2, No. 1, Feb. 1984, pp. 39-59. [Bodenstab 84] Bodenstab, D.E., T.F.Houghton, K.A.Kelleman, G.Ronkin, and E.P.Schan, "UNIX Operating System Porting Experiences", AT&T Bell Laboratories Technical Journal, Vol. 63, No. 8, Oct. 1984, pp. 1769-1790. [Bourne 78] Bourne, S.R., "The UNIX Shell", The Bell System Technical Journal, July-August 1978, Vol. 57, No. 6, Part 2, pp. 1971-1990. [Bourne 83] Bourne, S.R., The UNIX System, Addison-Wesley, Reading, MA, 1983. [Brownbridge 82] Brownbridge, D.R., L.F.Marshall, and B.Randell, "The Newcastle Connection or UNIXes of the World Unite!" in Software Practice and Experience, Vol. 12, 1982, pp. 1147-1162. [Bunt 76] Bunt, R.B., "Scheduling Techniques for Operating Systems", Computer, Oct. 1976, pp. 10-17. [Christian 83] Christian, K., The UNIX Operating System, John Wiley & Sons Inc., New York, NY, 1983. [Coffman 73] Coffman, E.G., and P.J.Denning, Operating Systems Theory, Prentice-Hall Inc., Englewood Cliffs, NJ, 1973. [Cole 85] Cole, C.T., P.B.Flinn, and A.B.Atlas, "An Implementation of an Extended File System for UNIX", Proceedings of the USENIX Conference, Summer 1985, pp. 131-149. [Denning 68] Denning, P.J., "The Working Set Model for Program Behavior, Communications of the ACM, Volume 11, No. 5, May 1968, pp. 323-333. [Dijkstra 65] Dijkstra, E.W., "Solution of a Problem in Concurrent Program Control", CACM, Vol. 8, No. 9, Sept. 1965, p. 569. [Dijkstra 68] Dijkstra, E.W., "Cooperating Sequential Processes", in Programming Languages, ed. F.Genuys, Academic Press, New York, NY, 1968. [Felton 84] Felton, W.A., G.L.Miller, and J.M.Milner, "A UNIX Implementation for System/370", AT&T Bell Laboratories Technical Journal, Vol. 63, No. 8, Oct. 1984, pp. 1751- 1767. [Goble 81] Goble, G.H. and M.H.Marsh, "A Dual Processor VAX 11/780", Purdue University Technical Report, TR-EE 81-31, Sept. 1981. [Henry 84] Henry, G.J., "The Fair Share Scheduler", AT&T Bell Laboratories Technical Journal, Oct. 1984, Vol. 63, No. 8, Part 2, pp. 1845-1858. [Holley 79] Holley, L.H., R.P421rmelee, C.A.Salisbury, and D. N.Saul, "VM/370 Asymmetric Multiprocessing", IBM Systems Journal, Vol. 18, No. 1, 1979, pp. 47-70. [Holt 83] Holt, R.C., Concurrent Euclid, the UNIX System, and Tunis, Addison-Wesley, Reading, MA, 1983. [Horning 73] Horning, J.J., and B.Randell, "Process Structuring", Computing Surveys, Vol. 5, No. 1, March 1973, pp. 5-30. [Hunter 84] Hunter, C.B. and E.Farquhar, "Introduction to the NSI16000 Architecture", IEEE Micro, April 1984, pp. 26- 47. [Johnson 78] Johnson, S.C. and D.M.Ritchie, "Portability of C Programs and the UNIX System", The Bell System Technical Journal, Vol. 57, No. 6, Part 2, July-August, 1978, pp. 2021-2048. [Kavaler 83] Kavaler, P. and A.Greenspan, "Extending UNIX to Local-Area Networks", Mini-Micro Systems, Sept. 1983, pp. 197-202. [Kernighan 78] Kernighan, B.W., and D.M.Ritchie, The C Programming Language, Prentice-Hall, Englewood Cliffs, NJ, 1978. [Kernighan 84] Kernighan, B.W., and R.Pike, The UNIX Programming Environment, Prentice-Hall, Englewood Cliffs, NJ, 1984. [Killian 84] Killian, T.J., "Processes as Files", Proceedings of the USENIX Conference, Summer 1984, pp. 203-207. [Levy 80] Levy, H.M., and R.H.Eckhouse, Computer Programming and Architecture: The VAX-11, Digital Press, Bedford, MA, 1980. [levy 82] Levy, H.M., and P.H.Lipman, "Virtual Memory Management in the VAX/VMS Operating System", Computer, Vol. 15, No. 3, March 1982, pp. 35-41. [Lu 83] Lu, P.M., W.A.Dietrich, et. al., "Architecture of a VLSI MAP for BELLMAC-32 Microprocessor", Proc. of IEEE Spring Compcon, Feb. 28, 1983, pp. 213-217. [Luderer 81] Luderer, G.W.R., H.Che, J.P.Haggerty, P.A.Kirslis, and W.T.Marshall, "A Distributed UNIX System Based on a Virtual Circuit Switch", Proceedings of the Eighth Symposium on Operating Systems Principles, Asilomar, California, December 14-16, 1981. [Lycklama 78a] Lycklama, H. and D.L.Bayer, "The MERT Operating System", The Bell System Technical Journal, Vol. 57, No. 6, Part 2, July-August 1978, pp. 2049-2086. [Lycklama 78b] Lycklama, H. and C.Christensen, "A Minicomputer Satellite Processor System", The Bell System Technical Journal, Vol. 57, No. 6, Part 2, July- August 1978, pp. 2103-2114. [McKusick 84] McKusick, M.K., W.N.Joy, S.J.Leffler, and R.S. Fabry, "A Fast File System for UNIX", ACM Transactions on Computer Systems, Vol. 2(3), August 1984, pp. 181-197. [Mullender 84] Mullender, S.J. and A.S.Tanenbaum, "Immediate Files", Software - Practice and Experience, Vol. 14(4), April 1984, pp. 365-368. [Nowitz 80] Nowitz, D.A. and M.E.Lesk, "Implementation of a Dial-Up Network of UNIX Systems", IEEE Proceedings of Fall 1980 COMPCON, Washington, D.C., pp. 483-486. [Organick 72] Organick, E.J., The Multics System: An Examination of Its Structure", The MIT Press, Cambridge, MA, 1972. [Peachey 84] Peachey, D.R., R.B.Bunt, C.L.Williamson, and T.B.Brecht, "An Experimental Investigation of Scheduling Strategies for UNIX", Performance Evaluation Review, 1984 SIGMETRICS Conference on Measurement and Evaluation of Computer Systems, Vol. 12(3), August 1984, pp. 158-166. [Peterson 83] Peterson, James L. and A.Silberschatz, Operating System Concepts, Addison-Wesley, Reading, MA, 1983. [Pike 84] Pike, R., "The Blit: A Multiplexed Graphics Terminal", AT&T Bell Laboratories Technical Journal, Oct. 1984, Vol. 63, No. 8, Part 2, pp. 1607-1632. [Pike 85] Pike, R., and P.Weinberger, "The Hideous Name", Proceedings of the USENIX Conference, Summer 1985, pp. 563-568. [Postel 80] Postel, J. (ed.), "DOD Standart Transmission Control Protocol", ACM Computer Communication Review, Vol. 10, No. 4, Oct. 1980, pp. 52-132. [Postel 81] Postel, J., C.A.Sunshine, and D.Cohen, "The ARPA Internet Protocol", Computer Networks, Vol. 5, No. 4, July 1981, pp. 261-271. [Raleigh 76] Raleigh, T.M., "Introduction to Scheduling and Switching under UNIX", Proceedings of the Digital Equipment Computer Users Society, Atlanta, Ga., May 1976, pp. 867-877. [Richards 69] Richards, M., "BCPL: A Tool for Compiler Writing and Systems Programming", Proc. AFIPS SJCC 34, 1969, pp. 557-566. [Ritchie 78a] Ritchie, D.M. and K.Thompson, "The UNIX Time-Sharing System", The Bell System Technical Journal, July-August 1978, Vol. 57, No. 6, Part 2, pp. 1905-1930. [Ritchie 78b] Ritchie, D.M., "A Retrospective", The Bell System Technical Journal, July-August 1978, Vol. 57, No. 6, Part 2, pp. 1947-1970. [Ritchie 81] Ritchie, D.M. and K.Thompson, "Some Further Aspects of the UNIX Time-Sharing System", Mini-Micro Software, Vol. 6, No. 3, 1981, pp. 9-12. [Ritchie 84a] Ritchie, D.M., "The Evolution of the UNIX Time- sharing System", AT&T Bell Laboratories Technical Journal, Oct. 1984, Vol. 63, No. 8, Part 2, pp. 1577-1594. [Ritchie 84b] Ritchie, D.M., "A Stream Input Output System", AT&T Bell Laboratories Technical Journal, Oct. 1984, Vol. 63, No. 8, Part 2, pp. 1897-1910. [Rochkind 85] Rochkind, M.J., Advanced UNIX Programming, Prentice-Hall, 1985. [Saltzer 66] Saltzer, J.H., Traffic Control in a Multiplexed Computer System, Ph.D. Thesis, MIT, 1966. [Sandberg 85] Sandberg, R., D.Goldberg, S.Kleiman, D.Walsh, and B.Lyon, "Design and Implementation of the Sun Network Filesystem", Proceedings of the USENIX Conference, Summer 1985, pp. 119-131. [SVID 85] System V Interface Definition, Spring 1985, Issue 1, AT&T Customer Information Center, Indianapolis, IN. [System V 84a] UNIX System V User Reference Manual. [System V 84b] UNIX System V Administrator's Manual. [Thompson 74] Thompson, K. and D.M.Ritchie, "The UNIX Time-Sharing System", Communications of the ACM, Vol. 17, No. 7, July, 1974, pp. 365-375 (исправлено и перепечатано в [Ritchie 78a]). [Thompson 78] Thompson, K., "UNIX Implementation", The Bell System Technical Journal, Vol. 57, No. 6, Part 2, July- August, 1978, pp. 1931-1946. [Weinberger 84] Weinberger, P.J., "Cheap Dynamic Instruction Counting", The AT&T Bell Laboratories Technical Journal, Vol. 63, No. 6, Part 2, October 1984, pp. 1815-1826.
Comments:
Copyright ©
Блокировка области и снятие блокировки
Операции блокировки и снятия блокировки для области выполняются независимо от операций выделения и освобождения области, подобно тому, как операции блокирования-разблокирования индекса в файловой системе выполняются независимо от операций назначения-освобождения индекса (алгоритмы iget и iput). Таким образом, ядро может заблокировать и выделить область, а потом снять блокировку, не освобождая области. Точно также, когда ядру понадобится обратиться к выделенной области, оно сможет заблокировать область, чтобы запретить доступ к ней со стороны других процессов, и позднее снять блокировку.
Более детальное рассмотрение потоков
Пайк описывает реализацию мультиплексных виртуальных терминалов, использующую потоки (см. [Pike 84]). Пользователь видит несколько виртуальных терминалов, каждый из которых занимает отдельное окно на экране физического терминала. Хотя в статье Пайка рассматривается схема для интеллектуальных графических терминалов, она работала бы и для терминалов ввода-вывода тоже; каждое окно занимало бы целый экран и пользователь для переключения виртуальных окон набирал бы последовательность управляющих клавиш.

Рисунок 10.23. Отображение виртуальных окон на экране физического терминала
На показана схема расположения процессов и модулей ядра. Пользователь вызывает процесс mpx, контролирующий работу физического терминала. Mpx читает данные из линии физического терминала и ждет объявления об управляющих событиях, таких как создание нового окна, переключение управления на другое окно, удаление окна и т.п.
Когда mpx получает уведомление о том, что пользователю нужно создать новое окно, он создает процесс, управляющий новым окном, и поддерживает связь с ним через псевдотерминал. Псевдотерминал - это программное устройство, работающее по принципу пары: выходные данные, направляемые к одной составляющей пары, посылаются на вход другой составляющей; входные данные посылаются тому модулю потока, который расположен выше по течению. Для того, чтобы открыть окно (), mpx назначает псевдотерминальную пару и открывает одну из составляющих пары, направляя поток к ней (открытие драйвера служит гарантией того, что псевдотерминальная пара не была выбрана раньше). Mpx ветвится и новый процесс открывает другую составляющую псевдотерминальной пары. Mpx выдвигает модуль управления сообщениями в псевдотерминальный поток, чтобы преобразовывать управляющие сообщения в информационные (об этом в следующем параграфе), а порожденный процесс помещает в псевдотерминальный поток модуль строкового интерфейса перед запуском shell'а. Этот shell теперь выполняется на виртуальном терминале; для пользователя виртуальный терминал неотличим от физического.
| /* предположим, что дескрипторы файлов 0 и 1 уже относятся к физическому терминалу */ для(;;) /* цикл */ { выбрать(ввод); /* ждать ввода из какой-либо линии */ прочитать данные, введенные из линии; переключить(линию с вводимыми данными) { если выбран физический терминал: /* данные вводятся по ли- нии физического терми- нала */ если(считана управляющая команда) /* например, создание нового окна */ { открыть свободный псевдотерминал; пойти по ветви нового процесса: если(процесс родительский) { выдвинуть интерфейс сообщений в сторону mpx; продолжить; /* возврат в цикл "для" */ } /* процесс-потомок */ закрыть ненужные дескрипторы файлов; открыть другой псевдотерминал из пары, выбрать stdin, stdout, stderr; выдвинуть строковый интерфейс терминала; запустить shell; /* подобно виртуальному терминалу */ } /* "обычные" данные, появившиеся через виртуальный терминал */ демультиплексировать считывание данных с физического тер- минала, снять заголовки и вести запись на соответствую- щий псевдотерминал; продолжить; /* возврат в цикл "для" */
если выбран логический терминал: /* виртуальный терминал связан с окном */ закодировать заголовок, указывающий назначение информации окна; переписать заголовок и информацию на физический терминал; продолжить; /* возврат в цикл "для" */ } } |
Рисунок 10.24. Псевдопрограмма мультиплексирования окон
Процесс mpx является мультиплексором, направляющим вывод данных с виртуальных терминалов на физический терминал и демультиплексирующим ввод данных с физического терминала на подходящий виртуальный. Mpx ждет поступления данных по любой из линий, используя системную функцию select. Когда данные поступают от физического терминала, mpx решает вопрос, являются ли поступившие данные управляющим сообщением, извещающим о необходимости создания нового окна или удаления старого, или же это информационное сообщение, которое необходимо разослать процессам, считывающим информацию с виртуального терминала. В последнем случае данные имеют заголовок, идентифицирующий тот виртуальный терминал, к которому они относятся; mpx стирает заголовок с сообщения и переписывает данные в соответствующий псевдотерминальный поток. Драйвер псевдотерминала отправляет данные через строковый интерфейс терминала процессам, осуществляющим чтение. Обратная процедура имеет место, когда процесс ведет запись на виртуальный терминал; mpx присоединяет заголовок к данным, информируя физический терминал, для вывода в какое из окон предназначены эти данные.
Если процесс вызывает функцию ioctl с виртуального терминала, строковый интерфейс терминала задает необходимые установки терминала для его виртуальной линии; для каждого из виртуальных терминалов установки могут быть различными. Однако, на физический терминал должна быть послана и кое-какая информация, зависящая от типа устройства. Модуль управления сообщениями преобразует управляющие сообщения, генерируемые функцией ioctl, в информационные сообщения, предназначенные для чтения и записи их процессом mpx, и эти сообщения передаются на физическое устройство.
Целостность файловой системы
Ядро посылает свои записи на диск для того, чтобы свести к минимуму опасность искажения файловой системы в случае системного сбоя. Например, когда ядро удаляет имя файла из родительского каталога, оно синхронно переписывает каталог на диск - перед тем, как уничтожить содержимое файла и освободить его индекс. Если система дала сбой до того, как произошло удаление содержимого файла, ущерб файловой системе будет нанесен минимальный: один из индексов будет иметь число связей, на 1 превышающее число записей в каталоге, которые ссылаются на этот индекс, но все остальные имена путей поиска файла останутся допустимыми. Если запись на диск не была сделана синхронно, точка входа в каталог на диске после системного сбоя может указывать на свободный (или переназначенный) индекс. Таким образом, число записей в каталоге на диске, которые ссылаются на индекс, превысило бы значение счетчика ссылок в индексе. В частности, если имя файла было именем последней связи файла, это имя указывало бы на не назначенный индекс. Не вызывает сомнения, что в первом случае ущерб, наносимый системе, менее серьезен и легко устраним ().
Предположим, например, что у файла есть две связи с именами "a" и "b", одна из которых - "a" - разрывается процессом с помощью функции unlink. Если ядро записывает на диске результаты всех своих действий, то оно, очищая точку входа в каталог для файла "a", делает то же самое на диске. Если система дала сбой после завершения записи результатов на диск, число связей у файла "b" будет равно 2, но файл "a" уже не будет существовать, поскольку прежняя запись о нем была очищена перед сбоем системы. Файл "b", таким образом, будет иметь лишнюю связь, но после перезагрузки число связей переустановится и система будет работать надлежащим образом.
Теперь предположим, что ядро записывало на диск результаты своих действий в обратном порядке и система дала сбой: то есть, ядро уменьшило значение счетчика связей для файла "b", сделав его равным 1, записало индекс на диск и дало сбой перед тем, как очистить в каталоге точку входа для файла "a". После перезагрузки системы записи о файлах "a" и "b" в соответствующих каталогах будут существовать, но счетчик связей у того файла, на который они указывают, будет иметь значение 1. Если затем процесс запустит функцию unlink для файла "a", значение счетчика связей станет равным 0, несмотря на то, что файл "b" ссылается на тот же индекс. Если позднее ядро переназначит индекс в результате выполнения функции creat, счетчик связей для нового файла будет иметь значение, равное 1, но на файл будут ссылаться два имени пути поиска. Система не может выправить ситуацию, не прибегая к помощи программ сопровождения (fsck, описанной в ), обращающихся к файловой системе через блочный или строковый интерфейс.
Для того, чтобы свести к минимуму опасность искажения файловой системы в случае системного сбоя, ядро освобождает индексы и дисковые блоки также в особом порядке. При удалении содержимого файла и очистке его индекса можно сначала освободить блоки, содержащие данные файла, а можно освободить индекс и заново переписать его. Результат в обоих случаях, как правило, одинаковый, однако, если где-то в середине произойдет системный сбой, они будут различаться. Предположим, что ядро сначала освободило дисковые блоки, принадлежавшие файлу, и дало сбой. После перезагрузки системы индекс все еще содержит ссылки на дисковые блоки, занимаемые файлом прежде и ныне не хранящие относящуюся к файлу информацию. Ядру файл показался бы вполне удовлетворительным, но пользователь при обращении к файлу заметит искажение данных. Эти дисковые блоки к тому же могут быть переназначены другим файлам. Чтобы очистить файловую систему программой fsck, потребовались бы большие усилия. Однако, если система сначала переписала индекс на диск, а потом дала сбой, пользователь не заметит каких-либо искажений в файловой системе после перезагрузки. Информационные блоки, ранее принадлежавшие файлу, станут недоступны для системы, но каких-нибудь явных изменений при этом пользователи не увидят. Программе fsck так же было бы проще забрать назад освободившиеся после удаления связи дисковые блоки, нежели производить очистку, необходимую в первом из рассматриваемых случаев.
ЧТЕНИЕ И ЗАПИСЬ ДИСКОВЫХ БЛОКОВ
Теперь, когда алгоритм выделения буферов нами уже рассмотрен, будет легче понять процедуру чтения и записи дисковых блоков. Чтобы считать дисковый блок (Рисунок ), процесс использует алгоритм getblk для поиска блока в буферном кеше. Если он там, ядро может возвратить его немедленно без физического считывания блока с диска. Если блок в кеше отсутствует, ядро приказывает дисководу "запланировать" запрос на чтение и приостанавливает работу, ожидая завершения ввода-вывода. Дисковод извещает контроллер диска о том, что он собирается считать информацию, и контроллер тогда передает информацию в буфер. Наконец, дисковый контроллер прерывает работу процессора, сообщая о завершении операции ввода-вывода, и программа обработки прерываний от диска возобновляет выполнение приостановленного процесса; теперь содержимое дискового блока находится в буфере. Модули, запросившие информацию данного блока, получают ее; когда буфер им уже не потребуется, они освободят его для того, чтобы другие процессы получили к нему доступ.
Рисунок 3.12. Состязание за свободный буфер
будет показано, как модули более высокого уровня (такие как подсистема управления файлами) могут предчувствовать потребность во втором дисковом блоке, когда процесс читает информацию из файла последовательно. Эти модули формируют запрос на асинхронное выполнение второй операции ввода-вывода, надеясь на то, что информация уже будет в памяти, когда вдруг возникнет необходимость в ней, и тем самым повышая быстродействие системы. Для этого ядро выполняет алгоритм чтения блока с продвижением breada (Рисунок ). Ядро проверяет, находится ли в кеше первый блок, и если его там нет, приказывает дисководу считать этот блок. Если в буферном кеше отсутствует и второй блок, ядро дает команду дисководу считать асинхронно и его. Затем процесс приостанавливается, ожидая завершения операции ввода-вывода над первым блоком. Когда выполнение процесса возобновляется, он возвращает буфер первому блоку и не обращает внимание на то, когда завершится операция ввода-вывода для второго блока. После завершения этой операции контроллер диска прерывает работу системы; программа обработки прерываний узнает о том, что ввод-вывод выполнялся асинхронно, и освобождает буфер (алгоритм brelse). Если бы она не освободила буфер, буфер остался бы заблокированным и по этой причине недоступным для всех процессов. Невозможно заранее разблокировать буфер, так как операция ввода-вывода, связанная с буфером, активна и, следовательно, содержимое буфера еще не адекватно. Позже, если процесс пожелает считать второй блок, он обнаружит его в буферном кеше, поскольку к тому времени операция ввода-вывода закончится. Если же, в начале выполнения алгоритма breada, первый блок обнаружился в буферном кеше, ядро тут же проверяет, находится там же и второй блок, и продолжает работу по только что описанной схеме.
| алгоритм bread /* чтение блока */ входная информация: номер блока в файловой системе выходная информация: буфер, содержащий данные { получить буфер для блока (алгоритм getblk); если (данные в буфере правильные) возвратить буфер; приступить к чтению с диска; приостановиться (до завершения операции чтения); возвратить (буфер); } |
i>Рисунок 3.13. Алгоритм чтения дискового блока
Алгоритм записи содержимого буфера в дисковый блок (Рисунок ) похож на алгоритм чтения. Ядро информирует дисковод о том, что есть буфер, содержимое которого должно быть выведено, и дисковод планирует операцию ввода-вывода блока. Если запись производится синхронно, вызывающий процесс приостанавливается, ожидая ее завершения и освобождая буфер в момент возобновления своего выполнения. Если запись производится асинхронно, ядро запускает операцию записи на диск, но не ждет ее завершения. Ядро освободит буфер, когда завершится ввод-вывод.
| алгоритм breada /* чтение блока с продвижением */ входная информация: (1) в файловой системе номер блока для немедленного считывания (2) в файловой системе номер блока для асинхронного считывания выходная информация: буфер с данными, считанными немедленно { если (первый блок отсутствует в кеше) { получить буфер для первого блока (алгоритм getblk); если (данные в буфере неверные) приступить к чтению с диска; } если (второй блок отсутствует в кеше) { получить буфер для второго блока (алгоритм getblk); если (данные в буфере верные) освободить буфер (алгоритм brelse); в противном случае приступить к чтению с диска; } если (первый блок первоначально находился в кеше) { считать первый блок (алгоритм bread); возвратить буфер; } приостановиться (до того момента, когда первый буфер будет содержать верные данные); возвратить буфер; } |
Могут возникнуть ситуации, и это будет показано в следующих двух главах, когда ядро не записывает данные немедленно на диск. Если запись "откладывается", ядро соответствующим образом помечает буфер, освобождая его по алгоритму brelse, и продолжает работу без планирования ввода-вывода. Ядро записывает блок на диск перед тем, как другой процесс сможет переназначить буфер другому блоку, как показано в алгоритме getblk (случай 3). Между тем, ядро надеется на то, что процесс получает доступ до того, как буфер будет переписан на диск; если этот процесс впоследствии изменит содержимое буфера, ядро произведет дополнительную операцию по сохранению изменений на диске.
| алгоритм bwrite /* запись блока */ входная информация: буфер выходная информация: отсутствует { приступить к записи на диск; если (ввод-вывод синхронный) { приостановиться (до завершения ввода-вывода); освободить буфер (алгоритм brelse); } в противном случае если (буфер помечен для отложенной записи) пометить буфер для последующего размещения в "голове" списка свободных буферов; } |
i>Рисунок 3.15. Алгоритм записи дискового блока
Отложенная запись отличается от асинхронной записи. Выполняя асинхронную запись, ядро запускает дисковую операцию немедленно, но не дожидается ее завершения. Что касается отложенной записи, ядро отдаляет момент физической переписи на диск насколько возможно; затем по алгоритму getblk (случай 3) оно помечает буфер как "старый" и записывает блок на диск асинхронно. После этого контроллер диска прерывает работу системы и освобождает буфер, используя алгоритм brelse; буфер помещается в "голову" списка свободных буферов, поскольку он имеет пометку "старый". Благодаря наличию двух выполняющихся асинхронно операций ввода-вывода - чтения блока с продвижением и отложенной записи - ядро может запускать программу brelse из программы обработки прерываний. Следовательно, ядро вынуждено препятствовать возникновению прерываний при выполнении любой процедуры, работающей со списком свободных буферов, поскольку brelse помещает буферы в этот список.
Comments:
Copyright ©
Чтение из каналов и запись в каналы
Канал следует рассматривать под таким углом зрения, что процессы ведут запись на одном конце канала, а считывают данные на другом конце. Как уже говорилось выше, процессы обращаются к данным в канале в порядке их поступления в канал; это означает, что очередность, в которой данные записываются в канал, совпадает с очередностью их выборки из канала. Совпадение количества процессов, считывающих данные из канала, с количеством процессов, ведущих запись в канал, совсем не обязательно; если одно число отличается от другого более, чем на 1, процессы должны координировать свои действия по использованию канала с помощью других механизмов. Ядро обращается к данным в канале точно так же, как и к данным в обычном файле: оно сохраняет данные на устройстве канала и назначает каналу столько блоков, сколько нужно, во время выполнения функции write. Различие в выделении памяти для канала и для обычного файла состоит в том, что канал использует в индексе только блоки прямой адресации в целях повышения эффективности работы, хотя это и накладывает определенные ограничения на объем данных, одновременно помещающихся в канале. Ядро работает с блоками прямой адресации индекса как с циклической очередью, поддерживая в своей структуре указатели чтения и записи для обеспечения очередности обслуживания "первым пришел - первым вышел" ().
Рассмотрим четыре примера ввода-вывода в канал: запись в канал, в котором есть место для записи данных; чтение из канала, в котором достаточно данных для удовлетворения запроса на чтение; чтение из канала, в котором данных недостаточно; и запись в канал, где нет места для записи.
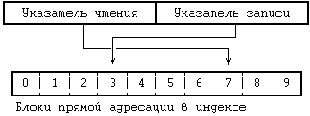
Рисунок 5.17. Логическая схема чтения и записи в канал
Рассмотрим первый случай, в котором процесс ведет запись в канал, имеющий место для ввода данных: сумма количества записываемых байт с числом байт, уже находящихся в канале, меньше или равна емкости канала. Ядро следует алгоритму записи данных в обычный файл, за исключением того, что оно увеличивает размер канала автоматически после каждого выполнения функции write, поскольку по определению объем данных в канале растет с каждой операцией записи. Иначе происходит увеличение размера обычного файла: процесс увеличивает размер файла только тогда, когда он при записи данных переступает границу конца файла. Если следующее смещение в канале требует использования блока косвенной адресации, ядро устанавливает значение смещения в пространстве процесса таким образом, чтобы оно указывало на начало канала (смещение в байтах, равное 0). Ядро никогда не затирает данные в канале; оно может сбросить значение смещения в 0, поскольку оно уже установило, что данные не будут переполнять емкость канала. Когда процесс запишет в канал все свои данные, ядро откорректирует значение указателя записи (в индексе) канала таким образом, что следующий процесс продолжит запись в канал с того места, где остановилась предыдущая операция write. Затем ядро возобновит выполнение всех других процессов, приостановленных в ожидании считывания данных из канала.
Когда процесс запускает функцию чтения из канала, он проверяет, пустой ли канал или нет. Если в канале есть данные, ядро считывает их из канала так, как если бы канал был обычным файлом, выполняя соответствующий алгоритм. Однако, начальным смещением будет значение указателя чтения, хранящегося в индексе и показывающего протяженность прочитанных ранее данных. После считывания каждого блока ядро уменьшает размер канала в соответствии с количеством считанных данных и устанавливает значение смещения в пространстве процесса так, чтобы при достижении конца канала оно указывало на его начало. Когда выполнение системной функции read завершается, ядро возобновляет выполнение всех приостановленных процессов записи и запоминает текущее значение указателя чтения в индексе (а не в записи таблицы файлов).
Если процесс пытается считать больше информации, чем фактически есть в канале, функция read завершится успешно, возвратив все данные, находящиеся в данный момент в канале, пусть даже не полностью выполнив запрос пользователя. Если канал пуст, процесс обычно приостанавливается до тех пор, пока какой-нибудь другой процесс не запишет данные в канал, после чего все приостановленные процессы, ожидающие ввода данных, возобновят свое выполнение и начнут конкурировать за чтение из канала. Если, однако, процесс открывает поименованный канал с параметром "no delay" (без задержки), функция read возвратит управление немедленно, если в канале отсутствуют данные. Операции чтения и записи в канал имеют ту же семантику, что и аналогичные операции для терминальных устройств (), она позволяет процессам игнорировать тип тех файлов, с которыми эти программы имеют дело.
Если процесс ведет запись в канал и в канале нет места для всех данных, ядро помечает индекс и приостанавливает выполнение процесса до тех пор, пока канал не начнет очищаться от данных. Когда впоследствии другой процесс будет считывать данные из канала, ядро заметит существование процессов, приостановленных в ожидании очистки канала, и возобновит их выполнение подобно тому, как это было объяснено выше. Исключением из этого утверждения является ситуация, когда процесс записывает в канал данные, объем которых превышает емкость канала (то есть, объем данных, которые могут храниться в блоках прямой адресации); в этом случае ядро записывает в канал столько данных, сколько он может вместить в себя, и приостанавливает процесс до тех пор, пока не освободится дополнительное место. Таким образом, возможно положение, при котором записываемые данные не будут занимать непрерывное место в канале, если другие процессы ведут запись в канал в то время, на которое первый процесс прервал свою работу.
Анализируя реализацию каналов, можно заметить, что интерфейс процессов согласуется с интерфейсом обычных файлов, но его воплощение отличается, так как ядро запоминает смещения для чтения и записи в индексе вместо того, чтобы делать это в таблице файлов. Ядро вынуждено хранить значения смещений для поименованных каналов в индексе для того, чтобы процессы могли совместно использовать эти значения: они не могли бы совместно использовать значения, хранящиеся в таблице файлов, так как процесс получает новую запись в таблице файлов по каждому вызову функции open. Тем не менее, совместное использование смещений чтения и записи в индексе наблюдалось и до реализации поименованных каналов. Процессы, обращающиеся к непоименованным каналам, разделяют доступ к каналу через общие точки входа в таблицу файлов, поэтому они могли бы по умолчанию хранить смещения записи и чтения в таблице файлов, как это принято для обычных файлов. Это не было сделано, так как процедуры низкого уровня, работающие в ядре, больше не имеют доступа к записям в таблице файлов: программа упростилась за счет того, что процессы совместно используют значения смещений, хранящиеся в индексе.
CLOSЕ
Процесс закрывает открытый файл, когда процессу больше не нужно обращаться к нему. Синтаксис вызова системной функции close (закрыть): close(fd);
где fd - дескриптор открытого файла. Ядро выполняет операцию закрытия, используя дескриптор файла и информацию из соответствующих записей в таблице файлов и таблице индексов. Если счетчик ссылок в записи таблицы файлов имеет значение, большее, чем 1, в связи с тем, что были обращения к функциям dup или fork, то это означает, что на запись в таблице файлов делают ссылку другие пользовательские дескрипторы, что мы увидим далее; ядро уменьшает значение счетчика и операция закрытия завершается. Если счетчик ссылок в таблице файлов имеет значение, равное 1, ядро освобождает запись в таблице и индекс в памяти, ранее выделенный системной функцией open (алгоритм iput). Если другие процессы все еще ссылаются на индекс, ядро уменьшает значение счетчика ссылок на индекс, но оставляет индекс процессам; в противном случае индекс освобождается для переназначения, так как его счетчик ссылок содержит 0. Когда выполнение системной функции close завершается, запись в таблице пользовательских дескрипторов файла становится пустой. Попытки процесса использовать данный дескриптор заканчиваются ошибкой до тех пор, пока дескриптор не будет переназначен другому файлу в результате выполнения другой системной функции. Когда процесс завершается, ядро проверяет наличие активных пользовательских дескрипторов файла, принадлежавших процессу, и закрывает каждый из них. Таким образом, ни один процесс не может оставить файл открытым после своего завершения.
| #include <fcntl.h> main(argc,argv) int argc; char *argv[]; { int fd,skval; char c;
if(argc != 2) exit(); fd = open(argv[1],O_RDONLY); if (fd == -1) exit(); while ((skval = read(fd,&c,1)) == 1) { printf("char %c\n",c); skval = lseek(fd,1023L,1); printf("new seek val %d\n",skval); } } | |
Рисунок 5.10. Программа, содержащая вызов системной функции lseek
На , например, показаны записи из таблиц, приведенных на , после того, как второй процесс закрывает соответствующие им файлы. Записи, соответствующие дескрипторам 3 и 4 в таблице пользовательских дескрипторов файлов, пусты. Счетчики в записях таблицы файлов теперь имеют значение 0, а сами записи пусты. Счетчики ссылок на файлы "/etc/passwd" и "private" в индексах также уменьшились. Индекс для файла "private" находится в списке свободных индексов, поскольку счетчик ссылок на него равен 0, но запись о нем не пуста. Если еще какой-нибудь процесс обратится к файлу "private", пока индекс еще находится в списке свободных индексов, ядро востребует индекс обратно, как показано в .
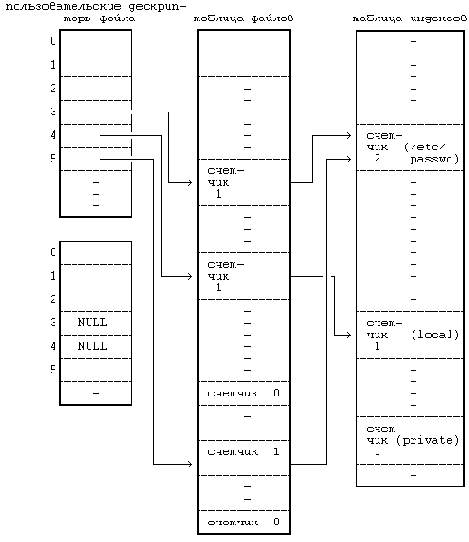
Рисунок 5.11. Таблицы после закрытия файла
Comments:
Copyright ©
Демонтирование файловой системы
Синтаксис вызова системной функции umount: umount(special filename);
где special filename указывает демонтируемую файловую систему. При демонтировании файловой системы () ядро обращается к индексу демонтируемого устройства, восстанавливает номер устройства для специального файла, освобождает индекс (алгоритм iput) и находит в таблице монтирования запись с номером устройства, равным номеру устройства для специального файла. Прежде чем ядро действительно демонтирует файловую систему, оно должно удостовериться в том, что в системе не осталось используемых файлов, для этого ядро просматривает таблицу индексов в поисках всех файлов, чей номер устройства совпадает с номером демонтируемой системы. Активным файлам соответствует положительное значение счетчика ссылок и в их число входят текущий каталог процесса, файлы с разделяемым текстом, которые исполняются в текущий момент (), и открытые когда-то файлы, которые потом не были закрыты. Если какие-нибудь файлы из файловой системы активны, функция umount завершается неудачно: если бы она прошла успешно, активные файлы сделались бы недоступными.
Буферный пул все еще содержит блоки с "отложенной записью", не переписанные на диск, поэтому ядро "вымывает" их из буферного пула. Ядро удаляет записи с разделяемым текстом, которые находятся в таблице областей, но не являются действующими (), записывает на диск все недавно скорректированные суперблоки и корректирует дисковые копии всех индексов, которые требуют этого. Казалось, было бы достаточно откорректировать дисковые блоки, суперблок и индексы только для демонтируемой файловой системы, однако в целях сохранения преемственности изменений ядро выполняет аналогичные действия для всей системы в целом. Затем ядро освобождает корневой индекс монтированной файловой системы, удерживаемый с момента первого обращения к нему во время выполнения функции mount, и запускает из драйвера процедуру закрытия устройства, содержащего файловую систему. Впоследствии ядро просматривает буферы в буферном кеше и делает недействительными те из них, в которых находятся блоки демонтируемой файловой системы; в хранении информации из этих блоков в кеше больше нет необходимости. Делая буферы недействительными, ядро вставляет их в начало списка свободных буферов, в то время как блоки с актуальной информацией остаются в буферном кеше. Ядро сбрасывает в индексе системы, где производилось монтирование, флаг "точки монтирования", установленный функцией mount, и освобождает индекс. Пометив запись в таблице монтирования свободной для общего использования, функция umount завершает работу.
| алгоритм umount входная информация: имя специального файла, соответствую- щего демонтируемой файловой системе выходная информация: отсутствует { если (пользователь не является суперпользователем) возвратить (ошибку); получить индекс специального файла (алгоритм namei); извлечь старший и младший номера демонтируемого устрой- ства; получить в таблице монтирования запись для демонтируе- мой системы, исходя из старшего и младшего номеров; освободить индекс специального файла (алгоритм iput); удалить из таблицы областей записи с разделяемым текс- том для файлов, принадлежащих файловой системе; /* глава 7ххх */ скорректировать суперблок, индексы, выгрузить буферы на диск; если (какие-то файлы из файловой системы все еще ис- пользуются) возвратить (ошибку); получить из таблицы монтирования корневой индекс монти- рованной файловой системы; заблокировать индекс; освободить индекс (алгоритм iput); /* iget был при монтировании */ запустить процедуру закрытия для специального устрой- ства; сделать недействительными (отменить) в пуле буферы из демонтируемой файловой системы; получить из таблицы монтирования индекс точки монтиро- вания; заблокировать индекс; очистить флаг, помечающий индекс как "точку монтирова- ния"; освободить индекс (алгоритм iput); /* iget был при монтировании */ освободить буфер, используемый под суперблок; освободить в таблице монтирования место, занятое ранее; } |
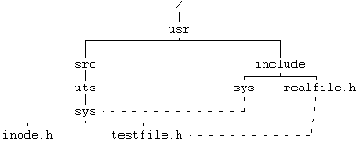
Рисунок 5.28. Файлы в дереве файловой системы, связанные с помощью функции link
Comments:
Copyright ©
ДИСКОВЫЕ ДРАЙВЕРЫ
Так сложилось исторически, что дисковые устройства в системах UNIX разбивались на разделы, содержащие различные файловые системы, что означало "деление [дискового] пакета на несколько управляемых по-своему частей" (см. [System V 84b]). Например, если на диске располагаются четыре файловые системы, администратор может оставить одну из них несмонтированной, одну смонтировать только для чтения, а две других только для записи. Несмотря на то, что все файловые системы сосуществуют на одном физическом устройстве, пользователи не могут ни обращаться к файлам немонтированной файловой системы, используя методы доступа, описанные в главах 4 и 5, ни записывать файлы в файловые системы, смонтированные только для чтения. Более того, так как каждый раздел (и, следовательно, файловая система) занимает на диске смежные дорожки и цилиндры, скопировать всю файловую систему легче, чем в том случае, если бы раздел занимал участки, разбросанные по всему дисковому тому.
Дисковый драйвер транслирует адрес файловой системы, состоящий из логического номера устройства и номера блока, в точный номер дискового сектора. Драйвер получает адрес одним из следующих путей: либо стратегическая процедура использует буфер из буферного пула, заголовок которого содержит номера устройства и блока, либо процедуры чтения и записи передают логический (младший) номер устройства в качестве параметра; они преобразуют адрес смещения в байтах, хранящийся в пространстве задачи, в адрес соответствующего блока. Дисковый драйвер использует номер устройства для идентификации физического устройства и указания используемого раздела, обращаясь при этом к внутренним таблицам для поиска сектора, отмечающего начало раздела на диске. Наконец, он добавляет номер блока в файловой системе к номеру блока, с которого начинается каждый сектор, чтобы идентифицировать сектор, используемый для ввода-вывода.

Рисунок 10.7. Разделы на диске RP07
Исторически сложилось так, что размеры дисковых разделов устанавливаются в зависимости от типа диска. Например, диск DEC RP07 разбит на разделы, характеристика которых приведена на . Предположим, что файлы "/dev/dsk0", "/dev/dsk1", "/dev/dsk2" и "/dev/dsk3" соответствуют разделам диска RP07, имеющим номера от 0 до 3, и имеют аналогичные младшие номера. Пусть размер логического блока в файловой системе совпадает с размером дискового блока. Если ядро пытается обратиться к блоку с номером 940 в файловой системе, хранящейся в "/dev/dsk3", дисковый драйвер переадресует запрос к блоку с номером 336940 (раздел 3 начинается с блока, имеющего номер 336000; 336000 + 940 = 336940) на диске.
Размеры разделов на диске варьируются и администраторы располагают файловые системы в разделах соответствующего размера: большие файловые системы попадают в разделы большего размера и т. д. Разделы на диске могут перекрываться. Например, разделы 0 и 1 на диске RP07 не пересекаются, но вместе они занимают блоки с номерами от 0 до 1008000, то есть весь диск. Раздел 7 так же занимает весь диск. Перекрытие разделов не имеет значения, поскольку файловые системы, хранящиеся в разделах, размещаются таким образом, что между ними нет пересечений. Иметь один раздел, включающий в себя все дисковое пространство, выгодно, поскольку весь том можно быстро скопировать.
Использование разделов фиксированного состава и размера ограничивает гибкость дисковой конфигурации. Информацию о разделах в закодированном виде не следует включать в дисковый драйвер, но нужно поместить в таблицу содержимого дискового тома. Однако, найти общее место на всех дисках для размещения таблицы содержимого дискового тома и сохранить тем самым совместимость с предыдущими версиями системы довольно трудно. В существующих реализациях версии V предполагается, что блок начальной загрузки первой из файловых систем на диске занимает первый сектор тома, хотя по логике это, казалось бы, самое подходящее место для таблицы содержимого тома. И все же дисковый драйвер должен иметь закодированную информацию о месте расположения таблицы содержимого тома для каждого диска, не препятствуя существованию дисковых разделов переменного размера.
В связи с тем, что для системы UNIX является типичным высокий уровень дискового трафика, драйвер диска должен максимизировать передачу данных с тем, чтобы обеспечить наилучшую производительность всей системы. Новейшие дисковые контроллеры осуществляют планирование выполнения заданий, требующих обращения к диску, позиционируют головку диска и обеспечивают передачу данных между диском и центральным процессором; иначе это приходится делать дисковому драйверу.
Сервисные программы могут непосредственно обращаться к диску в обход стандартного метода доступа к файловой системе, рассмотренного в главах и , как пользуясь блочным интерфейсом, так и не прибегая к структурированию данных. Непосредственно работают с диском две важные программы - mkfs и fsck. Программа mkfs форматирует раздел диска для файловой системы UNIX, создавая при этом суперблок, список индексов, список свободных дисковых блоков с указателями и корневой каталог новой файловой системы. Программа fsck проверяет целостность существующей файловой системы и исправляет ошибки, как показано в .
Рассмотрим программу, приведенную на , в применении к файлам "/dev/dsk15" и "/dev/rdsk15", и предположим, что команда ls выдала следующую информацию: ls -1 /dev/dsk15 /dev/rdsk15 br-------- 2 root root 0,21 Feb 12 15:40 /dev/dsk15 crw-rw---- 2 root root 7,21 Mar 7 09:29 /dev/rdsk15
Отсюда видно, что файл "/dev/dsk15" соответствует устройству блочного типа, владельцем которого является пользователь под именем "root", и только пользователь "root" может читать с него непосредственно. Его старший номер 0, младший - 21. Файл "/dev/rdsk15" соответствует устройству посимвольного ввода-вывода, владельцем которого является пользователь "root", однако права доступа к которому на запись и чтение есть как у владельца, так и у группы. Его старший номер - 7, младший - 21. Процесс, открывающий файлы, получает доступ к устройству через таблицу ключей устройств ввода-вывода блоками и таблицу ключей устройств посимвольного ввода-вывода, соответственно, а младший номер устройства 21 информирует драйвер о том, к какому разделу диска производится обращение, например, дисковод 2, раздел 1. Поскольку младшие номера у файлов совпадают, они ссылаются на один и тот же раздел диска, если предположить, что это одно устройство (). Таким образом, процесс, выполняющий программу, открывает один и тот же драйвер дважды (используя различные интерфейсы), позиционирует головку к смещению с адресом 8192 и считывает данные с этого места. Результаты выполнения операций чтения должны быть идентичными при условии, что работает только одна файловая система.
|
#include "fcntl.h" main() { char buf1[4096], buf2[4096] int fd1, fd2, i; if (((fd1 = open("/dev/dsk5/", O_RDONLY)) == -1) ((fd2 = open("/dev/rdsk5", O_RDONLY)) == -1)) { printf("ошибка при открытии\n"); exit(); } lseek(fd1, 8192L, 0); lseek(fd2, 8192L, 0); if ((read(fd1, buf1, sizeof(buf1)) == -1) (read(fd2, buf2, sizeof(buf2)) == -1)) { printf("ошибка при чтении\n"); exit(); } for (i = 0; i < sizeof(buf1); i++) if (buf1[i] != buf2[i]) { printf("различие в смещении %d\n", i); exit(); } printf("данные совпадают\n"); } |
Рисунок 10.8. Чтение данных с диска с использованием блочного интерфейса и без структурирования данных
Программы, осуществляющие чтение и запись на диск непосредственно, представляют опасность, поскольку манипулируют с чувствительной информацией, рискуя нарушить системную защиту. Администраторам следует защищать интерфейсы ввода-вывода путем установки прав доступа к файлам дисковых устройств. Например, дисковые файлы "/dev/dsk15" и "/dev/rdsk15" должны принадлежать пользователю с именем "root", и права доступа к ним должны быть определены таким образом, чтобы пользователю "root" было разрешено чтение, а всем остальным пользователям и чтение, и запись должны быть запрещены.
Программы, осуществляющие чтение и запись на диск непосредственно, могут также нарушить целостность данных в файловой системе. Алгоритмы файловой системы, рассмотренные в главах , и , координируют выполнение операций ввода-вывода, связанных с диском, тем самым поддерживая целостность информационных структур на диске, в том числе списка свободных дисковых блоков и указателей из индексов на информационные блоки прямой и косвенной адресации. Процессы, обращающиеся к диску непосредственно, обходят эти алгоритмы. Пусть даже их программы написаны с большой осторожностью, проблема целостности все равно не исчезнет, если они выполняются параллельно с работой другой файловой системы. По этой причине программа fsck не должна выполняться при наличии активной файловой системы.
Два типа дискового интерфейса различаются между собой по использованию буферного кеша. При работе с блочным интерфейсом ядро пользуется тем же алгоритмом, что и для файлов обычного типа, исключение составляет тот момент, когда после преобразования адреса смещения логического байта в адрес смещения логического блока (см. алгоритм bmap в ) оно трактует адрес смещения логического блока как физический номер блока в файловой системе. Затем, используя буферный кеш, ядро обращается к данным, и, в конечном итоге, к стратегическому интерфейсу драйвера. Однако, при обращении к диску через символьный интерфейс (без структурирования данных), ядро не превращает адрес смещения в адрес файла, а передает его немедленно драйверу, используя для передачи рабочее пространство задачи. Процедуры чтения и записи, входящие в состав драйвера, преобразуют смещение в байтах в смещение в блоках и копируют данные непосредственно в адресное пространство задачи, минуя буферы ядра.
Таким образом, если один процесс записывает на устройство блочного типа, а второй процесс затем считывает с устройства символьного типа по тому же адресу, второй процесс может не считать информацию, записанную первым процессом, так как информация может еще находиться в буферном кеше, а не на диске. Тем не менее, если второй процесс обратится к устройству блочного типа, он автоматически попадет на новые данные, находящиеся в буферном кеше.
При использовании символьного интерфейса можно столкнуться со странной ситуацией. Если процесс читает или пишет на устройство посимвольного ввода-вывода порциями меньшего размера, чем, к примеру, блок, результаты будут зависеть от драйвера. Например, если производить запись на ленту по 1 байту, каждый байт может попасть в любой из ленточных блоков.
Преимущество использования символьного интерфейса состоит в скорости, если не возникает необходимость в кешировании данных для дальнейшей работы. Процессы, обращающиеся к устройствам ввода -вывода блоками, передают информацию блоками, размер каждого из которых ограничивается размером логического блока в данной файловой системе. Например, если размер логического блока в файловой системе 1 Кбайт, за одну операцию ввода-вывода может быть передано не больше 1 Кбайта информации. При этом процессы, обращающиеся к диску с помощью символьного интерфейса, могут передавать за одну дисковую операцию множество дисковых блоков, в зависимости от возможностей дискового контроллера. С функциональной точки зрения, процесс получает тот же самый результат, но символьный интерфейс может работать гораздо быстрее. Если воспользоваться примером, приведенным на , можно увидеть, что когда процесс считывает 4096 байт, используя блочный интерфейс для файловой системы с размером блока 1 Кбайт, ядро производит четыре внутренние итерации, на каждом шаге обращаясь к диску, прежде чем вызванная системная функция возвращает управление, но когда процесс использует символьный интерфейс, драйвер может закончить чтение за одну дисковую операцию. Более того, использование блочного интерфейса вызывает дополнительное копирование данных между адресным пространством задачи и буферами ядра, что отсутствует в символьном интерфейсе.
(***) Не существует иного способа установить, что символьный и блочный драйверы ссылаются на одно и то же устройство, кроме просмотра таблиц системной конфигурации и текста программ драйвера.
Comments:
Copyright ©
Драйвер косвенного терминала
Зачастую процессам необходимо прочитать ил записать данные непосредственно на операторский терминал, хотя стандартный ввод и вывод могут быть переназначены в другие файлы. Например, shell может посылать срочные сообщения непосредственно на терминал, несмотря на то, что его стандартный файл вывода и стандартный файл ошибок, возможно, переназначены в другое место. В версиях системы UNIX поддерживается "косвенный" доступ к терминалу через файл устройства "/dev/tty", в котором для каждого процесса определен управляющий (операторский) терминал. Пользователи, прошедшие регистрацию на отдельных терминалах, могут обращаться к файлу "/dev/tty", но они получат доступ к разным терминалам.
Существует два основных способа поиска ядром операторского терминала по имени файла "/dev/tty". Во-первых, ядро может специально указать номер устройства для файла косвенного терминала с отдельной точкой входа в таблицу ключей устройств посимвольного ввода-вывода. При запуске косвенного терминала драйвер этого терминала получает старший и младший номера операторского терминала из адресного пространства, выделенного процессу, и запускает драйвер реального терминала, используя данные таблицы ключей устройств посимвольного ввода-вывода. Второй способ, обычно используемый для поиска операторского терминала по имени "/dev/tty", связан с проверкой соответствия старшего номера устройства номеру косвенного терминала перед вызовом процедуры open, определяемой типом данного драйвера. В случае совпадения номеров освобождается индекс файла "/dev/tty", выделяется индекс операторскому терминалу, точка входа в таблицу файлов переустанавливается так, чтобы указывать на индекс операторского терминала, и вызывается процедура open, принадлежащая терминальному драйверу. Дескриптор файла, возвращенный после открытия файла "/dev/tty", указывает непосредственно на операторский терминал и его драйвер.
ДРУГИЕ ТИПЫ ФАЙЛОВ
В системе UNIX поддерживаются и два других типа файлов: каналы и специальные файлы. Канал, иногда называемый fifo (сокращенно от "first-in-first-out" - "первым пришел - первым вышел" - поскольку обслуживает запросы в порядке поступления), отличается от обычного файла тем, что содержит временные данные: информация, однажды считанная из канала, не может быть прочитана вновь. Кроме того, информация читается в том порядке, в котором она была записана в канале, и система не допускает никаких отклонений от данного порядка. Способ хранения ядром информации в канале не отличается от способа ее хранения в обычном файле, за исключением того, что здесь используются только блоки прямой, а не косвенной, адресации. Конкретное представление о каналах можно будет получить в следующей главе.
Последним типом файлов в системе UNIX являются специальные файлы, к которым относятся специальные файлы устройств ввода-вывода блоками и специальные файлы устройств посимвольного ввода-вывода. Оба подтипа обозначают устройства, и поэтому индексы таких файлов не связаны ни с какой информацией. Вместо этого индекс содержит два номера - старший и младший номера устройства. Старший номер устройства указывает его тип, например, терминал или диск, а младший номер устройства - числовой код, идентифицирующий устройство в группе однородных устройств. Более подробно специальные файлы устройств рассматриваются .
Comments:
Copyright ©
DUР
Системная функция dup копирует дескриптор файла в первое свободное место в таблице пользовательских дескрипторов файла, возвращая новый дескриптор пользователю. Она действует для всех типов файла. Синтаксис вызова функции: newfd = dup(fd);
где fd - дескриптор файла, копируемый функцией, а newfd - новый дескриптор, ссылающийся на файл. Поскольку функция dup дублирует дескриптор файла, она увеличивает значение счетчика в соответствующей записи таблицы файлов - записи, на которую указывают связанные с ней точки входа в таблице файловых дескрипторов, которых теперь стало на одну больше. Например, обзор структур данных, изображенных на Рисунке 5.20, показывает, что процесс вызывает следующую последовательность функций: он открывает (open) файл с именем "/etc/passwd" (файловый дескриптор 3), затем открывает файл с именем "local" (файловый дескриптор 4), снова файл с именем "/etc/passwd" (файловый дескриптор 5) и, наконец, дублирует (dup) файловый дескриптор 3, возвращая дескриптор 6.
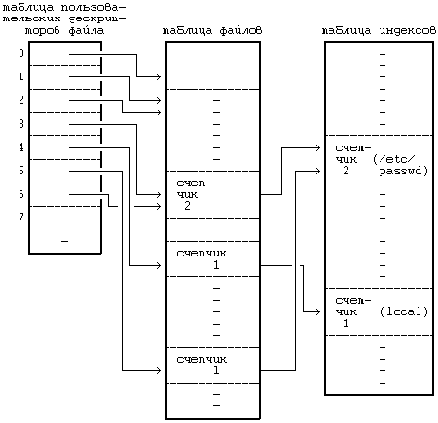
Рисунок 5.20. Структуры данных после выполнения функции dup
Возможно, dup - функция, не отличающаяся изяществом, поскольку она предполагает, что пользователь знает о том, что система возвратит свободную точку входа в таблице пользовательских дескрипторов, имеющую наименьший номер. Однако, она служит важной задаче конструирования сложных программ из более простых конструкционных блоков, что, в частности, имеет место при создании конвейеров, составленных из командных процессоров.
Рассмотрим программу, приведенную на . В переменной i хранится дескриптор файла, возвращаемый в результате открытия файла "/etc/passwd", а в переменной j - дескриптор файла, возвращаемый системой в результате дублирования дескриптора i с помощью функции dup. В адресном пространстве процесса оба пользовательских дескриптора, представленные переменными i и j, ссылаются на одну и ту же запись в таблице файлов и поэтому используют одно и то же значение смещения внутри файла. Таким образом, первые два вызова процессом функции read реализуют последовательное считывание данных, и в буферах buf1 и buf2 будут располагаться разные данные. Совсем другой результат получается, когда процесс открывает один и тот же файл дважды и читает дважды одни и те же данные (). Процесс может освободить с помощью функции close любой из файловых дескрипторов по своему желанию, и ввод-вывод получит нормальное продолжение по другому дескриптору, как показано на примере. В частности, процесс может "закрыть" дескриптор файла стандартного вывода (файловый дескриптор 1), снять с него копию, имеющую то же значение, и затем рассматривать новый файл в качестве файла стандартного вывода. В будет представлен более реалистический пример использования функций pipe и dup при описании особенностей реализации командного процессора.
|
#include <fcntl.h> main() { int i,j; char buf1[512],buf2[512]; i = open("/etc/passwd",O_RDONLY); j = dup(i); read(i,buf1,sizeof(buf1)); read(j,buf2,sizeof(buf2)); close(i); read(j,buf2,sizeof(buf2)); } |
Comments:
Copyright ©
Файловая система
Файловая система UNIX характеризуется:
иерархической структурой, согласованной обработкой массивов данных, возможностью создания и удаления файлов, динамическим расширением файлов, защитой информации в файлах, трактовкой периферийных устройств (таких как терминалы и ленточные устройства) как файлов.
Рисунок 1.2. Пример древовидной структуры файловой системы
Файловая система организована в виде дерева с одной исходной вершиной, которая называется корнем (записывается: "/"); каждая вершина в древовидной структуре файловой системы, кроме листьев, является каталогом файлов, а файлы, соответствующие дочерним вершинам, являются либо каталогами, либо обычными файлами, либо файлами устройств. Имени файла предшествует указание пути поиска, который описывает место расположения файла в иерархической структуре файловой системы. Имя пути поиска состоит из компонент, разделенных между собой наклонной чертой (/); каждая компонента представляет собой набор символов, составляющих имя вершины (файла), которое является уникальным для каталога (предыдущей компоненты), в котором оно содержится. Полное имя пути поиска начинается с указания наклонной черты и идентифицирует файл (вершину), поиск которого ведется от корневой вершины дерева файловой системы с обходом тех ветвей дерева файлов, которые соответствуют именам отдельных компонент. Так, пути "/etc/passwd", "/bin/who" и "/usr/src/cmd/who.c" указывают на файлы, являющиеся вершинами дерева, изображенного на Рисунке , а пути "/bin/passwd" и "/usr/ src/date.c" содержат неверный маршрут. Имя пути поиска необязательно должно начинаться с корня, в нем следует указывать маршрут относительно текущего для выполняемого процесса каталога, при этом предыдущие символы "наклонная черта" в имени пути опускаются. Так, например, если мы находимся в каталоге "/dev", то путь "tty01" указывает файл, полное имя пути поиска для которого "/dev /tty01".
Программы, выполняемые под управлением системы UNIX, не содержат никакой информации относительно внутреннего формата, в котором ядро хранит файлы данных, данные в программах представляются как бесформатный поток байтов. Программы могут интерпретировать поток байтов по своему желанию, при этом любая интерпретация никак не будет связана с фактическим способом хранения данных в операционной системе. Так, синтаксические правила, определяющие задание метода доступа к данным в файле, устанавливаются системой и являются едиными для всех программ, однако семантика данных определяется конкретной программой. Например, программа форматирования текста troff ищет в конце каждой строки текста символы перехода на новую строку, а программа учета системных ресурсов acctcom работает с записями фиксированной длины. Обе программы пользуются одними и теми же системными средствами для осуществления доступа к данным в файле как к потоку байтов, и внутри себя преобразуют этот поток по соответствующему формату. Если любая из программ обнаружит, что формат данных неверен, она принимает соответствующие меры.
Каталоги похожи на обычные файлы в одном отношении; система представляет информацию в каталоге набором байтов, но эта информация включает в себя имена файлов в каталоге в объявленном формате для того, чтобы операционная система и программы, такие как ls (выводит список имен и атрибутов файлов), могли их обнаружить.
Права доступа к файлу регулируются установкой специальных битов разрешения доступа, связанных с файлом. Устанавливая биты разрешения доступа, можно независимо управлять выдачей разрешений на чтение, запись и выполнение для трех категорий пользователей: владельца файла, группового пользователя и прочих. Пользователи могут создавать файлы, если разрешен доступ к каталогу. Вновь созданные файлы становятся листьями в древовидной структуре файловой системы.
Для пользователя система UNIX трактует устройства так, как если бы они были файлами. Устройства, для которых назначены специальные файлы устройств, становятся вершинами в структуре файловой системы. Обращение программ к устройствам имеет тот же самый синтаксис, что и обращение к обычным файлам; семантика операций чтения и записи по отношению к устройствам в большой степени совпадает с семантикой операций чтения и записи обычных файлов. Способ защиты устройств совпадает со способом защиты обычных файлов: путем соответствующей установки битов разрешения доступа к ним (файлам). Поскольку имена устройств выглядят так же, как и имена обычных файлов, и поскольку над устройствами и над обычными файлами выполняются одни и те же операции, большинству программ нет необходимости различать внутри себя типы обрабатываемых файлов.
Например, рассмотрим программу на языке Си (Рисунок ), в которой создается новая копия существующего файла. Предположим, что исполняемая версия программы имеет наименование copy. Для запуска программы пользователь вводит с терминала: copy oldfile newfile
где oldfile - имя существующего файла, а newfile - имя создаваемого файла. Система выполняет процедуру main, присваивая аргументу argc значение количества параметров в списке argv, а каждому элементу массива argv значение параметра, сообщенного пользователем. В приведенном примере argc имеет значение 3, элемент argv[0] содержит строку символов "copy" (имя программы условно является нулевым параметром), argv[1] - строку символов "oldfile", а argv[2] - строку символов "newfile". Затем программа проверяет, правильное ли количество параметров было указано при ее запуске. Если это так, запускается операция open (открыть) для файла oldfile с параметром "read-only" (только для чтения), в случае успешного выполнения которой запускается операция creat (открыть) для файла newfile. Режим доступа к вновь созданному файлу описывается числом 0666 (в восьмеричном коде), что означает разрешение доступа к файлу для чтения и записи для всех пользователей. Все обращения к операционной системе в случае неудачи возвращают код -1; если же неудачно завершаются операции open и creat, программа выдает сообщение и запускает операцию exit (выйти) с возвращением кода состояния, равного 1, завершая свою работу и указывая на возникновение ошибки.
Операции open и creat возвращают целое значение, являющееся дескриптором файла и используемое программой в последующих ссылках на файлы. После этого программа вызывает подпрограмму copy, выполняющую в цикле операцию read (читать), по которой производится чтение в буфер порции символов из существующего файла, и операцию write (писать) для записи информации в новый файл. Операция read каждый раз возвращает количество прочитанных байтов (0 - если достигнут конец файла). Цикл завершается, если достигнут конец файла или если произошла ошибка при выполнении операции read (отсутствует контроль возникновения ошибок при выполнении операции write). Затем управление из подпрограммы copy возвращается в основную программу и запускается операция exit с кодом состояния 0 в качестве параметра, что указывает на успешное завершение выполнения программы.
Программа копирует любые файлы, указанные при ее вызове в качестве аргументов, при условии, что разрешено открытие существующего файла и создание нового файла. Файл может включать в себя как текст, который может быть выведен на печатающее устройство, например, исходный текст программы, так и символы, не выводимые на печать, даже саму программу. Таким образом, оба вызова:
copy copy.c newcopy.c copy copy newcopy
являются допустимыми. Существующий файл также может быть каталогом. Например, по вызову: copy . dircontents
копируется содержимое текущего каталога, обозначенного символом ".", в обычный файл "dircontents"; информация в новом файле совпадает, вплоть до каждого байта, с содержимым каталога, только этот файл обычного типа (для создания нового каталога предназначена операция mknod). Наконец, любой из файлов может быть файлом устройства. Например, программа, вызванная следующим образом: copy /dev/tty terminalread
читает символы, вводимые с терминала (файл /dev/tty соответствует терминалу пользователя), и копирует их в файл terminalread, завершая работу только в том случае, если пользователь нажмет <Ctrl/d>. Похожая форма запуска программы: copy /dev/tty /dev/tty
вызывает чтение символов с терминала и их копирование обратно на терминал.
|
#include <fcntl.h> char buffer[2048]; int version = 1; /* будет объяснено в главе 2 */ main(argc,argv) int argc; char *argv[]; { int fdold,fdnew; if (argc != 3) { printf("need 2 arguments for copy program\n); exit(1); } fdold = open(argv[1],O_RDONLY); /* открыть исходный файл только для чтения */ if (fdold == -1) { printf("cannot open file %s\n",argv[1]); exit(1); } fdnew = creat(argv[2],0666); /* создать новый файл с разрешением чтения и записи для всех поль- зователей */ if (fdnew == -1) { printf("cannot create file %s\n",argv[2]); exit(1); } copy(fdold,fdnew); exit(0); } copy(old,new) int old,new; { int count; while ((count = read(old,buffer,sizeof(buffer))) > 0) write(new,buffer,count); } |
ФОРМАТ ПАМЯТИ СИСТЕМЫ
Предположим, что физическая память машины имеет адреса, начиная с 0 и кончая адресом, равным объему памяти в байтах. Как уже отмечалось в , процесс в системе UNIX состоит из трех логических секций: команд, данных и стека. (Общую память, которая рассматривается в , можно считать в данном контексте частью секции данных). В секции команд хранится набор машинных инструкций, исполняемых под управлением процесса; адресами в секции команд выступают адреса команд (для команд перехода и обращений к подпрограммам), адреса данных (для обращения к глобальным переменным) и адреса стека (для обращения к структурам данных, которые локализованы в подпрограммах). Если адреса в сгенерированном коде трактовать как адреса в физической памяти, два процесса не смогут параллельно выполняться, если их адреса перекрываются. Компилятор мог бы генерировать адреса, непересекающиеся у разных программ, но на универсальных ЭВМ такой порядок не практикуется, поскольку объем памяти машины ограничен, а количество транслируемых программы неограничено. Даже если для того, чтобы избежать излишнего пересечения адресов в процессе их генерации, машина будет использовать некоторый набор эвристических процедур, подобная реализация не будет достаточно гибкой и не сможет удовлетворять предъявляемым к ней требованиям.
Поэтому компилятор генерирует адреса для виртуального адресного пространства заданного диапазона, а устройство управления памятью, называемое диспетчером памяти, транслирует виртуальные адреса, сгенерированные компилятором, в адреса ячеек, расположенных в физической памяти. Компилятору нет необходимости знать, в какое место в памяти ядро потом загрузит выполняемую программу. На самом деле, в памяти одновременно могут существовать несколько копий программы: все они могут выполняться, используя одни и те же виртуальные адреса, фактически же ссылаясь на разные физические ячейки. Те подсистемы ядра и аппаратные средства, которые сотрудничают в трансляции виртуальных адресов в физические, образуют подсистему управления памятью.
ФУНКЦИИ ОПЕРАЦИОННОЙ СИСТЕМЫ
На Рисунке 1.1 уровень ядра операционной системы изображен непосредственно под уровнем прикладных программ пользователя. Выполняя различные элементарные операции по запросам пользовательских процессов, ядро обеспечивает функционирование пользовательского интерфейса, описанного выше. Среди функций ядра можно отметить:
Управление выполнением процессов посредством их создания, завершения или приостановки и организации взаимодействия между ними. Планирование очередности предоставления выполняющимся процессам времени центрального процессора (диспетчеризация). Процессы работают с центральным процессором в режиме разделения времени: центральный процессор выполняет процесс, по завершении отсчитываемого ядром кванта времени процесс приостанавливается и ядро активизирует выполнение другого процесса. Позднее ядро запускает приостановленный процесс. Выделение выполняемому процессу оперативной памяти. Ядро операционной системы дает процессам возможность совместно использовать участки адресного пространства на определенных условиях, защищая при этом адресное пространство, выделенное процессу, от вмешательства извне. Если системе требуется свободная память, ядро освобождает память, временно выгружая процесс на внешние запоминающие устройства, которые называют устройствами выгрузки. Если ядро выгружает процессы на устройства выгрузки целиком, такая реализация системы UNIX называется системой со свопингом (подкачкой); если же на устройство выгрузки выводятся страницы памяти, такая система называется системой с замещением страниц. Выделение внешней памяти с целью обеспечения эффективного хранения информации и выборка данных пользователя. Именно в процессе реализации этой функции создается файловая система. Ядро выделяет внешнюю память под пользовательские файлы, мобилизует неиспользуемую память, структурирует файловую систему в форме, доступной для понимания, и защищает пользовательские файлы от несанкционированного доступа.
Управление доступом процессов к периферийным устройствам, таким как терминалы, ленточные устройства, дисководы и сетевое оборудование.
Выполнение ядром своих функций довольно очевидно. Например, оно узнает, что данный файл является обычным файлом или устройством, но скрывает это различие от пользовательских процессов. Так же оно, форматируя информацию файла для внутреннего хранения, защищает внутренний формат от пользовательских процессов, возвращая им неотформатированный поток байтов. Наконец, ядро реализует ряд необходимых функций по обеспечению выполнения процессов пользовательского уровня, за исключением функций, которые могут быть реализованы на самом пользовательском уровне. Например, ядро выполняет действия, необходимые shell'у как интерпретатору команд: оно позволяет процессору shell читать вводимые с терминала данные, динамически порождать процессы, синхронизировать выполнение процессов, открывать каналы и переадресовывать ввод-вывод. Пользователи могут разрабатывать свои версии командного процессора shell с тем, чтобы привести рабочую среду в соответствие со своими требованиями, не затрагивая других пользователей. Такие программы пользуются теми же услугами ядра, что и стандартный процессор shell.
(*****) В главе 12 рассматриваются многопроцессорные системы; до того речь будет идти об однопроцессорной модели.
Comments:
Copyright ©
ОБЩИЙ ОБЗОР ОСОБЕННОСТЕЙ СИСТЕМЫ
За время, прошедшее с момента ее появления в 1969 году, система UNIX стала довольно популярной и получила распространение на машинах с различной мощностью обработки, от микропроцессоров до больших ЭВМ, обеспечивая на них общие условия выполнения программ. Система делится на две части. Одну часть составляют программы и сервисные функции, то, что делает операционную среду UNIX такой популярной; эта часть легко доступна пользователям, она включает такие программы, как командный процессор, обмен сообщениями, пакеты обработки текстов и системы обработки исходных текстов программ. Другая часть включает в себя собственно операционную систему, поддерживающую эти программы и функции. В этой книге дается детальное описание собственно операционной системы. Основное внимание концентрируется на описании системы UNIX версии V, распространением которой занимается корпорация AT&T, при этом рассматриваются интересные особенности и других версий. Приводятся основные информационные структуры и алгоритмы, используемые в операционной системе и в конечном итоге создающие условия для функционирования стандартного пользовательского интерфейса.
Данная глава служит введением в систему UNIX. В ней делается обзор истории ее создания и намечаются контуры общей структуры системы. В следующей главе содержится более детальная вводная информация по операционной системе.
Comments:
Copyright ©
ВВЕДЕНИЕ В АРХИТЕКТУРУ ЯДРА ОПЕРАЦИОННОЙ СИСТЕМЫ
В предыдущей главе был сделан только поверхностный обзор особенностей операционной среды UNIX. В этой главе основное внимание уделяется ядру операционной системы, делается обзор его архитектуры и излагаются в общих чертах основные понятия и структуры, существенные для понимания всего последующего материала книги.
БУФЕР СВЕРХОПЕРАТИВНОЙ ПАМЯТИ (КЕШ)
Как уже говорилось в предыдущей главе, ядро операционной системы поддерживает файлы на внешних запоминающих устройствах большой емкости, таких как диски, и позволяет процессам сохранять новую информацию или вызывать ранее сохраненную информацию. Если процессу необходимо обратиться к информации файла, ядро выбирает информацию в оперативную память, где процесс сможет просматривать эту информацию, изменять ее и обращаться с просьбой о ее повторном сохранении в файловой системе. Вспомним для примера программу copy, приведенную на Рисунке : ядро читает данные из первого файла в память и затем записывает эти данные во второй файл. Подобно тому, как ядро должно заносить данные из файла в память, оно так же должно считывать в память и вспомогательные данные для работы с ними. Например, суперблок файловой системы содержит помимо всего прочего информацию о свободном пространстве, доступном файловой системе. Ядро считывает суперблок в память для того, чтобы иметь доступ к его информации, и возвращает его опять файловой системе, когда желает сохранить его содержимое. Похожая вещь происходит с индексом, который описывает размещение файла. Ядро системы считывает индекс в память, когда желает получить доступ к информации файла, и возвращает индекс вновь файловой системе, когда желает скорректировать размещение файла. Ядро обрабатывает такую вспомогательную информацию, не будучи прежде знакома с ней и не требуя для ее обработки запуска каких-либо процессов.
Ядро могло бы производить чтение и запись непосредственно с диска и на диск при всех обращениях к файловой системе, однако время реакции системы и производительность при этом были бы низкими из-за низкой скорости передачи данных с диска. По этой причине ядро старается свести к минимуму частоту обращений к диску, заведя специальную область внутренних информационных буферов, именуемую буферным кешем . и хранящую содержимое блоков диска, к которым перед этим производились обращения.
На Рисунке показано, что модуль буферного кеша занимает в архитектуре ядра место между подсистемой управления файлами и драйверами устройств (ввода-вывода блоками). Перед чтением информации с диска ядро пытается считать что-нибудь из буфера кеша. Если в этом буфере отсутствует информация, ядро читает данные с диска и заносит их в буфер, используя алгоритм, который имеет целью поместить в буфере как можно больше необходимых данных. Аналогично, информация, записываемая на диск, заносится в буфер для того, чтобы находиться там, если ядро позднее попытается считать ее. Ядро также старается свести к минимуму частоту выполнения операций записи на диск, выясняя, должна ли информация действительно запоминаться на диске или это промежуточные данные, которые будут вскоре затерты. Алгоритмы более высокого уровня позволяют производить предварительное занесение данных в буфер кеша или задерживать запись данных с тем, чтобы усилить эффект использования буфера. В этой главе рассматриваются алгоритмы, используемые ядром при работе с буферами в сверхоперативной памяти.
(*) Буферный кеш представляет собой программную структуру, которую не следует путать с аппаратными кешами, ускоряющими косвенную адресацию памяти.
Comments:
Copyright ©
ВНУТРЕННЕЕ ПРЕДСТАВЛЕНИЕ ФАЙЛОВ
Как уже было замечено , каждый файл в системе UNIX имеет уникальный индекс. Индекс содержит информацию, необходимую любому процессу для того, чтобы обратиться к файлу, например, права собственности на файл, права доступа к файлу, размер файла и расположение данных файла в файловой системе. Процессы обращаются к файлам, используя четко определенный набор системных вызовов и идентифицируя файл строкой символов, выступающих в качестве составного имени файла. Каждое составное имя однозначно определяет файл, благодаря чему ядро системы преобразует это имя в индекс файла.
Эта глава посвящена описанию внутренней структуры файлов в операционной системе UNIX, в следующей же главе рассматриваются обращения к операционной системе, связанные с обработкой файлов. касается индекса и работы с ним ядра, - внутренней структуры обычных файлов и некоторых моментов, связанных с чтением и записью ядром информации файлов. исследуется строение каталогов - структур данных, позволяющих ядру организовывать файловую систему в виде иерархии файлов, содержит алгоритм преобразования имен пользовательских файлов в индексы. дается структура суперблока, а в разделах и представлены алгоритмы назначения файлам дисковых индексов и дисковых блоков. Наконец, идет речь о других типах файлов в системе, а именно о каналах и файлах устройств.
Алгоритмы, описанные в этой главе, уровнем выше по сравнению с алгоритмами управления буферным кешем, рассмотренными в предыдущей главе (). Алгоритм iget возвращает последний из идентифицированных индексов с возможностью считывания его с диска, используя буферный кеш, а алгоритм iput освобождает индекс. Алгоритм bmap устанавливает параметры ядра, связанные с обращением к файлу. Алгоритм namei преобразует составное имя пользовательского файла в имя индекса, используя алгоритмы iget, iput и bmap. Алгоритмы alloc и free выделяют и освобождают дисковые блоки для файлов, алгоритмы ialloc и ifree назначают и освобождают для файлов индексы.
Рисунок 4.1. Алгоритмы файловой системы
Comments:
Copyright ©
СИСТЕМНЫЕ ОПЕРАЦИИ ДЛЯ РАБОТЫ С ФАЙЛОВОЙ СИСТЕМОЙ
В последней главе рассматривались внутренние структуры данных для файловой системы и алгоритмы работы с ними. В этой главе речь пойдет о системных функциях для работы с файловой системой с использованием понятий, введенных в предыдущей главе. Рассматриваются системные функции, обеспечивающие обращение к существующим файлам, такие как open, read, write, lseek и close, затем функции создания новых файлов, а именно, creat и mknod, и, наконец, функции для работы с индексом или для передвижения по файловой системе: chdir, chroot, chown, stat и fstat. Исследуются более сложные системные функции: pipe и dup имеют важное значение для реализации каналов в shell'е; mount и umount расширяют видимое для пользователя дерево файловых систем; link и unlink изменяют иерархическую структуру файловой системы. Затем дается представление об абстракциях, связанных с файловой системой, в отношении поддержки различных файловых систем, подчиняющихся стандартным интерфейсам. В последнем разделе главы речь пойдет о сопровождении файловой системы. Глава знакомит с тремя структурами данных ядра: таблицей файлов, в которой каждая запись связана с одним из открытых в системе файлов, таблицей пользовательских дескрипторов файлов, в которой каждая запись связана с файловым дескриптором, известным процессу, и таблицей монтирования, в которой содержится информация по каждой активной файловой системе.
Рисунок 5.1. Функции для работы с файловой системой и их связь с другими алгоритмами
На Рисунке 5. 1 показана взаимосвязь между системными функциями и алгоритмами, описанными ранее. Системные функции классифицируются на несколько категорий, хотя некоторые из функций присутствуют более, чем в одной категории:
Системные функции, возвращающие дескрипторы файлов для использования другими системными функциями; Системные функции, использующие алгоритм namei для анализа имени пути поиска; Системные функции, назначающие и освобождающие индекс с использованием алгоритмов ialloc и ifree; Системные функции, устанавливающие или изменяющие атрибуты файла; Системные функции, позволяющие процессу производить ввод-вывод данных с использованием алгоритмов alloc, free и алгоритмов выделения буфера; Системные функции, изменяющие структуру файловой системы; Системные функции, позволяющие процессу изменять собственное представление о структуре дерева файловой системы.
Comments:
Copyright ©
СТРУКТУРА ПРОЦЕССОВ
В были сформулированы характеристики процессов. В настоящей главе на более формальном уровне определяется понятие "контекст процесса" и показывается, каким образом ядро идентифицирует процесс и определяет его местонахождение. В описаны модель состояний процессов для системы UNIX и последовательность возможных переходов из состояния в состояние. В ядре находится таблица процессов, каждая запись которой описывает состояние одного из активных процессов в системе. В пространстве процесса хранится дополнительная информация, используемая в управлении протеканием процесса. Запись в таблице процессов и пространство процесса составляют в совокупности контекст процесса. Аспектом контекста процесса, наиболее явно отличающим данный контекст от контекста другого процесса, без сомнения является содержимое адресного пространства процесса. В описываются принципы управления распределением памяти для процессов и ядра, а также взаимодействие операционной системы с аппаратными средствами при трансляции виртуальных адресов в физические. посвящен рассмотрению составных элементов контекста процесса, а также описанию алгоритмов управления контекстом процесса. демонстрирует, каким образом осуществляется сохранение контекста процесса ядром в случае прерывания, вызова системной функции или переключения контекста, а также каким образом возобновляется выполнение приостановленного процесса. В приводятся различные алгоритмы, используемые в тех системных функциях, которые работают с адресным пространством процесса и которые будут рассмотрены в следующей главе. И, наконец, в рассматриваются алгоритмы приостанова и возобновления выполнения процессов.
Comments:
Copyright ©
УПРАВЛЕНИЕ ПРОЦЕССАМИ
В предыдущей главе был рассмотрен контекст процесса и описаны алгоритмы для работы с ним; в данной главе речь пойдет об использовании и реализации системных функций, управляющих контекстом процесса. Системная функция fork создает новый процесс, функция exit завершает выполнение процесса, а wait дает возможность родительскому процессу синхронизировать свое продолжение с завершением порожденного процесса. Об асинхронных событиях процессы информируются при помощи сигналов. Поскольку ядро синхронизирует выполнение функций exit и wait при помощи сигналов, описание механизма сигналов предваряет собой рассмотрение функций exit и wait. Системная функция exec дает процессу возможность запускать "новую" программу, накладывая ее адресное пространство на исполняемый образ файла. Системная функция brk позволяет динамически выделять дополнительную память; теми же самыми средствами ядро динамически наращивает стек задачи, выделяя в случае необходимости дополнительное пространство. В заключительной части главы дается краткое описание основных групп операций командного процессора shell и начального процесса init.
На показана взаимосвязь между системными функциями, рассматриваемыми в данной главе, с одной стороны, и алгоритмами, описанными в предыдущей главе, с другой. Почти во всех функциях используются алгоритмы sleep и wakeup, отсутствующие на рисунке. Функция exec, кроме того, взаимодействует с алгоритмами работы с файловой системой, речь о которых шла в главах и .
| | Системные функции, имеющие | Системные функции, | Функции | | ющие дело с управлением па- | связанные с синхро- | смешанного | | мятью | низацией | типа | +-------+-------+-------+-----+--+----+------+----+-+-----+------+ | fork | exec | brk | exit |wait|signal|kill|setrgrр|setuid| +-------+-------+-------+--------+----+------+----+-------+------+ |dupreg |detach-|growreg| detach-| | |attach-| reg | | reg | | | reg |alloc- | | | | | | reg | | | | | |attach-| | | | | | reg | | | | | |growreg| | | | | |loadreg| | | | | |mapreg | | | | |
Рисунок 7.1. Системные функции управления процессом и их связь с другими алгоритмами
Comments:
Copyright ©
ДИСПЕТЧЕРИЗАЦИЯ ПРОЦЕССОВ И ЕЕ ВРЕМЕННЫЕ ХАРАКТЕРИСТИКИ
В системе разделения времени ядро предоставляет процессу ресурсы центрального процессора (ЦП) на интервал времени, называемый квантом, по истечении которого выгружает этот процесс и запускает другой, периодически переупорядочивая очередь процессов. Алгоритм планирования процессов в системе UNIX использует время выполнения в качестве параметра. Каждый активный процесс имеет приоритет планирования; ядро переключает контекст на процесс с наивысшим приоритетом. При переходе выполняющегося процесса из режима ядра в режим задачи ядро пересчитывает его приоритет, периодически и в режиме задачи переустанавливая приоритет каждого процесса, готового к выполнению.
Информация о времени, связанном с выполнением, нужна также и некоторым из пользовательских процессов: используемая ими, например, команда time позволяет узнать, сколько времени занимает выполнение другой команды, команда date выводит текущую дату и время суток. С помощью различных системных функций процессы могут устанавливать или получать временные характеристики выполнения в режиме ядра, а также степень загруженности центрального процессора. Время в системе поддерживается с помощью аппаратных часов, которые посылают ЦП прерывания с фиксированной, аппаратно-зависимой частотой, обычно 50-100 раз в секунду. Каждое поступление прерывания по таймеру (часам) именуется таймерным тиком. В настоящей главе рассматриваются особенности реализации процессов во времени, включая планирование процессов в системе UNIX, описание связанных со временем системных функций, а также функций, выполняемых программой обработки прерываний по таймеру.
Comments:
Copyright ©
АЛГОРИТМЫ УПРАВЛЕНИЯ ПАМЯТЬЮ
Алгоритм планирования использования процессорного времени, рассмотренный в предыдущей главе, в сильной степени зависит от выбранной стратегии управления памятью. Процесс может выполняться, если он хотя бы частично присутствует в основной памяти; ЦП не может исполнять процесс, полностью выгруженный во внешнюю память. Тем не менее, основная память - чересчур дефицитный ресурс, который зачастую не может вместить все активные процессы в системе. Если, например, в системе имеется основная память объемом 8 Мбайт, то девять процессов размером по 1 Мбайту каждый уже не смогут в ней одновременно помещаться. Какие процессы в таком случае следует размещать в памяти (хотя бы частично), а какие нет, решает подсистема управления памятью, она же управляет участками виртуального адресного пространства процесса, не резидентными в памяти. Она следит за объемом доступного пространства основной памяти и имеет право периодически переписывать процессы на устройство внешней памяти, именуемое устройством выгрузки, освобождая в основной памяти дополнительное место. Позднее ядро может вновь поместить данные с устройства выгрузки в основную память.
В ранних версиях системы UNIX процессы переносились между основной памятью и устройством выгрузки целиком и, за исключением разделяемой области команд, отдельные независимые части процесса не могли быть объектами перемещения. Такая стратегия управления памятью называется свопингом (подкачкой). Такую стратегию имело смысл реализовывать на машине типа PDP-11, где максимальный размер процесса составлял 64 Кбайта. При использовании этой стратегии размер процесса ограничивается объемом физической памяти, доступной в системе. Система BSD (версия 4.0) явилась главным полигоном для применения другой стратегии, стратегии "подкачки по обращению" (demand paging), в соответствии с которой основная память обменивается с внешней не процессами, а страницами памяти; эта стратегия поддерживается и в последних редакциях версии V системы UNIX. Держать в основной памяти весь выполняемый процесс нет необходимости, и ядро загружает в память только отдельные страницы по запросу выполняющегося процесса, ссылающегося на них. Преимущество стратегии подкачки по обращению состоит в том, что благодаря ей отображение виртуального адресного пространства процесса на физическую память машины становится более гибким: допускается превышение размером процесса объема доступной физической памяти и одновременное размещение в основной памяти большего числа процессов. Преимущество стратегии свопинга состоит в простоте реализации и облегчении "надстроечной" части системы. Обе стратегии управления памятью рассматриваются в настоящей главе.
Comments:
Copyright ©
ПОДСИСТЕМА УПРАВЛЕНИЯ ВВОДОМ-ВЫВОДОМ
Подсистема управления вводом-выводом позволяет процессам поддерживать связь с периферийными устройствами, такими как накопители на магнитных дисках и лентах, терминалы, принтеры и сети, с одной стороны, и с модулями ядра, которые управляют устройствами и именуются драйверами устройств, с другой. Между драйверами устройств и типами устройств обычно существует однозначное соответствие: в системе может быть один дисковый драйвер для управления всеми дисководами, один терминальный драйвер для управления всеми терминалами и один ленточный драйвер для управления всеми ленточными накопителями. Если в системе имеются однотипные устройства, полученные от разных изготовителей - например, две марки ленточных накопителей, - в этом случае можно трактовать однотипные устройства как устройства двух различных типов и иметь для них два отдельных драйвера, поскольку таким устройствам для выполнения одних и тех же операций могут потребоваться разные последовательности команд. Один драйвер управляет множеством физических устройств данного типа. Например, один терминальный драйвер может управлять всеми терминалами, подключенными к системе. Драйвер различает устройства, которыми управляет: выходные данные, предназначенные для одного терминала, не должны быть посланы на другой.
Система поддерживает "программные устройства", с каждым из которых не связано ни одно конкретное физическое устройство. Например, как устройство трактуется физическая память, чтобы позволить процессу обращаться к ней извне, пусть даже память не является периферийным устройством. Команда ps обращается к информационным структурам ядра в физической памяти, чтобы сообщить статистику процессов. Еще один пример: драйверы могут вести трассировку записей в удобном для отладки виде, а драйвер трассировки дает возможность пользователям читать эти записи. Наконец, профиль ядра, рассмотренный в , выполнен как драйвер: процесс записывает адреса программ ядра, обнаруженных в таблице идентификаторов ядра, и читает результаты профилирования.
В этой главе рассматривается взаимодействие между процессами и подсистемой управления вводом-выводом, а также между машиной и драйверами устройств. Исследуется общая структура и функционирование драйверов и в качестве примеров общего взаимодействия рассматриваются дисковые и терминальные драйверы. Завершает главу описание нового метода реализации драйверов потоковых устройств.
Comments:
Copyright ©
ВЗАИМОДЕЙСТВИЕ ПРОЦЕССОВ
Наличие механизмов взаимодействия дает произвольным процессам возможность осуществлять обмен данными и синхронизировать свое выполнение с другими процессами. Мы уже рассмотрели несколько форм взаимодействия процессов, такие как канальная связь, использование поименованных каналов и посылка сигналов. Каналы (непоименованные) имеют недостаток, связанный с тем, что они известны только потомкам процесса, вызвавшего системную функцию pipe: не имеющие родственных связей процессы не могут взаимодействовать между собой с помощью непоименованных каналов. Несмотря на то, что поименованные каналы позволяют взаимодействовать между собой процессам, не имеющим родственных связей, они не могут использоваться ни в сети (см. ), ни в организации множественных связей между различными группами взаимодействующих процессов: поименованный канал не поддается такому мультиплексированию, при котором у каждой пары взаимодействующих процессов имелся бы свой выделенный канал. Произвольные процессы могут также связываться между собой благодаря посылке сигналов с помощью системной функции kill, однако такое "сообщение" состоит из одного только номера сигнала.
В данной главе описываются другие формы взаимодействия процессов. В начале речь идет о трассировке процессов, о том, каким образом один процесс следит за ходом выполнения другого процесса, затем рассматривается пакет IPC: сообщения, разделяемая память и семафоры. Делается обзор традиционных методов сетевого взаимодействия процессов, выполняющихся на разных машинах, и, наконец, дается представление о "гнездах", применяющихся в системе BSD. Вопросы сетевого взаимодействия, имеющие специальный характер, такие как протоколы, адресация и др., не рассматриваются, поскольку они выходят за рамки настоящей работы.
Comments:
Copyright ©
МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ
В классической постановке для системы UNIX предполагается использование однопроцессорной архитектуры, состоящей из одного ЦП, памяти и периферийных устройств. Многопроцессорная архитектура, напротив, включает в себя два и более ЦП, совместно использующих общую память и периферийные устройства (), располагая большими возможностями в увеличении производительности системы, связанными с одновременным исполнением процессов на разных ЦП. Каждый ЦП функционирует независимо от других, но все они работают с одним и тем же ядром операционной системы. Поведение процессов в такой системе ничем не отличается от поведения в однопроцессорной системе - с сохранением семантики обращения к каждой системной функции - но при этом они могут открыто перемещаться с одного процессора на другой. Хотя, к сожалению, это не приводит к снижению затрат процессорного времени, связанного с выполнением процесса. Отдельные многопроцессорные системы называются системами с присоединенными процессорами, поскольку в них периферийные устройства доступны не для всех процессоров. За исключением особо оговоренных случаев, в настоящей главе не проводится никаких различий между системами с присоединенными процессорами и остальными классами многопроцессорных систем.
Параллельная работа нескольких процессоров в режиме ядра по выполнению различных процессов создает ряд проблем, связанных с сохранением целостности данных и решаемых благодаря использованию соответствующих механизмов защиты. Ниже будет показано, почему классический вариант системы UNIX не может быть принят в многопроцессорных системах без внесения необходимых изменений, а также будут рассмотрены два варианта, предназначенные для работы в указанной среде.

Рисунок 12.1. Многопроцессорная конфигурация
Comments:
Copyright ©
РАСПРЕДЕЛЕННЫЕ СИСТЕМЫ
В предыдущей главе нами были рассмотрены сильносвязанные многопроцессорные системы с общей памятью, общими структурами данных ядра и общим пулом, из которого процессы вызываются на выполнение. Часто, однако, бывает желательно в целях обеспечения совместного использования ресурсов распределять процессоры таким образом, чтобы они были автономны от операционной среды и условий эксплуатации. Пусть, например, пользователю персональной ЭВМ нужно обратиться к файлам, находящимся на более крупной машине, но сохранить при этом контроль над персональной ЭВМ. Несмотря на то, что отдельные программы, такие как uucp, поддерживают передачу файлов по сети и другие сетевые функции, их использование не будет скрыто от пользователя, поскольку пользователь знает о том, что он работает в сети. Кроме того, надо заметить, что программы, подобные текстовым редакторам, с удаленными файлами, как с обычными, не работают. Пользователи должны располагать стандартным набором функций системы UNIX и, за исключением возможной потери в быстродействии, не должны ощущать пересечения машинных границ. Так, например, работа системных функций open и read с файлами на удаленных машинах не должна отличаться от их работы с файлами, принадлежащими локальным системам.
Архитектура распределенной системы представлена на . Каждый компьютер, показанный на рисунке, является автономным модулем, состоящим из ЦП, памяти и периферийных устройств. Соответствие модели не нарушается даже несмотря на то, что компьютер не располагает локальной файловой системой: он должен иметь периферийные устройства для связи с другими машинами, а все принадлежащие ему файлы могут располагаться и на ином компьютере. Физическая память, доступная каждой машине, не зависит от процессов, выполняемых на других машинах. Этой особенностью распределенные системы отличаются от сильносвязанных многопроцессорных систем, рассмотренных в предыдущей главе. Соответственно, и ядро

Рисунок 13.1. Модель системы с распределенной архитектурой
системы на каждой машине функционирует независимо от внешних условий эксплуатации распределенной среды.
Распределенные системы, хорошо описанные в литературе, традиционно делятся на следующие категории:
периферийные системы, представляющие собой группы машин, отличающихся ярковыраженной общностью и связанных с одной (обычно более крупной) машиной. Периферийные процессоры делят свою нагрузку с центральным процессором и переадресовывают ему все обращения к операционной системе. Цель периферийной системы состоит в увеличении общей производительности сети и в предоставлении возможности выделения процессора одному процессу в операционной среде UNIX. Система запускается как отдельный модуль; в отличие от других моделей распределенных систем, периферийные системы не обладают реальной автономией, за исключением случаев, связанных с диспетчеризацией процессов и распределением локальной памяти. распределенные системы типа "Newcastle", позволяющие осуществлять дистанционную связь по именам удаленных файлов в библиотеке (название взято из статьи "The Newcastle Connection" - см. [Brownbridge 82]). Удаленные файлы имеют спецификацию (составное имя), которая в указании пути поиска содержит специальные символы или дополнительную компоненту имени, предшествующую корню файловой системы. Реализация этого метода не предполагает внесения изменений в ядро системы, вследствие этого он более прост, чем другие методы, рассматриваемые в этой главе, но менее гибок. абсолютно "прозрачные" распределенные системы, в которых для обращения к файлам, расположенным на других машинах, достаточно указания их стандартных составных имен; распознавание этих файлов как удаленных входит в обязанности ядра. Маршруты поиска файлов, указанные в их составных именах, пересекают машинные границы в точках монтирования, сколько бы таких точек ни было сформировано при монтировании файловых систем на дисках.
В настоящей главе мы рассмотрим архитектуру каждой модели; все приводимые сведения базируются не на результатах конкретных разработок, а на информации, публиковавшейся в различных технических статьях. При этом предполагается, что забота об адресации, маршрутизации, управлении потоками, обнаружении и исправлении ошибок возлагается на модули протоколов и драйверы устройств, другими словами, что каждая модель не зависит от используемой сети. Примеры использования системных функций, приводимые в следующем разделе для периферийных систем, работают аналогичным образом и для систем типа Newcastle и для абсолютно "прозрачных" систем, о которых пойдет речь позже; поэтому в деталях мы их рассмотрим один раз, а в разделах, посвященных другим типам систем, остановимся в основном на особенностях, отличающих эти модели от всех остальных.
Comments:
Copyright ©
ГЛАВНЫЙ И ПОДЧИНЕННЫЙ ПРОЦЕССОРЫ
Систему с двумя процессорами, один из которых - главный (master) - может работать в режиме ядра, а другой - подчиненный (slave) - только в режиме задачи, впервые реализовал на машинах типа VAX 11/780 Гобл (см. [Goble 81]). Эта система, реализованная вначале на двух машинах, получила свое дальнейшее развитие в системах с одним главным и несколькими подчиненными процессорами. Главный процессор несет ответственность за обработку всех обращений к операционной системе и всех прерываний. Подчиненные процессоры ведают выполнением процессов в режиме задачи и информируют главный процессор о всех производимых обращениях к системным функциям.
Выбор процессора, на котором будет выполняться данный процесс, производится в соответствии с алгоритмом диспетчеризации (). В соответствующей записи таблицы процессов появляется новое поле, в которое записывается идентификатор выбранного процессора; предположим для простоты, что он показывает, является ли процессор главным или подчиненным. Когда процесс производит обращение к системной функции, выполняясь на подчиненном процессоре, подчиненное ядро переустанавливает значение поля идентификации процессора таким образом, чтобы оно указывало на главный процессор, и переключает контекст на другие процессы (). Главное ядро запускает на выполнение процесс с наивысшим приоритетом среди тех процессов, которые должны выполняться на главном процессоре. Когда выполнение системной функции завершается, поле идентификации процессора перенастраивается обратно, и процесс вновь возвращается на подчиненный процессор.
Если процессы должны выполняться на главном процессоре, желательно, чтобы главный процессор обрабатывал их как можно скорее и не заставлял их ждать своей очереди чересчур долго. Похожая мотивировка приводится в объяснение выгрузки процесса из памяти в однопроцессорной системе после выхода из системной функции с освобождением соответствующих ресурсов для выполнения более насущных счетных операций. Если в тот момент, когда подчиненный процессор делает запрос на исполнение системной функции, главный процесс выполняется в режиме задачи, его выполнение будет продолжаться до следующего переключения контекста. Главный процессор реагировал бы гораздо быстрее, если бы подчиненный процессор устанавливал при этом глобальный флаг; проверяя установку флага во время обработки очередного прерывания по таймеру, главный процессор произвел бы в итоге переключение контекста максимум через один таймерный тик. С другой стороны, подчиненный процессор мог бы прервать работу главного и заставить его переключить контекст немедленно, но данная возможность требует специальной аппаратной реализации.
| алгоритм schedule_process (модифицированный) входная информация: отсутствует выходная информация: отсутствует { выполнять пока (для запуска не будет выбран один из про- цессов) { если (работа ведется на главном процессоре) для (всех процессов в очереди готовых к выполне- нию) выбрать процесс, имеющий наивысший приоритет среди загруженных в память; в противном случае /* работа ведется на подчинен- * ном процессоре */ для (тех процессов в очереди, которые не нуждают- ся в главном процессоре) выбрать процесс, имеющий наивысший приоритет среди загруженных в память; если (для запуска не подходит ни один из процессов) не загружать машину, переходящую в состояние про- стоя; /* из этого состояния машина выходит в результате * прерывания */ } убрать выбранный процесс из очереди готовых к выполне- нию; переключиться на контекст выбранного процесса, возобно- вить его выполнение; } |
Рисунок 12.3. Алгоритм диспетчеризации
| алгоритм syscall /* исправленный алгоритм вызова систем- * ной функции */ входная информация: код системной функции выходная информация: результат выполнения системной функции { если (работа ведется на подчиненном процессоре) { переустановить значение поля идентификации процессо- ра в соответствующей записи таблицы процессов; произвести переключение контекста; } выполнить обычный алгоритм реализации системной функции; перенастроить значение поля идентификации процессора, чтобы оно указывало на "любой" (подчиненный); если (на главном процессоре должны выполняться другие процессы) произвести переключение контекста; } |
Программа обработки прерываний по таймеру на подчиненном процессоре следит за периодичностью перезапуска процессов, не допуская монопольного использования процессора одной задачей. Кроме того, каждую секунду эта программа выводит подчиненный процессор из состояния бездействия (простоя). Подчиненный процессор выбирает для выполнения процесс с наивысшим приоритетом среди тех процессов, которые не нуждаются в главном процессоре.
Единственным местом, где целостность структур данных ядра еще подвергается опасности, является алгоритм диспетчеризации, поскольку он не предохраняет от выбора процесса на выполнение сразу на двух процессорах. Например, если в конфигурации имеется один главный процессор и два подчиненных, не исключена возможность того, что оба подчиненных процессора выберут для выполнения в режиме задачи один и тот же процесс. Если оба процессора начнут выполнять его параллельно, осуществляя чтение и запись, это неизбежно приведет к искажению содержимого адресного пространства процесса.
Избежать возникновения этой проблемы можно двумя способами. Во-первых, главный процессор может явно указать, на каком из подчиненных процессоров следует выполнять данный процесс. Если на каждый процессор направлять несколько процессов, возникает необходимость в сбалансировании нагрузки (на один из процессоров назначается большое количество процессов, в то время как другие процессоры простаивают). Задача распределения нагрузки между процессорами ложится на главное ядро. Во-вторых, ядро может проследить за тем, чтобы в каждый момент времени в алгоритме диспетчеризации принимал участие только один процессор, для этого используются механизмы, подобные семафорам.
Comments:
Copyright ©
ГНЕЗДА
В предыдущем разделе было показано, каким образом взаимодействуют между собой процессы, протекающие на разных машинах, при этом обращалось внимание на то, что способы реализации взаимодействия могут быть различаться в зависимости от используемых протоколов и сетевых средств. Более того, эти способы не всегда применимы для обслуживания взаимодействия процессов, выполняющихся на одной и той же машине, поскольку в них предполагается существование обслуживающего (серверного) процесса, который при выполнении системных функций open или read будет приостанавливаться драйвером. В целях создания более универсальных методов взаимодействия процессов на основе использования многоуровневых сетевых протоколов для системы BSD был разработан механизм, получивший название "sockets" (гнезда) (см. [Berkeley 83]). В данном разделе мы рассмотрим некоторые аспекты применения гнезд (на пользовательском уровне представления).

Рисунок 11.18. Модель с использованием гнезд
Структура ядра имеет три уровня: гнезд, протоколов и устройств (). Уровень гнезд выполняет функции интерфейса между обращениями к операционной системе (системным функциям) и средствами низких уровней, уровень протоколов содержит модули, обеспечивающие взаимодействие процессов (на рисунке упомянуты протоколы TCP и IP), а уровень устройств содержит драйверы, управляющие сетевыми устройствами. Допустимые сочетания протоколов и драйверов указываются при построении системы (в секции конфигурации); этот способ уступает по гибкости вышеупомянутому потоковому механизму. Процессы взаимодействуют между собой по схеме клиент-сервер: сервер ждет сигнала от гнезда, находясь на одном конце дуплексной линии связи, а процессы-клиенты взаимодействуют с сервером через гнездо, находящееся на другом конце, который может располагаться на другой машине. Ядро обеспечивает внутреннюю связь и передает данные от клиента к серверу.
Гнезда, обладающие одинаковыми свойствами, например, опирающиеся на общие соглашения по идентификации и форматы адресов (в протоколах), группируются в домены (управляемые одним узлом). В системе BSD 4.2 поддерживаются домены: "UNIX system" - для взаимодействия процессов внутри одной машины и "Internet" (межсетевой) - для взаимодействия через сеть с помощью протокола DARPA (Управление перспективных исследований и разработок Министерства обороны США) (см. [Postel 80] и [Postel 81]). Гнезда бывают двух типов: виртуальный канал (потоковое гнездо, если пользоваться терминологией Беркли) и дейтаграмма. Виртуальный канал обеспечивает надежную доставку данных с сохранением исходной последовательности. Дейтаграммы не гарантируют надежную доставку с сохранением уникальности и последовательности, но они более экономны в смысле использования ресурсов, поскольку для них не требуются сложные установочные операции; таким образом, дейтаграммы полезны в отдельных случаях взаимодействия. Для каждой допустимой комбинации типа домен-гнездо в системе поддерживается умолчание на используемый протокол. Так, например, для домена "Internet" услуги виртуального канала выполняет протокол транспортной связи (TCP), а функции дейтаграммы - пользовательский дейтаграммный протокол (UDP).
Существует несколько системных функций работы с гнездами. Функция socket устанавливает оконечную точку линии связи. sd = socket(format,type,protocol);
Format обозначает домен ("UNIX system" или "Internet"), type - тип связи через гнездо (виртуальный канал или дейтаграмма), а protocol - тип протокола, управляющего взаимодействием. Дескриптор гнезда sd, возвращаемый функцией socket, используется другими системными функциями. Закрытие гнезд выполняет функция close.
Функция bind связывает дескриптор гнезда с именем: bind(sd,address,length);
где sd - дескриптор гнезда, address - адрес структуры, определяющей идентификатор, характерный для данной комбинации домена и протокола (в функции socket). Length - длина структуры address; без этого параметра ядро не знало бы, какова длина структуры, поскольку для разных доменов и протоколов она может быть различной. Например, для домена "UNIX system" структура содержит имя файла. Процессы-серверы связывают гнезда с именами и объявляют о состоявшемся присвоении имен процессам-клиентам.
С помощью системной функции connect делается запрос на подключение к существующему гнезду: connect(sd,address,length);
Семантический смысл параметров функции остается прежним (см. функцию bind), но address указывает уже на выходное гнездо, образующее противоположный конец линии связи. Оба гнезда должны использовать одни и те же домен и протокол связи, и тогда ядро удостоверит правильность установки линии связи. Если тип гнезда - дейтаграмма, сообщаемый функцией connect ядру адрес будет использоваться в последующих обращениях к функции send через данное гнездо; в момент вызова никаких соединений не производится.
Пока процесс-сервер готовится к приему связи по виртуальному каналу, ядру следует выстроить поступающие запросы в очередь на обслуживание. Максимальная длина очереди задается с помощью системной функции listen: listen(sd,qlength)
где sd - дескриптор гнезда, а qlength - максимально-допустимое число запросов, ожидающих обработки.

Рисунок 11.19. Прием вызова сервером
Системная функция accept принимает запросы на подключение, поступающие на вход процесса-сервера: nsd = accept(sd,address,addrlen);
где sd - дескриптор гнезда, address - указатель на пользовательский массив, в котором ядро возвращает адрес подключаемого клиента, addrlen - размер пользовательского массива. По завершении выполнения функции ядро записывает в переменную addrlen размер пространства, фактически занятого массивом. Функция возвращает новый дескриптор гнезда (nsd), отличный от дескриптора sd. Процесс-сервер может продолжать слежение за состоянием объявленного гнезда, поддерживая связь с клиентом по отдельному каналу ().
Функции send и recv выполняют передачу данных через подключенное гнездо. Синтаксис вызова функции send: count = send(sd,msg,length,flags);
где sd - дескриптор гнезда, msg - указатель на посылаемые данные, length размер данных, count - количество фактически переданных байт. Параметр flags может содержать значение SOF_OOB (послать данные out-of-band - "через таможню"), если посылаемые данные не учитываются в общем информационном обмене между взаимодействующими процессами. Программа удаленной регистрации, например, может послать out-of-band сообщение, имитирующее нажатие на клавиатуре терминала клавиши "delete". Синтаксис вызова системной функции recv: count = recv(sd,buf,length,flags);
где buf - массив для приема данных, length - ожидаемый объем данных, count количество байт, фактически переданных пользовательской программе. Флаги (flags) могут быть установлены таким образом, что поступившее сообщение после чтения и анализа его содержимого не будет удалено из очереди, или настроены на получение данных out-of-band. В дейтаграммных версиях указанных функций, sendto и recvfrom, в качестве дополнительных параметров указываются адреса. После выполнения подключения к гнездам потокового типа процессы могут вместо функций send и recv использовать функции read и write. Таким образом, согласовав тип протокола, серверы могли бы порождать процессы, работающие только с функциями read и write, словно имеют дело с обычными файлами.
Функция shutdown закрывает гнездовую связь: shutdown(sd,mode)
где mode указывает, какой из сторон (посылающей, принимающей или обеим вместе) отныне запрещено участие в процессе передачи данных. Функция сообщает используемому протоколу о завершении сеанса сетевого взаимодействия, оставляя, тем не менее, дескрипторы гнезд в неприкосновенности. Освобождается дескриптор гнезда только в результате выполнения функции close.
Системная функция getsockname получает имя гнездовой связи, установленной ранее с помощью функции bind: getsockname(sd,name,length);
Функции getsockopt и setsockopt получают и устанавливают значения различных связанных с гнездом параметров в соответствии с типом домена и протокола.
Рассмотрим обслуживающую программу, представленную на Рисунке 11.20. Процесс создает в домене "UNIX system" гнездо потокового типа и присваивает ему имя sockname. Затем с помощью функции listen устанавливается длина очереди поступающих сообщений и начинается цикл ожидания поступления запросов. Функция accept приостанавливает свое выполнение до тех пор, пока протоколом не будет зарегистрирован запрос на подключение к гнезду с означенным именем; после этого функция завершается, возвращая поступившему запросу новый дескриптор гнезда. Процесс-сервер порождает потомка, через которого будет поддерживаться связь с процессом-клиентом; родитель и потомок при этом закрывают свои дескрипторы, чтобы они не становились помехой для коммуникационного траффика другого процесса. Процесс-потомок ведет разговор с клиентом и завершается после выхода из функции read. Процесс-сервер возвращается к началу цикла и ждет поступления следующего запроса на подключение.
|
#include <sys/types.h> #include <sys/socket.h> main() { int sd,ns; char buf[256]; struct sockaddr sockaddr; int fromlen; sd = socket(AF_UNIX,SOCK_STREAM,0); /* имя гнезда - не может включать пустой символ */ bind(sd,"sockname",sizeof("sockname") - 1); listen(sd,1); for (;;) { ns = accept(sd,&sockaddr,&fromlen); if (fork() == 0) { /* потомок */ close(sd); read(ns,buf,sizeof(buf)); printf("сервер читает '%s'\n",buf); exit(); } close(ns); } } |
Рисунок 11.20. Процесс-сервер в домене "UNIX system"
|
#include <sys/types.h> #include <sys/socket.h> main() { int sd,ns; char buf[256]; struct sockaddr sockaddr; int fromlen; sd = socket(AF_UNIX,SOCK_STREAM,0); /* имя в запросе на подключение не может включать /* пустой символ */ if (connect(sd,"sockname",sizeof("sockname") - 1) == -1) exit(); write(sd,"hi guy",6); } |
На показан пример процесса-клиента, ведущего общение с сервером. Клиент создает гнездо в том же домене, что и сервер, и посылает запрос на подключение к гнезду с именем sockname. В результате подключения процесс-клиент получает виртуальный канал связи с сервером. В рассматриваемом примере клиент передает одно сообщение и завершается.
Если сервер обслуживает процессы в сети, указание о том, что гнездо принадлежит домену "Internet", можно сделать следующим образом: socket(AF_INET,SOCK_STREAM,0);
и связаться с сетевым адресом, полученным от сервера. В системе BSD имеются библиотечные функции, выполняющие эти действия. Второй параметр вызываемой клиентом функции connect содержит адресную информацию, необходимую для идентификации машины в сети (или адреса маршрутов посылки сообщений через промежуточные машины), а также дополнительную информацию, идентифицирующую приемное гнездо машины-адресата. Если серверу нужно одновременно следить за состоянием сети и выполнением локальных процессов, он использует два гнезда и с помощью функции select определяет, с каким клиентом устанавливается связь в данный момент.
Comments:
Copyright ©
Группы процессов
Несмотря на то, что в системе UNIX процессы идентифицируются уникальным кодом (PID), системе иногда приходится использовать для идентификации процессов номер "группы", в которую они входят. Например, процессы, имеющие общего предка в лице регистрационного shell'а, взаимосвязаны, и поэтому когда пользователь нажимает клавиши "delete" или "break", или когда терминальная линия "зависает", все эти процессы получают соответствующие сигналы. Ядро использует код группы процессов для идентификации группы взаимосвязанных процессов, которые при наступлении определенных событий должны получать общий сигнал. Код группы запоминается в таблице процессов; процессы из одной группы имеют один и тот же код группы.
Для того, чтобы присвоить коду группы процессов начальное значение, приравняв его коду идентификации процесса, следует воспользоваться системной функцией setpgrp. Синтаксис вызова функции: grp = setpgrp();
где grp - новый код группы процессов. При выполнении функции fork процесс-потомок наследует код группы своего родителя. Использование функции setpgrp при назначении для процесса операторского терминала имеет важные особенности, на которые стоит обратить внимание (см. ).
ИСТОРИЯ
В 1965 году фирма Bell Telephone Laboratories, объединив свои усилия с компанией General Electric и проектом MAC Массачусетского технологического института, приступили к разработке новой операционной системы, получившей название Multics [Organick 72]. Перед системой Multics были поставлены задачи - обеспечить одновременный доступ к ресурсам ЭВМ большого количества пользователей, обеспечить достаточную скорость вычислений и хранение данных и дать возможность пользователям в случае необходимости совместно использовать данные. Многие разработчики, впоследствии принявшие участие в создании ранних редакций системы UNIX, участвовали в работе над системой Multics в фирме Bell Laboratories. Хотя первая версия системы Multics и была запущена в 1969 году на ЭВМ GE 645, она не обеспечивала выполнение главных вычислительных задач, для решения которых она предназначалась, и не было даже ясно, когда цели разработки будут достигнуты. Поэтому фирма Bell Laboratories прекратила свое участие в проекте.
По окончании работы над проектом Multics сотрудники Исследовательского центра по информатике фирмы Bell Laboratories остались без "достаточно интерактивного вычислительного средства" [Ritchie 84a]. Пытаясь усовершенствовать среду программирования, Кен Томпсон, Дэннис Ричи и другие набросали на бумаге проект файловой системы, получивший позднее дальнейшее развитие в ранней версии файловой системы UNIX. Томпсоном были написаны программы, имитирующие поведение предложенной файловой системы в режиме подкачки данных по запросу, им было даже создано простейшее ядро операционной системы для ЭВМ GE 645. В то же время он написал на Фортране игровую программу "Space Travel" ("Космическое путешествие") для системы GECOS (Honeywell 635), но программа не смогла удовлетворить пользователей, поскольку управлять "космическим кораблем" оказалось сложно, кроме того, при загрузке программа занимала много места. Позже Томпсон обнаружил малоиспользуемый компьютер PDP-7, оснащенный хорошим графическим дисплеем и имеющий дешевое машинное время. Создавая программу "Космическое путешествие" для PDP-7, Томпсон получил возможность изучить машину, однако условия разработки программ потребовали использования кросс-ассемблера для трансляции программы на машине с системой GECOS и использования перфоленты для ввода в PDP-7. Для того, чтобы улучшить условия разработки, Томпсон и Ричи выполнили на PDP-7 свой проект системы, включивший первую версию файловой системы UNIX, подсистему управления процессами и небольшой набор утилит. В конце концов, новая система больше не нуждалась в поддержке со стороны системы GECOS в качестве операционной среды разработки и могла поддерживать себя сама. Новая система получила название UNIX, по сходству с Multics его придумал еще один сотрудник Исследовательского центра по информатике Брайан Керниган.
Несмотря на то, что эта ранняя версия системы UNIX уже была многообещающей, она не могла реализовать свой потенциал до тех пор, пока не получила применение в реальном проекте. Так, для того, чтобы обеспечить функционирование системы обработки текстов для патентного отдела фирмы Bell Laboratories, в 1971 году система UNIX была перенесена на ЭВМ PDP-11. Система отличалась небольшим объемом: 16 Кбайт для системы, 8 Кбайт для программ пользователей, обслуживала диск объемом 512 Кбайт и отводила под каждый файл не более 64 Кбайт. После своего первого успеха Томпсон собрался было написать для новой системы транслятор с Фортрана, но вместо этого занялся языком Би (B), предшественником которого явился язык BCPL [Richards 69]. Би был интерпретируемым языком со всеми недостатками, присущими подобным языкам, поэтому Ричи переделал его в новую разновидность, получившую название Си (C) и разрешающую генерировать машинный код, объявлять типы данных и определять структуру данных. В 1973 году система была написана заново на Си, это был шаг, неслыханный для того времени, но имевший огромный резонанс среди сторонних пользователей. Количество машин фирмы Bell Laboratories, на которых была инсталлирована система, возросло до 25, в результате чего была создана группа по системному сопровождению UNIX внутри фирмы.
В то время корпорация AT&T не могла заниматься продажей компьютерных продуктов в связи с соответствующим соглашением, подписанным ею с федеральным правительством в 1956 году, и распространяла систему UNIX среди университетов, которым она была нужна в учебных целях. Следуя букве соглашения, корпорация AT&T не рекламировала, не продавала и не сопровождала систему. Несмотря на это, популярность системы устойчиво росла. В 1974 году Томпсон и Ричи опубликовали статью, описывающую систему UNIX, в журнале Communications of the ACM [Thompson 74], что дало еще один импульс к распространению системы. К 1977 году количество машин, на которых функционировала система UNIX, увеличилось до 500, при чем 125 из них работали в университетах. Система UNIX завоевала популярность среди телефонных компаний, поскольку обеспечивала хорошие условия для разработки программ, обслуживала работу в сети в режиме диалога и работу в реальном масштабе времени (с помощью системы MERT [Lycklama 78a]). Помимо университетов, лицензии на систему UNIX были переданы коммерческим организациям. В 1977 году корпорация Interactive Systems стала первой организацией, получившей права на перепродажу системы UNIX с надбавкой к цене за дополнительные услуги , которые заключались в адаптации системы к функционированию в автоматизированных системах управления учрежденческой деятельностью. 1977 год также был отмечен "переносом" системы UNIX на машину, отличную от PDP (благодаря чему стал возможен запуск системы на другой машине без изменений или с небольшими изменениями), а именно на Interdata 8/32.
С ростом популярности микропроцессоров другие компании стали переносить систему UNIX на новые машины, однако ее простота и ясность побудили многих разработчиков к самостоятельному развитию системы, в результате чего было создано несколько вариантов базисной системы. За период между 1977 и 1982 годом фирма Bell Laboratories объединила несколько вариантов, разработанных в корпорации AT&T, в один, получивший коммерческое название UNIX версия III. В дальнейшем фирма Bell Laboratories добавила в версию III несколько новых особенностей, назвав новый продукт UNIX версия V , и эта версия стала официально распространяться корпорацией AT&T с января 1983 года. В то же время сотрудники Калифорнийского университета в Бэркли разработали вариант системы UNIX, получивший название BSD 4.3 для машин серии VAX и отличающийся некоторыми новыми, интересными особенностями. Основное внимание в этой книге концентрируется на описании системы UNIX версии V, однако время от времени мы будем касаться и особенностей системы BSD.
К началу 1984 года система UNIX была уже инсталлирована приблизительно на 100000 машин по всему миру, при чем на машинах с широким диапазоном вычислительных возможностей - от микропроцессоров до больших ЭВМ - и разных изготовителей. Ни о какой другой операционной системе нельзя было бы сказать того же. Популярность и успех системы UNIX объяснялись несколькими причинами:
Система написана на языке высокого уровня, благодаря чему ее легко читать, понимать, изменять и переносить на другие машины. По оценкам, сделанным Ричи, первый вариант системы на Си имел на 20-40 % больший объем и работал медленнее по сравнению с вариантом на ассемблере, однако преимущества использования языка высокого уровня намного перевешивают недостатки (см. [Ritchie 78b], стр. 1965). Наличие довольно простого пользовательского интерфейса, в котором имеется возможность предоставлять все необходимые пользователю услуги. Наличие элементарных средств, позволяющих создавать сложные программы из более простых. Наличие иерархической файловой системы, легкой в сопровождении и эффективной в работе. Обеспечение согласования форматов в файлах, работа с последовательным потоком байтов, благодаря чему облегчается чтение прикладных программ. Наличие простого, последовательного интерфейса с периферийными устройствами. Система является многопользовательской, многозадачной; каждый пользователь может одновременно выполнять несколько процессов.
Архитектура машины скрыта от пользователя, благодаря этому облегчен процесс написания программ, работающих на различных конфигурациях аппаратных средств.
Простота и последовательность вообще отличают систему UNIX и объясняют большинство из вышеприведенных доводов в ее пользу.
Хотя операционная система и большинство команд написаны на Си, система UNIX поддерживает ряд других языков, таких как Фортран, Бейсик, Паскаль, Ада, Кобол, Лисп и Пролог. Система UNIX может поддерживать любой язык программирования, для которого имеется компилятор или интерпретатор, и обеспечивать системный интерфейс, устанавливающий соответствие между пользовательскими запросами к операционной системе и набором запросов, принятых в UNIX.
(*) Организации, получившие права на перепродажу с надбавкой к цене за дополнительные услуги, оснащают вычислительную систему прикладными программами, касающимися конкретных областей применения, стремясь удовлетворить требования рынка. Такие организации чаще продают прикладные программы, нежели операционные системы, под управлением которых эти программы работают.
(**) А что же версия IV? Модификация внутреннего варианта системы получила название "версия V".
Comments:
Copyright ©
Изменение размера области
Процесс может расширять или сужать свое виртуальное адресное пространство с помощью функции sbrk. Точно так же и стек процесса расширяется автоматически (то есть для этого процессу не нужно явно обращаться к определенной функции) в соответствии с глубиной вложенности обращений к подпрограммам. Изменение размера области производится внутри ядра по алгоритму growreg (). При расширении области ядро проверяет, не будут ли виртуальные адреса расширяемой области пересекаться с адресами какой-нибудь другой области и не повлечет ли расширение области за собой выход процесса за пределы максимально-допустимого виртуального пространства памяти. Ядро никогда не использует алгоритм growreg для увеличения размера разделяемой области, уже присоединенной к нескольким процессам; поэтому оно не беспокоится о том, не приведет ли увеличение размера области для одного процесса к превышению другим процессом системного ограничения, накладываемого на размер процесса. При работе с существующей областью ядро использует алгоритм growreg в двух случаях: выполняя функцию sbrk по отношению к области данных процесса и реализуя автоматическое увеличение стека задачи. Обе эти области (данных и стека) частного типа. Области команд и разделяемой памяти после инициализации не могут расширяться. Этот момент будет пояснен в следующей главе.
Рисунок 6.20. Пример присоединения существующей области команд
Чтобы разместить расширенную память, ядро выделяет новые таблицы страниц (или расширяет существующие) или отводит дополнительную физическую память в тех системах, где не поддерживается подкачка страниц по обращению. При выделении дополнительной физической памяти ядро проверяет ее наличие перед выполнением алгоритма growreg; если же памяти больше нет, ядро прибегает к другим средствам увеличения размера области (). Если процесс сокращает размер области, ядро просто освобождает память, отведенную под область. Во всех этих случаях ядро переопределяет размеры процесса и области и переустанавливает значения полей записи частной таблицы областей процесса и регистров управления памятью (так, чтобы они согласовались с новым отображением памяти).
Предположим, например, что область стека процесса начинается с виртуального адреса 128К и имеет размер 6 Кбайт и что ядру нужно расширить эту область на 1 Кбайт (1 страницу). Если размер процесса позволяет это делать и если виртуальные адреса в диапазоне от 134К до 135К - 1 не принадлежат какой-либо области, ранее присоединенной к процессу, ядро увеличивает размер стека. При этом ядро расширяет таблицу страниц, выделяет новую страницу памяти и инициализирует новую запись таблицы. Этот случай проиллюстрирован с помощью .
ИЗМЕНЕНИЕ РАЗМЕРА ПРОЦЕССА
С помощью системной функции brk процесс может увеличивать и уменьшать размер области данных. Синтаксис вызова функции: brk(endds);
где endds - старший виртуальный адрес области данных процесса (адрес верхней границы). С другой стороны, пользователь может обратиться к функции следующим образом: oldendds = sbrk(increment);
где oldendds - текущий адрес верхней границы области, increment - число байт, на которое изменяется значение oldendds в результате выполнения функции. Sbrk - это имя стандартной библиотечной подпрограммы на Си, вызывающей функцию brk. Если размер области данных процесса в результате выполнения функции увеличивается, вновь выделяемое пространство имеет виртуальные адреса, смежные с адресами увеличиваемой области; таким образом, виртуальное адресное пространство процесса расширяется. При этом ядро проверяет, не превышает ли новый размер процесса максимально-допустимое значение, принятое для него в системе, а также не накладывается ли новая область данных процесса на виртуальное адресное пространство, отведенное ранее для других целей (). Если все в порядке, ядро запускает алгоритм growreg, присоединяя к области данных внешнюю память (например, таблицы страниц) и увеличивая значение поля, описывающего размер процесса. В системе с замещением страниц ядро также отводит под новую область пространство основной памяти и обнуляет его содержимое; если свободной памяти нет, ядро освобождает память путем выгрузки процесса (более подробно об этом мы поговорим в ). Если с помощью функции brk процесс уменьшает размер области данных, ядро освобождает часть ранее выделенного адресного пространства; когда процесс попытается обратиться к данным по виртуальным адресам, принадлежащим освобожденному пространству, он столкнется с ошибкой адресации.
| алгоритм brk входная информация: новый адрес верхней границы области данных выходная информация: старый адрес верхней границы области данных { заблокировать область данных процесса; если (размер области увеличивается) если (новый размер области имеет недопустимое зна- чение) { снять блокировку с области; вернуть (ошибку); } изменить размер области (алгоритм growreg); обнулить содержимое присоединяемого пространства; снять блокировку с области данных; } |
Рисунок 7.26. Алгоритм выполнения функции brk
На приведен пример программы, использующей функцию brk, и выходные данные, полученные в результате ее прогона на машине AT&T 3B20. Вызвав функцию signal и распорядившись принимать сигналы о нарушении сегментации (segmentation violation), процесс обращается к подпрограмме sbrk и выводит на печать первоначальное значение адреса верхней границы области данных. Затем в цикле, используя счетчик символов, процесс заполняет область данных до тех пор, пока не обратится к адресу, расположенному за пределами области, тем самым давая повод для сигнала о нарушении сегментации. Получив сигнал, функция обработки сигнала вызывает подпрограмму sbrk для того, чтобы присоединить к области дополнительно 256 байт памяти; процесс продолжается с точки прерывания, заполняя информацией вновь выделенное пространство памяти и т.д. На машинах со страничной организацией памяти, таких как 3B20, наблюдается интересный феномен. Страница является наименьшей единицей памяти, с которой работают механизмы аппаратной защиты, поэтому аппаратные средства не в состоянии установить ошибку в граничной ситуации, когда процесс пытается записать информацию по адресам, превышающим верхнюю границу области данных, но принадлежащим т.н. "полулегальной" странице (странице, не полностью занятой областью данных процесса). Это видно из результатов выполнения программы, выведенных на печать (): первый раз подпрограмма sbrk возвращает значение 140924, то есть адрес, не дотягивающий 388 байт до конца страницы, которая на машине 3B20 имеет размер 2 Кбайта. Однако процесс получит ошибку только в том случае, если обратится к следующей странице памяти, то есть к любому адресу, начиная с 141312. Функция обработки сигнала прибавляет к адресу верхней границы области 256, делая его равным 141180 и, таким образом, оставляя его в пределах текущей страницы. Следовательно, процесс тут же снова получит ошибку, выдав на печать адрес 141312. Исполнив подпрограмму sbrk еще раз, ядро выделяет под данные процесса новую страницу памяти, так что процесс получает возможность адресовать дополнительно 2 Кбайта памяти, до адреса 143360, даже если верхняя граница области располагается ниже. Получив ошибку, процесс должен будет восемь раз обратиться к подпрограмме sbrk, прежде чем сможет продолжить выполнение основной программы. Таким образом, процесс может иногда выходить за официальную верхнюю границу области данных, хотя это и нежелательный момент в практике программирования.
Когда стек задачи переполняется, ядро автоматически увеличивает его размер, выполняя алгоритм, похожий на алгоритм функции brk. Первоначально стек задачи имеет размер, достаточный для хранения параметров функции exec, однако при выполнении процесса этот стек может переполниться. Переполнение стека приводит к ошибке адресации, свидетельствующей о попытке процесса обратиться к ячейке памяти за пределами отведенного адресного пространства. Ядро устанавливает причину возникновения ошибки, сравнивая текущее значение указателя вершины стека с размером области стека. При расширении области стека ядро использует точно такой же механизм, что и для области данных. На выходе из прерывания процесс имеет область стека необходимого для продолжения работы размера.
|
#include <signal.h> char *cp; int callno; main() { char *sbrk(); extern catcher(); signal(SIGSEGV,catcher); cp = sbrk(0); printf("original brk value %u\n",cp); for (;;) *cp++ = 1; } catcher(signo); int signo; { callno++; printf("caught sig %d %dth call at addr %u\n", signo,callno,cp); sbrk(256); signal(SIGSEGV,catcher); } |
| original brk value 140924 caught sig 11 1th call at addr 141312 caught sig 11 2th call at addr 141312 caught sig 11 3th call at addr 143360 ...(тот же адрес печатается до 10-го вызова подпрограммы sbrk) caught sig 11 10th call at addr 143360 caught sig 11 11th call at addr 145408 ...(тот же адрес печатается до 18-го вызова подпрограммы sbrk) caught sig 11 18th call at addr 145408 caught sig 11 19th call at addr 145408 - - |
| /* чтение командной строки до символа конца файла */ while (read(stdin,buffer,numchars)) { /* синтаксический разбор командной строки */ if (/* командная строка содержит & */) amper = 1; else amper = 0; /* для команд, не являющихся конструкциями командного языка shell */ if (fork() == 0) { /* переадресация ввода-вывода? */ if (/* переадресация вывода */) { fd = creat(newfile,fmask); close(stdout); dup(fd); close(fd); /* stdout теперь переадресован */ } if (/* используются каналы */) { pipe(fildes); |
Comments:
Copyright ©
Элементы конструкционных блоков
Как уже говорилось ранее, концепция разработки системы UNIX заключалась в построении операционной системы из элементов, которые позволили бы пользователю создавать небольшие программные модули, выступающие в качестве конструкционных блоков при создании более сложных программ. Одним из таких элементов, с которым часто сталкиваются пользователи при работе с командным процессором shell, является возможность переназначения ввода-вывода. Говоря условно, процессы имеют доступ к трем файлам: они читают из файла стандартного ввода, записывают в файл стандартного вывода и выводят сообщения об ошибках в стандартный файл ошибок. Процессы, запускаемые с терминала, обычно используют терминал вместо всех этих трех файлов, однако каждый файл независимо от других может быть "переназначен". Например, команда ls
выводит список всех файлов текущего каталога на устройство (в файл) стандартного вывода, а команда ls > output
переназначает выводной поток со стандартного вывода в файл "output" в текущем каталоге, используя вышеупомянутый системный вызов creat. Подобным же образом, команда mail mjb < letter
открывает (с помощью системного вызова open) файл "letter" в качестве файла стандартного ввода и пересылает его содержимое пользователю с именем "mjb". Процессы могут переназначать одновременно и ввод, и вывод, как, например, в командной строке: nroff -mm < doc1 > doc1.out 2> errors
где программа форматирования nroff читает вводной файл doc1, в качестве файла стандартного вывода задает файл doc1.out и выводит сообщения об ошибках в файл errors ("2>" означает переназначение вывода, предназначавшегося для файла с дескриптором 2, который соответствует стандартному файлу ошибок). Программы ls, mail и nroff не знают, какие файлы выбраны в качестве файлов стандартного ввода, стандартного вывода и записи сообщений об ошибках; командный процессор shell сам распознает символы "<", ">" и "2>" и назначает в соответствии с их указанием файлы для стандартного ввода, стандартного вывода и записи сообщений об ошибках непосредственно перед запуском процессов.
Вторым конструкционным элементом является канал, механизм, обеспечивающий информационный обмен между процессами, выполнение которых связано с операциями чтения и записи. Процессы могут переназначать выводной поток со стандартного вывода на канал для чтения с него другими процессами, переназначившими на канал свой стандартный ввод. Данные, посылаемые в канал первыми процессами, являются входными для вторых процессов. Вторые процессы так же могут переназначить свой выводной поток и так далее, в зависимости от пожеланий программиста. И снова, так же как и в вышеуказанном случае, процессам нет необходимости знать, какого типа файл используется в качестве файла стандартного вывода; их выполнение не зависит от того, будет ли файлом стандартного вывода обычный файл, канал или устройство. В процессе построения больших и сложных программ из конструкционных элементов меньшего размера программисты часто используют каналы и переназначение ввода-вывода при сборке и соединении отдельных частей. И действительно, такой стиль программирования находит поддержку в системе, благодаря чему новые программы могут работать вместе с существующими программами.
Например, программа grep производит поиск контекста в наборе файлов (являющихся параметрами программы) по следующему образцу: grep main a.c b.c c.c
где "main" - подстрока, поиск которой производится в файлах a.c, b.c и c.c с выдачей в файл стандартного вывода тех строк, в которых она содержится. Содержимое выводного файла может быть следующим: a.c: main(argc,argv) c.c: /* here is the main loop in the program */ c.c: main()
Программа wc с необязательным параметром -l подсчитывает число строк в файле стандартного ввода. Командная строка grep main a.c b.c c.c | wc -l
вызовет подсчет числа строк в указанных файлах, где будет обнаружена подстрока "main"; выводной поток команды grep поступит непосредственно на вход команды wc. Для предыдущего примера результат будет такой: 3
Использование каналов зачастую делает ненужным создание временных файлов.
(****) Каталог "/bin" содержит большинство необходимых команд и обычно входит в число каталогов, в которых ведет поиск командный процессор shell.
Comments:
Copyright ©
КАНАЛЫ
Каналы позволяют передавать данные между процессами в порядке поступления ("первым пришел - первым вышел"), а также синхронизировать выполнение процессов. Их использование дает процессам возможность взаимодействовать между собой, пусть даже не известно, какие процессы находятся на другом конце канала. Традиционная реализация каналов использует файловую систему для хранения данных. Различают два вида каналов: поименованные каналы и, за отсутствием лучшего термина, непоименованные каналы, которые идентичны между собой во всем, кроме способа первоначального обращения к ним процессов. Для поименованных каналов процессы используют системную функцию open, а системную функцию pipe - для создания непоименованного канала. Впоследствии, при работе с каналами процессы пользуются обычными системными функциями для файлов, такими как read, write и close. Только связанные между собой процессы, являющиеся потомками того процесса, который вызвал функцию pipe, могут разделять доступ к непоименованным каналам. Например (), если процесс B создает канал и порождает процессы D и E, эти три процесса разделяют между собой доступ к каналу, в отличие от процессов A и C. Однако, все процессы могут обращаться к поименованному каналу независимо от взаимоотношений между ними, при условии наличия обычных прав доступа к файлу. Поскольку непоименованные каналы встречаются чаще, они будут рассмотрены первыми.
КАТАЛОГИ
Из главы 1 напомним, что каталоги являются файлами, из которых строится иерархическая структура файловой системы; они играют важную роль в превращении имени файла в номер индекса. Каталог - это файл, содержимым которого является набор записей, состоящих из номера индекса и имени файла, включенного в каталог. Составное имя - это строка символов, завершающаяся пустым символом и разделяемая наклонной чертой ("/") на несколько компонент. Каждая компонента, кроме последней, должна быть именем каталога, но последняя компонента может быть именем файла, не являющегося каталогом. В версии V системы UNIX длина каждой компоненты ограничивается 14 символами; таким образом, вместе с 2 байтами, отводимыми на номер индекса, размер записи каталога составляет 16 байт.
| 0 | 83 | . |
| 16 | 2 | .. |
| 32 | 1798 | init |
| 48 | 1276 | fsck |
| 64 | 85 | clri |
| 80 | 1268 | motd |
| 96 | 1799 | mount |
| 112 | 88 | mknod |
| 128 | 2114 | passwd |
| 144 | 1717 | umount |
| 160 | 1851 | checklist |
| 176 | 92 | fsdbld |
| 192 | 84 | config |
| 208 | 1432 | getty |
| 224 | 0 | crash |
| 240 | 95 | mkfs |
| 256 | 188 | inittab |
Рисунок 4.10. Формат каталога /etc
На показан формат каталога "etc". В каждом каталоге имеются файлы, в качестве имен которых указаны точка и две точки ("." и "..") и номера индексов у которых совпадают с номерами индексов данного каталога и родительского каталога, соответственно. Номер индекса для файла "." в каталоге "/etc" имеет адрес со смещением 0 и значение 83. Номер индекса для файла ".." имеет адрес со смещением 16 от начала каталога и значение 2. Записи в каталоге могут быть пустыми, при этом номер индекса равен 0. Например, запись с адресом 224 в каталоге "/etc" пустая, несмотря на то, что она когда-то содержала точку входа для файла с именем "crash". Программа mkfs инициализирует файловую систему таким образом, что номера индексов для файлов "." и ".." в корневом каталоге совпадают с номером корневого индекса файловой системы.
Ядро хранит данные в каталоге так же, как оно это делает в файле обычного типа, используя индексную структуру и блоки с уровнями прямой и косвенной адресации. Процессы могут читать данные из каталогов таким же образом, как они читают обычные файлы, однако исключительное право записи в каталог резервируется ядром, благодаря чему обеспечивается правильность структуры каталога. Права доступа к каталогу имеют следующий смысл: право чтения дает процессам возможность читать данные из каталога; право записи позволяет процессу создавать новые записи в каталоге или удалять старые (с помощью системных операций creat, mknod, link и unlink), в результате чего изменяется содержимое каталога; право исполнения позволяет процессу производить поиск в каталоге по имени файла (поскольку "исполнять" каталог бессмысленно). На примере показана разница между чтением и поиском в каталоге.
Comments:
Copyright ©
КОД ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ ПРОЦЕССА
Ядро связывает с процессом два кода идентификации пользователя, не зависящих от кода идентификации процесса: реальный (действительный) код идентификации пользователя и исполнительный код или setuid (от "set user ID" - установить код идентификации пользователя, под которым процесс будет исполняться). Реальный код идентифицирует пользователя, несущего ответственность за выполняющийся процесс. Исполнительный код используется для установки прав собственности на вновь создаваемые файлы, для проверки прав доступа к файлу и разрешения на посылку сигналов процессам через функцию kill. Процессы могут изменять исполнительный код, запуская с помощью функции exec программу setuid или запуская функцию setuid в явном виде.
Программа setuid представляет собой исполняемый файл, имеющий в поле режима доступа установленный бит setuid. Когда процесс запускает программу setuid на выполнение, ядро записывает в поля, содержащие реальные коды идентификации, в таблице процессов и в пространстве процесса код идентификации владельца файла. Чтобы как-то различать эти поля, назовем одно из них, которое хранится в таблице процессов, сохраненным кодом идентификации пользователя. Рассмотрим пример, иллюстрирующий разницу в содержимом этих полей.
Синтаксис вызова системной функции setuid: setuid(uid)
где uid - новый код идентификации пользователя. Результат выполнения функции зависит от текущего значения реального кода идентификации. Если реальный код идентификации пользователя процесса, вызывающего функцию, указывает на суперпользователя, ядро записывает значение uid в поля, хранящие реальный и исполнительный коды идентификации, в таблице процессов и в пространстве процесса. Если это не так, ядро записывает uid в качестве значения исполнительного кода идентификации в пространстве процесса и то только в том случае, если значение uid равно значению реального кода или значению сохраненного кода. В противном случае функция возвращает вызывающему процессу ошибку. Процесс наследует реальный и исполнительный коды идентификации у своего родителя (в результате выполнения функции fork) и сохраняет их значения после вызова функции exec.
На приведена программа, демонстрирующая использование функции setuid. Предположим, что исполняемый файл, полученный в результате трансляции исходного текста программы, имеет владельца с именем "maury" (код идентификации 8319) и установленный бит setuid; право его исполнения предоставлено всем пользователям. Допустим также, что пользователи "mjb" (код идентификации 5088) и "maury" являются владельцами файлов с теми же именами, каждый из которых доступен только для чтения и только своему владельцу. Во время исполнения программы пользователю "mjb" выводится следующая информация: uid 5088 euid 8319 fdmjb -1 fdmaury 3 after setuid(5088): uid 5088 euid 5088 fdmjb 4 fdmaury -1 after setuid(8319): uid 5088 euid 8319
Системные функции getuid и geteuid возвращают значения реального и исполнительного кодов идентификации пользователей процесса, для пользователя "mjb" это, соответственно, 5088 и 8319. Поэтому процесс не может открыть файл "mjb" (ибо он имеет исполнительный код идентификации пользователя (8319), не разрешающий производить чтение файла), но может открыть файл "maury". После вызова функции setuid, в результате выполнения которой в поле исполнительного кода идентификации пользователя ("mjb") заносится значение реального кода идентификации, на печать выводятся значения и того, и другого кода идентификации пользователя "mjb": оба равны 5088. Теперь процесс может открыть файл "mjb", поскольку он исполняется под кодом идентификации пользователя, имеющего право на чтение из файла, но не может открыть файл "maury". Наконец, после занесения в поле исполнительного кода идентификации значения, сохраненного функцией setuid (8319), на печать снова выводятся значения 5088 и 8319. Мы показали, таким образом, как с помощью программы setuid процесс может изменять значение кода идентификации пользователя, под которым он исполняется.
|
#include <fcntl.h> main() { int uid,euid,fdmjb,fdmaury; uid = getuid(); /* получить реальный UID */ euid = geteuid(); /* получить исполнительный UID */ printf("uid %d euid %d\n",uid,euid); fdmjb = open("mjb",O_RDONLY); fdmaury = open("maury",O_RDONLY); printf("fdmjb %d fdmaury %d\n",fdmjb,fdmaury); setuid(uid); printf("after setuid(%d): uid %d euid %d\n",uid, getuid(),geteuid()); fdmjb = open("mjb",O_RDONLY); fdmaury = open("maury",O_RDONLY); printf("fdmjb %d fdmaury %d\n",fdmjb,fdmaury); setuid(uid); printf("after setuid(%d): uid %d euid %d\n",euid, getuid(),geteuid()); } |
Рисунок 7.25. Пример выполнения программы setuid
Во время выполнения программы пользователем "maury" на печать выводится следующая информация: uid 8319 euid 8319 fdmjb -1 fdmaury 3 after setuid(8319): uid 8319 euid 8319 fdmjb -1 fdmaury 4 after setuid(8319): uid 8319 euid 8319
Реальный и исполнительный коды идентификации пользователя во время выполнения программы остаются равны 8319: процесс может открыть файл "maury", но не может открыть файл "mjb". Исполнительный код, хранящийся в пространстве процесса, занесен туда в результате последнего исполнения функции или программы setuid; только его значением определяются права доступа процесса к файлу. С помощью функции setuid исполнительному коду может быть присвоено значение сохраненного кода (из таблицы процессов), т.е. то значение, которое исполнительный код имел в самом начале.
Примером программы, использующей вызов системной функции setuid, может служить программа регистрации пользователей в системе (login). Параметром функции setuid при этом является код идентификации суперпользователя, таким образом, программа login исполняется под кодом суперпользователя из корня системы. Она запрашивает у пользователя различную информацию, например, имя и пароль, и если эта информация принимается системой, программа запускает функцию setuid, чтобы установить значения реального и исполнительного кодов идентификации в соответствии с информацией, поступившей от пользователя (при этом используются данные файла "/etc/passwd"). В заключение программа login инициирует запуск командного процессора shell, который будет исполняться под указанными пользовательскими кодами идентификации.
Примером setuid-программы является программа, реализующая команду mkdir. В уже говорилось о том, что создать каталог может только процесс, выполняющийся под управлением суперпользователя. Для того, чтобы предоставить возможность создания каталогов простым пользователям, команда mkdir была выполнена в виде setuid-программы, принадлежащей корню системы и имеющей права суперпользователя. На время исполнения команды mkdir процесс получает права суперпользователя, создает каталог, используя функцию mknod, и предоставляет права собственности и доступа к каталогу истинному пользователю процесса.
Comments:
Copyright ©
КОМАНДНЫЙ ПРОЦЕССОР SHELL
Теперь у нас есть достаточно материала, чтобы перейти к объяснению принципов работы командного процессора shell. Сам командный процессор намного сложнее, чем то, что мы о нем здесь будем излагать, однако взаимодействие процессов мы уже можем рассмотреть на примере реальной программы. На приведен фрагмент основного цикла программы shell, демонстрирующий асинхронное выполнение процессов, переназначение вывода и использование каналов.
Shell считывает командную строку из файла стандартного ввода и интерпретирует ее в соответствии с установленным набором правил. Дескрипторы файлов стандартного ввода и стандартного вывода, используемые регистрационным shell'ом, как правило, указывают на терминал, с которого пользователь регистрируется в системе (см. ). Если shell узнает во введенной строке конструкцию собственного командного языка (например, одну из команд cd, for, while и т.п.), он исполняет команду своими силами, не прибегая к созданию новых процессов; в противном случае команда интерпретируется как имя исполняемого файла.
Командные строки простейшего вида содержат имя программы и несколько параметров, например: who grep -n include *.c ls -l
Shell "ветвится" (fork) и порождает новый процесс, который и запускает программу, указанную пользователем в командной строке. Родительский процесс (shell) дожидается завершения потомка и повторяет цикл считывания следующей команды.
| if (fork() == 0) { /* первая компонента командной строки */ close(stdout); dup(fildes[1]); close(fildes[1]); close(fildes[0]); /* стандартный вывод направляется в ка- нал */ /* команду исполняет порожденный про- цесс */ execlp(command1,command1,0); } /* вторая компонента командной строки */ close(stdin); dup(fildes[0]); close(fildes[0]); close(fildes[1]); /* стандартный ввод будет производиться из канала */ } execve(command2,command2,0); } /* с этого места продолжается выполнение родительского * процесса... * процесс-родитель ждет завершения выполнения потомка, * если это вытекает из введенной строки * / if (amper == 0) retid = wait(&status); } |
Рисунок 7.28. Основной цикл программы shell (продолжение)
Если процесс запускается асинхронно (на фоне основной программы), как в следующем примере nroff -mm bigdocument &
shell анализирует наличие символа амперсанд (&) и заносит результат проверки во внутреннюю переменную amper. В конце основного цикла shell обращается к этой переменной и, если обнаруживает в ней признак наличия символа, не выполняет функцию wait, а тут же повторяет цикл считывания следующей команды.
Из рисунка видно, что процесс-потомок по завершении функции fork получает доступ к командной строке, принятой shell'ом. Для того, чтобы переадресовать стандартный вывод в файл, как в следующем примере nroff -mm bigdocument > output
процесс-потомок создает файл вывода с указанным в командной строке именем; если файл не удается создать (например, не разрешен доступ к каталогу), процесс-потомок тут же завершается. В противном случае процесс-потомок закрывает старый файл стандартного вывода и переназначает с помощью функции dup дескриптор этого файла новому файлу. Старый дескриптор созданного файла закрывается и сохраняется для запускаемой программы. Подобным же образом shell переназначает и стандартный ввод и стандартный вывод ошибок.

Рисунок 7.29. Взаимосвязь между процессами, исполняющими командную строку ls -l|wc
Из приведенного текста программы видно, как shell обрабатывает командную строку, используя один канал. Допустим, что командная строка имеет вид: ls -l|wc
После создания родительским процессом нового процесса процесс-потомок создает канал. Затем процесс-потомок создает свое ответвление; он и его потомок обрабатывают по одной компоненте командной строки. "Внучатый" процесс исполняет первую компоненту строки (ls): он собирается вести запись в канал, поэтому он закрывает старый файл стандартного вывода, передает его дескриптор каналу и закрывает старый дескриптор записи в канал, в котором (в дескрипторе) уже нет необходимости. Родитель (wc) "внучатого" процесса (ls) является потомком основного процесса, реализующего программу shell'а (см. ). Этот процесс (wc) закрывает свой файл стандартного ввода и передает его дескриптор каналу, в результате чего канал становится файлом стандартного ввода. Затем закрывается старый и уже не нужный дескриптор чтения из канала и исполняется вторая компонента командной строки. Оба порожденных процесса выполняются асинхронно, причем выход одного процесса поступает на вход другого. Тем временем основной процесс дожидается завершения своего потомка (wc), после чего продолжает свою обычную работу: по завершении процесса, выполняющего команду wc, вся командная строка является обработанной. Shell возвращается в цикл и считывает следующую командную строку.
Comments:
Copyright ©
Конфигурация системы
Задание конфигурации системы это процедура указания администраторами значений параметров, с помощью которых производится настройка системы. Некоторые из параметров указывают размеры таблиц ядра, таких как таблица процессов, таблица индексов и таблица файлов, а также сколько буферов помещается в буферном пуле. С помощью других параметров указывается конфигурация устройств, то есть производятся конкретные указания ядру, какие устройства включаются в данную системную реализацию и их "адрес". Например, в конфигурации может быть указано, что терминальная плата вставлена в соответствующий разъем на аппаратной панели.
Существует три стадии, на которых может быть указана конфигурация устройств. Во-первых, администраторы могут кодировать информацию о конфигурации в файлах, которые транслируются и компонуются во время построения ядра. Информация о конфигурации обычно указывается в простом формате, и программа конфигурации преобразует ее в файл, готовый для трансляции. Во-вторых, администраторы могут указывать информацию о конфигурации после того, как система уже запущена; ядро динамически корректирует внутренние таблицы конфигурации. Наконец, самоидентифицирующиеся устройства дают ядру возможность узнать, какие из устройств включены. Ядро считывает аппаратные ключи для самонастройки. Подробности задания системной конфигурации выходят за пределы этой книги, однако во всех случаях результатом процедуры задания конфигурации является генерация или заполнение таблиц, составляющих основу программ ядра.
Интерфейс "ядро - драйвер" описывается в таблице ключей устройств ввода-вывода блоками и в таблице ключей устройств посимвольного ввода-вывода (). Каждый тип устройства имеет в таблице точки входа, которые при выполнении системных функций адресуют ядро к соответствующему драйверу. Функции open и close, вызываемые файлом устройства, "пропускаются" через таблицы ключей устройств в соответствии с типом файла. Функции mount и umount так же вызывают выполнение процедур открытия и закрытия устройств, но для устройств ввода-вывода блоками. Функции read и write, вызываемые устройствами ввода-вывода блоками и файлами в смонтированных файловых системах, запускают алгоритмы работы с буферным кешем, инициирующие реализацию стратегической процедуры работы с устройствами. Некоторые из драйверов запускают эту процедуру изнутри из процедур чтения и записи. Более подробно взаимодействие с каждым драйвером рассматривается в следующем разделе.
Интерфейс "аппаратура - драйвер" состоит из машинно- зависимых управляющих регистров или команд ввода-вывода для управления устройствами и векторами прерываний: когда происходит прерывание от устройства, система идентифицирует устройство, вызвавшее прерывание, и запускает программу обработки соответствующего прерывания. Очевидно, что "программные устройства", такие как драйвер системы построения профиля ядра () не имеют аппаратного интерфейса, однако программы обработки других прерываний могут обращаться к "обработчику программного прерывания" непосредственно. Например, программа обработки прерывания по таймеру обращается к программе обработки прерывания системы построения профиля ядра.
Администраторы устанавливают специальные файлы устройств командой mknod, в которой указывается тип файла (блочный или символьный), старший и младший номера устройства. Команда mknod запускает выполнение системной функции с тем же именем, создающей файл устройства. Например, в командной строке mknod /dev/tty13 c 2 13
"/dev/tty13" - имя файла устройства, "c" указывает, что тип файла - "символьный специальный" ("b", соответственно, блочный), "2" - старший номер устройства, "13" - младший номер устройства. Старший номер устройства показывает его тип, которому соответствует точка входа в таблице ключей устройств, младший номер устройства - это порядковый номер единицы устройства данного типа. Если процесс открывает специальный блочный файл с именем "/dev/dsk1" и кодом 0, ядро запускает программу gdopen в точке 0 таблицы ключей устройств блочного ввода-вывода (); если процесс читает специальный символьный файл с именем "/dev/mem" и кодом 3, ядро запускает программу mmread в точке 3 таблицы ключей устройств посимвольного ввода-вывода. Программа nulldev - это "пустая" программа, используемая в тех случаях, когда отсутствует необходимость в конкретной функции драйвера. С одним старшим номером устройства может быть связано множество периферийных устройств; младший номер устройства позволяет отличить их одно от другого. Не нужно создавать специальные файлы устройств при каждой загрузке системы; их только нужно корректировать, если изменилась конфигурация системы, например, если к установленной конфигурации были добавлены устройства.

Рисунок 10.1. Точки входа для драйверов
КОНТЕКСТ ПРОЦЕССА
Контекст процесса включает в себя содержимое адресного пространства задачи, выделенного процессу, а также содержимое относящихся к процессу аппаратных регистров и структур данных ядра. С формальной точки зрения, контекст процесса объединяет в себе пользовательский контекст, регистровый контекст и системный контекст . Пользовательский контекст состоит из команд и данных процесса, стека задачи и содержимого совместно используемого пространства памяти в виртуальных адресах процесса. Те части виртуального адресного пространства процесса, которые периодически отсутствуют в оперативной памяти вследствие выгрузки или замещения страниц, также включаются в пользовательский контекст.
Регистровый контекст состоит из следующих компонент:
Счетчика команд, указывающего адрес следующей команды, которую будет выполнять центральный процессор; этот адрес является виртуальным адресом внутри пространства ядра или пространства задачи. Регистра состояния процессора (PS), который указывает аппаратный статус машины по отношению к процессу. Регистр PS, например, обычно содержит подполя, которые указывают, является ли результат последних вычислений нулевым, положительным или отрицательным, переполнен ли регистр с установкой бита переноса и т.д. Операции, влияющие на установку регистра PS, выполняются для отдельного процесса, потому-то в регистре PS и содержится аппаратный статус машины по отношению к процессу. В других имеющих важное значение подполях регистра PS указывается текущий уровень прерывания процессора, а также текущий и предыдущий режимы выполнения процесса (режим ядра/задачи). По значению подполя текущего режима выполнения процесса устанавливается, может ли процесс выполнять привилегированные команды и обращаться к адресному пространству ядра. Указателя вершины стека, в котором содержится адрес следующего элемента стека ядра или стека задачи, в соответствии с режимом выполнения процесса. В зависимости от архитектуры машины указатель вершины стека показывает на следующий свободный элемент стека или на последний используемый элемент. От архитектуры машины также зависит направление увеличения стека (к старшим или младшим адресам), но для нас сейчас эти вопросы несущественны. Регистров общего назначения, в которых содержится информация, сгенерированная процессом во время его выполнения. Чтобы облегчить последующие объяснения, выделим среди них два регистра - регистр 0 и регистр 1 - для дополнительного использования при передаче информации между процессами и ядром.
Системный контекст процесса имеет "статическую часть" (первые три элемента в нижеследующем списке) и "динамическую часть" (последние два элемента). На протяжении всего времени выполнения процесс постоянно располагает одной статической частью системного контекста, но может иметь переменное число динамических частей. Динамическую часть системного контекста можно представить в виде стека, элементами которого являются контекстные уровни, которые помещаются в стек ядром или выталкиваются из стека при наступлении различных событий. Системный контекст включает в себя следующие компоненты:
Запись в таблице процессов, описывающая состояние процесса () и содержащая различную управляющую информацию, к которой ядро всегда может обратиться. Часть адресного пространства задачи, выделенная процессу, где хранится управляющая информация о процессе, доступная только в контексте процесса. Общие управляющие параметры, такие как приоритет процесса, хранятся в таблице процессов, поскольку обращение к ним должно производиться за пределами контекста процесса. Записи частной таблицы областей процесса, общие таблицы областей и таблицы страниц, необходимые для преобразования виртуальных адресов в физические, в связи с чем в них описываются области команд, данных, стека и другие области, принадлежащие процессу. Если несколько процессов совместно используют общие области, эти области входят составной частью в контекст каждого процесса, поскольку каждый процесс работает с этими областями независимо от других процессов. В задачи управления памятью входит идентификация участков виртуального адресного пространства процесса, не являющихся резидентными в памяти. Стек ядра, в котором хранятся записи процедур ядра, если процесс выполняется в режиме ядра. Несмотря на то, что все процессы пользуются одними и теми же программами ядра, каждый из них имеет свою собственную копию стека ядра для хранения индивидуальных обращений к функциям ядра. Пусть, например, один процесс вызывает функцию creat и приостанавливается в ожидании назначения нового индекса, а другой процесс вызывает функцию read и приостанавливается в ожидании завершения передачи данных с диска в память. Оба процесса обращаются к функциям ядра и у каждого из них имеется в наличии отдельный стек, в котором хранится последовательность выполненных обращений. Ядро должно иметь возможность восстанавливать содержимое стека ядра и положение указателя вершины стека для того, чтобы возобновлять выполнение процесса в режиме ядра. В различных системах стек ядра часто располагается в пространстве процесса, однако этот стек является логически-независимым и, таким образом, может помещаться в самостоятельной области памяти. Когда процесс выполняется в режиме задачи, соответствующий ему стек ядра пуст. Динамическая часть системного контекста процесса, состоящая из нескольких уровней и имеющая вид стека, который освобождается от элементов в порядке, обратном порядку их поступления. На каждом уровне системного контекста содержится информация, необходимая для восстановления предыдущего уровня и включающая в себя регистровый контекст предыдущего уровня.
(*) Используемые в данном разделе термины "пользовательский контекст" (user-level context), "регистровый контекст" (register context), "системный контекст" (system-level context) и "контекстные уровни" (context layers) введены автором.
Ядро помещает контекстный уровень в стек при возникновении прерывания, при обращении к системной функции или при переключении контекста процесса. Контекстный уровень выталкивается из стека после завершения обработки прерывания, при возврате процесса в режим задачи после выполнения системной функции, или при переключении контекста. Таким образом, переключение контекста влечет за собой как помещение контекстного уровня в стек, так и извлечение уровня из стека: ядро помещает в стек контекстный уровень старого процесса, а извлекает из стека контекстный уровень нового процесса. Информация, необходимая для восстановления текущего контекстного уровня, хранится в записи таблицы процессов.
На изображены компоненты контекста процесса. Слева на рисунке изображена статическая часть контекста. В нее входят: пользовательский контекст, состоящий из программ процесса (машинных инструкций), данных, стека и разделяемой памяти (если она имеется), а также статическая часть системного контекста, состоящая из записи таблицы процессов, пространства процесса и записей частной таблицы областей (информации, необходимой для трансляции виртуальных адресов пользовательского контекста). Справа на рисунке изображена динамическая часть контекста. Она имеет вид стека и включает в себя несколько элементов, хранящих регистровый контекст предыдущего уровня и стек ядра для текущего уровня. Нулевой контекстный уровень представляет собой пустой уровень, относящийся к пользовательскому контексту; увеличение стека здесь идет в адресном пространстве задачи, стек ядра недействителен. Стрелка, соединяющая между собой статическую часть системного контекста и верхний уровень динамической части контекста, означает то, что в таблице процессов хранится информация, позволяющая ядру восстанавливать текущий контекстный уровень процесса.
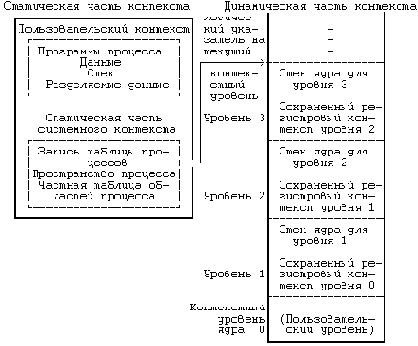
Рисунок 6.8. Компоненты контекста процесса
Процесс выполняется в рамках своего контекста или, если говорить более точно, в рамках своего текущего контекстного уровня. Количество контекстных уровней ограничивается числом поддерживаемых в машине уровней прерывания. Например, если в машине поддерживаются разные уровни прерываний для программ, терминалов, дисков, всех остальных периферийных устройств и таймера, то есть 5 уровней прерывания, то, следовательно, у процесса может быть не более 7 контекстных уровней: по одному на каждый уровень прерывания, 1 для системных функций и 1 для пользовательского контекста. 7 уровней будет достаточно, даже если прерывания будут поступать в "наихудшем" из возможных порядков, поскольку прерывание данного уровня блокируется (то есть его обработка откладывается центральным процессором) до тех пор, пока ядро не обработает все прерывания этого и более высоких уровней.
Несмотря на то, что ядро всегда исполняет контекст какого-нибудь процесса, логическая функция, которую ядро реализует в каждый момент, не всегда имеет отношение к данному процессу. Например, если возвращая данные, дисковое запоминающее устройство посылает прерывание, то прерывается выполнение текущего процесса и ядро обрабатывает прерывание на новом контекстном уровне этого процесса, даже если данные относятся к другому процессу. Программы обработки прерываний обычно не обращаются к статическим составляющим контекста процесса и не видоизменяют их, так как эти части не связаны с прерываниями.
Comments:
Copyright ©
Копирование данных между адресным пространством системы и адресным пространством задачи
До сих пор речь шла о том, что процесс выполняется в режиме ядра или в режиме задачи без каких-либо перекрытий (пересечений) между режимами. Однако, при выполнении большинства системных функций, рассмотренных в последней главе, между пространством ядра и пространством задачи осуществляется пересылка данных, например, когда идет копирование параметров вызываемой функции из пространства задачи в пространство ядра или когда производится передача данных из буферов ввода-вывода в процессе выполнения функции read. На многих машинах ядро системы может непосредственно ссылаться на адреса, принадлежащие адресному пространству задачи. Ядро должно убедиться в том, что адрес, по которому производится запись или считывание, доступен, как будто бы работа ведется в режиме задачи; в противном случае произошло бы нарушение стандартных методов защиты и ядро, пусть неумышленно, стало бы обращаться к адресам, которые находятся за пределами адресного пространства задачи (и, возможно, принадлежат структурам данных ядра). Поэтому передача данных между пространством ядра и пространством задачи является "дорогим предприятием", требующим для своей реализации нескольких команд.
| fubyte: # пересылка байта из # пространства задачи prober $3,$1,*4(ap) # байт доступен? beql eret # нет movzbl *4(ap),r0 ret eret: mnegl $1,r0 # возврат ошибки (-1) ret |
Рисунок 6.17. Пересылка данных из пространства задачи в пространство ядра в системе VAX
На Рисунке 6.17 показан пример реализованной в системе VAX программы пересылки символа из адресного пространства задачи в адресное пространство ядра. Команда prober проверяет, может ли байт по адресу, равному (регистр указателя аргумента + 4), быть считан в режиме задачи (режиме 3), и если нет, ядро передает управление по адресу eret, сохраняет в нулевом регистре -1 и выходит из программы; при этом пересылки символа не происходит. В противном случае ядро пересылает один байт, находящийся по указанному адресу, в регистр 0 и возвращает его в вызывающую программу. Пересылка 1 символа потребовала пяти команд (включая вызов функции с именем fubyte).
(***) Эти алгоритмы не следует путать с имеющими те же названия библиотечными функциями, которые могут вызываться непосредственно из пользовательских программ (см. [SVID 85]). Однако действие этих функций похоже.
Comments:
Copyright ©
Копирование содержимого области
Системная функция fork требует, чтобы ядро скопировало содержимое областей процесса. Если же область разделяемая (разделяемый текст команд или разделяемая память), ядру нет надобности копировать область физически; вместо этого оно увеличивает значение счетчика ссылок на область, позволяя родительскому и порожденному процессам использовать область совместно. Если область не является разделяемой и ядру нужно физически копировать ее содержимое, оно выделяет новую запись в таблице областей, новую таблицу страниц и отводит под создаваемую область физическую память. В качестве примера рассмотрим , где процесс A порождает с помощью функции fork процесс B и копирует области родительского процесса. Область команд процесса A является разделяемой, поэтому процесс B может использовать эту область совместно с процессом A. Однако области данных и стека родительского процесса являются его личной принадлежностью (имеют частный тип), поэтому процессу B нужно скопировать их содержимое во вновь выделенные области. При этом даже для областей частного типа физическое копирование области не всегда необходимо, в чем мы убедимся позже (). На приведен алгоритм копирования содержимого области (dupreg).
Comments:
Copyright ©
LINК
Системная функция link связывает файл с новым именем в структуре каталогов файловой системы, создавая для существующего индекса новую запись в каталоге. Синтаксис вызова функции link: link(source file name, target file name);
где source file name - существующее имя файла, а target file name - новое (дополнительное) имя, присваиваемое файлу после выполнения функции link. Файловая система хранит имя пути поиска для каждой связи, имеющейся у файла, и процессы могут обращаться к файлу по любому из этих имен. Ядро не знает, какое из имен файла является его подлинным именем, поэтому имя файла специально не обрабатывается. Например, после выполнения набора функций: link("/usr/src/uts/sys","/usr/include/sys"); link("/usr/include/realfile.h","/usr/src/uts/sys/testfile.h");
на один и тот же файл будут указывать три имени пути поиска: "/usr/src/uts/sys/testfile.h", "/usr/include/sys/testfile.h" и "/usr/include/realfile" ().
Ядро позволяет суперпользователю (и только ему) связывать каталоги, упрощая написание программ, требующих пересечения дерева файловой системы. Если бы это было разрешено произвольному пользователю, программам, пересекающим иерархическую структуру файлов, пришлось бы заботиться о том, чтобы не попасть в бесконечный цикл в том случае, если пользователь связал каталог с вершиной, стоящей ниже в иерархии. Предполагается, что суперпользователи более осторожны в указании таких связей. Возможность связывать между собой каталоги должна была поддерживаться в ранних версиях системы, так как эта возможность требуется для реализации команды mkdir, которая создает новый каталог. Включение функции mkdir устраняет необходимость в связывании каталогов.
| алгоритм link входная информация: существующее имя файла новое имя файла выходная информация: отсутствует { получить индекс для существующего имени файла (алгоритм namei); если (у файла слишком много связей или производится связывание каталога без разрешения суперпользователя) { освободить индекс (алгоритм iput); возвратить (ошибку); } увеличить значение счетчика связей в индексе; откорректировать дисковую копию индекса; снять блокировку с индекса; получить индекс родительского каталога для включения но- вого имени файла (алгоритм namei); если (файл с новым именем уже существует или существую- щий файл и новый файл находятся в разных файловых сис- темах) { отменить корректировку, сделанную выше; возвратить (ошибку); } создать запись в родительском каталоге для файла с но- вым именем: включить в нее новое имя и номер индекса существую- щего файла; освободить индекс родительского каталога (алгоритм iput); освободить индекс существующего файла (алгоритм iput); } |
Рисунок 5.29. Алгоритм связывания файлов
На Рисунке 5. 29 показан алгоритм функции link. Сначала ядро, используя алгоритм namei, определяет местонахождение индекса исходного файла, увеличивает значение счетчика связей в индексе, корректирует дисковую копию индекса (для обеспечения согласованности) и снимает с индекса блокировку. Затем ядро ищет файл с новым именем; если он существует, функция link завершается неудачно и ядро восстанавливает прежнее значение счетчика связей, измененное ранее. В противном случае ядро находит в родительском каталоге свободную запись для файла с новым именем, записывает в нее новое имя и номер индекса исходного файла и освобождает индекс родительского каталога, используя алгоритм iput. Поскольку файл с новым именем ранее не существовал, освобождать еще какой-нибудь индекс не нужно. Ядро, освобождая индекс исходного файла, делает заключение: счетчик связей в индексе имеет значение, на 1 большее, чем то значение, которое счетчик имел перед вызовом функции, и обращение к файлу теперь может производиться по еще одному имени в файловой системе. Счетчик связей хранит количество записей в каталогах, которые (записи) указывают на файл, и тем самым отличается от счетчика ссылок в индексе. Если по завершении выполнения функции link к файлу нет обращений со стороны других процессов, счетчик ссылок в индексе принимает значение, равное 0, а счетчик связей - значение, большее или равное 2.
Например, выполняя функцию, вызванную как: link("source","/dir/target");
ядро обнаруживает индекс для файла "source", увеличивает в нем значение счетчика связей, запоминает номер индекса, скажем 74, и снимает с индекса блокировку. Ядро также находит индекс каталога "dir", являющегося родительским каталогом для файла "target", ищет свободное место в каталоге "dir" и записывает в него имя файла "target" и номер индекса 74. По окончании этих действий оно освобождает индекс файла "source" по алгоритму iput. Если значение счетчика связей файла "source" раньше было равно 1, то теперь оно равно 2.
Стоит упомянуть о двух тупиковых ситуациях, явившихся причиной того, что процесс снимает с индекса исходного файла блокировку после увеличения значения счетчика связей. Если бы ядро не снимало с индекса блокировку, два процесса, выполняющие одновременно следующие функции: процесс A: link("a/b/c/d","e/f/g"); процесс B: link("e/f","a/b/c/d/ee");
зашли бы в тупик (взаимная блокировка). Предположим, что процесс A обнаружил индекс файла "a/b/c/d" в тот самый момент, когда процесс B обнаружил индекс файла "e/f". Фраза "в тот же самый момент" означает, что системой достигнуто состояние, при котором каждый процесс получил искомый индекс. ( иллюстрирует стадии выполнения процессов.) Когда же теперь процесс A попытается получить индекс файла "e/f", он приостановит свое выполнение до тех пор, пока индекс файла "f" не освободится. В то же время процесс B пытается получить индекс каталога "a/b/c/d" и приостанавливается в ожидании освобождения индекса файла "d". Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, нужный процессу A. На практике этот классический пример взаимной блокировки невозможен благодаря тому, что ядро освобождает индекс исходного файла после увеличения значения счетчика связей. Поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимная блокировка не происходит.
Следующий пример показывает, как два процесса могут зайти в тупик, если с индекса не была снята блокировка. Одиночный процесс может также заблокировать самого себя. Если он вызывает функцию: link("a/b/c","a/b/c/d");
то в начале алгоритма он получает индекс для файла "c"; если бы ядро не снимало бы с индекса блокировку, процесс зашел бы в тупик, запросив индекс "c" при поиске файла "d". Если бы два процесса, или даже один процесс, не могли продолжать свое выполнение из-за взаимной блокировки (или самоблокировки), что в результате произошло бы в системе? Поскольку индексы являются теми ресурсами, которые предоставляются системой за конечное время, получение сигнала не может быть причиной возобновления процессом своей работы (). Следовательно, система не может выйти из тупика без перезагрузки. Если к файлам, заблокированным процессами, нет обращений со стороны других процессов, взаимная блокировка не затрагивает остальные процессы в системе. Однако, любые процессы, обратившиеся к этим файлам (или обратившиеся к другим файлам через заблокированный каталог), непременно зайдут в тупик. Таким образом, если заблокированы файлы "/bin" или "/usr/bin" (обычные хранилища команд) или файл "/bin/sh" (командный процессор shell), последствия для системы будут гибельными.
Comments:
Copyright ©
МЕХАНИЗМ ПОИСКА БУФЕРА
Как показано на Рисунке 2.1, алгоритмы верхнего уровня, используемые ядром для подсистемы управления файлами, инициируют выполнение алгоритмов управления буферным кешем. При выборке блока алгоритмы верхнего уровня устанавливают логический номер устройства и номер блока, к которым они хотели бы получить доступ. Например, если процесс хочет считать данные из файла, ядро устанавливает, в какой файловой системе находится файл и в каком блоке файловой системы содержатся данные, о чем подробнее мы узнаем из . Собираясь считать данные из определенного дискового блока, ядро проверяет, находится ли блок в буферном пуле, и если нет, назначает для него свободный буфер. Собираясь записать данные в определенный дисковый блок, ядро проверяет, находится ли блок в буферном пуле, и если нет, назначает для этого блока свободный буфер. Для выделения буферов из пула в алгоритмах чтения и записи дисковых блоков используется операция getblk (Рисунок 3.4).
Рассмотрим в этом разделе пять возможных механизмов использования getblk для выделения буфера под дисковый блок.
Ядро обнаруживает блок в хеш-очереди, соответствующий ему буфер свободен. Ядро не может обнаружить блок в хеш-очереди, поэтому оно выделяет буфер из списка свободных буферов. Ядро не может обнаружить блок в хеш-очереди и, пытаясь выделить буфер из списка свободных буферов (как в случае 2), обнаруживает в списке буфер, который помечен как "занят на время записи". Ядро должно переписать этот буфер на диск и выделить другой буфер. Ядро не может обнаружить блок в хеш-очереди, а список свободных буферов пуст. Ядро обнаруживает блок в хеш-очереди, но его буфер в настоящий момент занят.
Обсудим каждый случай более подробно.
Осуществляя поиск блока в буферном пуле по комбинации номеров устройства и блока, ядро ищет хеш-очередь, которая бы содержала этот блок. Просматривая хеш-очередь, ядро придерживается списка с указателями, пока (как в первом случае) не найдет буфер с искомыми номерами устройства и блока. Ядро проверяет занятость блока и в том случае, если он свободен, помечает буфер "занятым" для того, чтобы другие процессы не смогли к нему обратиться. Затем ядро удаляет буфер из списка свободных буферов, поскольку буфер не может одновременно быть занятым и находиться в указанном списке. Если другие процессы попытаются обратиться к блоку в то время, когда его буфер занят, они приостановятся до тех пор, пока буфер не освободится. На Рисунке 3.5 показан первый случай, когда ядро ищет блок 4 в хеш-очереди, помеченной как "блок 0 модуль 4". Обнаружив буфер, ядро удаляет его из списка свободных буферов, делая блоки 5 и 28 соседями в списке.
| алгоритм getblk входная информация: номер файловой системы номер блока выходная информация: буфер, который можно использовать для блока { выполнить если (буфер не найден) { если (блок в хеш-очереди) { если (буфер занят) /* случай 5 */ { приостановиться (до освобождения буфера); продолжить; /* цикл с условием продолжения */ } пометить буфер занятым; /* случай 1 */ удалить буфер из списка свободных буферов; вернуть буфер; } в противном случае /* блока нет в хеш-очереди */ { если (в списке нет свободных буферов) /*случай 4*/ { приостановиться (до освобождения любого буфера); продолжить; /* цикл с условием продолжения */ } удалить буфер из списка свободных буферов; если (буфер помечен для отложенной переписи) /* случай 3 */ { асинхронная перепись содержимого буфера на диск; продолжить; /* цикл с условием продолжения */ } /* случай 2 -- поиск свободного буфера */ удалить буфер из старой хеш-очереди; включить буфер в новую хеш-очередь; вернуть буфер; } } } |
Рисунок 3.4. Алгоритм выделения буфера
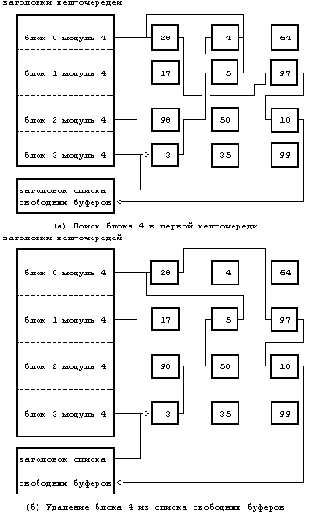
Рисунок 3.5. Поиск буфера - случай 1: буфер в хеш-очереди
| алгоритм brelse входная информация: заблокированный буфер выходная информация: отсутствует { возобновить выполнение всех процессов при наступлении события, связанного с освобождением любого буфера; возобновить выполнение всех процессов при наступлении события, связанного с освобождением данного буфера; поднять приоритет прерывания процессора так, чтобы блокировать любые прерывания; если (содержимое буфера верно и буфер не старый) поставить буфер в конец списка свободных буферов в противном случае поставить буфер в начало списка свободных буферов понизить приоритет прерывания процессора с тем, чтобы вновь разрешить прерывания; разблокировать (буфер); } |
Перед тем, как перейти к остальным случаям, рассмотрим, что произойдет с буфером после того, как он будет выделен блоку. Ядро системы сможет читать данные с диска в буфер и обрабатывать их или же переписывать данные в буфер и при желании на диск. Ядро оставляет у буфера пометку "занят"; другие процессы не могут обратиться к нему и изменить его содержимое, пока он занят, таким образом поддерживается целостность информации в буфере. Когда ядро заканчивает работу с буфером, оно освобождает буфер в соответствии с алгоритмом brelse (Рисунок 3.6). Возобновляется выполнение тех процессов, которые были приостановлены из-за того, что буфер был занят, а также те процессы, которые были приостановлены из-за того, что список свободных буферов был пуст. Как в том, так и в другом случае, высвобождение буфера означает, что буфер становится доступным для приостановленных процессов несмотря на то, что первый процесс, получивший буфер, заблокировал его и запретил тем самым получение буфера другими процессами (). Ядро помещает буфер в конец списка свободных буферов, если только перед этим не произошла ошибка ввода-вывода или если буфер не помечен как "старый" - момент, который будет пояснен далее; в остальных случаях буфер помещается в начало списка. Теперь буфер свободен для использования любым процессом.
Ядро выполняет алгоритм brelse в случае, когда буфер процессу больше не нужен, а также при обработке прерывания от диска для высвобождения буферов, используемых при асинхронном вводе-выводе с диска и на диск (). Ядро повышает приоритет прерывания работы процессора так, чтобы запретить возникновение любых прерываний от диска на время работы со списком свободных буферов, предупреждая искажение указателей буфера в результате вложенного выполнения алгоритма brelse. Похожие последствия могут произойти, если программа обработки прерываний запустит алгоритм brelse во время выполнения процессом алгоритма getblk, поэтому ядро повышает приоритет прерывания работы процессора и в стратегических моментах выполнения алгоритма getblk. Более подробно эти случаи мы разберем с помощью упражнений.
При выполнении алгоритма getblk имеет место случай 2, когда ядро просматривает хеш-очередь, в которой должен был бы находиться блок, но не находит его там. Так как блок не может быть ни в какой другой хеш-очереди, поскольку он не должен "хешироваться" в другом месте, следовательно, его нет в буферном кеше. Поэтому ядро удаляет первый буфер из списка свободных буферов; этот буфер был уже выделен другому дисковому блоку и также находится в хеш-очереди. Если буфер не помечен для отложенной переписи, ядро помечает буфер занятым, удаляет его из хеш-очереди, где он находится, назначает в заголовке буфера номера устройства и блока, соответствующие данному дисковому блоку, и помещает буфер в хеш-очередь. Ядро использует буфер, не переписав информацию, которую буфер прежде хранил для другого дискового блока. Тот процесс, который будет искать прежний дисковый блок, не обнаружит его в пуле и получит для него точно таким же образом новый буфер из списка свободных буферов. Когда ядро заканчивает работу с буфером, оно освобождает буфер вышеописанным способом. На Рисунке 3.7, например, ядро ищет блок 18, но не находит его в хеш-очереди, помеченной как "блок 2 модуль 4". Поэтому ядро удаляет первый буфер из списка свободных буферов (блок 3), назначает его блоку 18 и помещает его в соответствующую хеш-очередь.
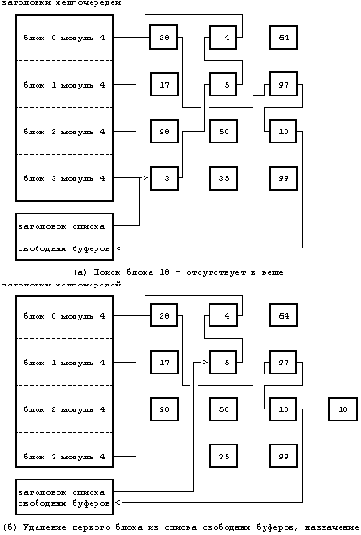
Рисунок 3.7. Второй случай выделения буфера
Если при выполнении алгоритма getblk имеет место случай 3, ядро так же должно выделить буфер из списка свободных буферов. Однако, оно обнаруживает, что удаляемый из списка буфер был помечен для отложенной переписи, поэтому прежде чем использовать буфер ядро должно переписать его содержимое на диск. Ядро приступает к асинхронной записи на диск и пытается выделить другой буфер из списка. Когда асинхронная запись заканчивается, ядро освобождает буфер и помещает его в начало списка свободных буферов. Буфер сам продвинулся от конца списка свободных буферов к началу списка. Если после асинхронной переписи ядру бы понадобилось поместить буфер в конец списка, буфер получил бы "зеленую улицу" по всему списку свободных буферов, результат такого перемещения противоположен действию алгоритма поиска буферов, к которым наиболее долго не было обращений. Например, если обратиться к Рисунку 3.8, ядро не смогло обнаружить блок 18, но когда попыталось выделить первые два буфера (по очереди) в списке свободных буферов, то оказалось, что они оба помечены для отложенной переписи. Ядро удалило их из списка, запустило операции переписи на диск в соответствующие блоки, и выделило третий буфер из списка, блок 4. Далее ядро присвоило новые значения полям буфера "номер устройства" и "номер блока" и включило буфер, получивший имя "блок 18", в новую хеш-очередь.
В четвертом случае (Рисунок 3.9) ядро, работая с процессом A, не смогло найти дисковый блок в соответствующей хеш-очереди и предприняло попытку выделить из списка свободных буферов новый буфер, как в случае 2. Однако, в списке не оказалось ни одного буфера, поэтому процесс A приостановился до тех пор, пока другим процессом не будет выполнен алгоритм brelse, высвобождающий буфер. Планируя выполнение процесса A, ядро вынуждено снова просматривать хеш-очередь в поисках блока. Оно не в состоянии немедленно выделить буфер из списка свободных буферов, так как возможна ситуация, когда свободный буфер ожидают сразу несколько процессов и одному из них будет выделен вновь освободившийся буфер, на который уже нацелился процесс A. Таким образом, алгоритм поиска блока снова гарантирует, что только один буфер включает содержимое дискового блока. На Рисунке 3.10 показана конкуренция между двумя процессами за освободившийся буфер.
Последний случай (Рисунок 3.11) наиболее сложный, поскольку он связан с комплексом взаимоотношений между несколькими процессами. Предположим, что ядро, работая с процессом A, ведет поиск дискового блока и выделяет буфер, но приостанавливает выполнение процесса перед освобождением буфера. Например, если процесс A попытается считать дисковый блок и выделить буфер, как в случае 2, то он приостановится до момента завершения передачи данных с диска. Предположим, что пока процесс A приостановлен, ядро активизирует второй процесс, B, который пытается обратиться к дисковому блоку, чей буфер был только что заблокирован процессом A. Процесс B (случай 5) обнаружит этот захваченный блок в хеш-очереди. Так как использовать захваченный буфер не разрешается и, кроме того, нельзя выделить для одного и того же дискового блока второй буфер, процесс B помечает буфер как "запрошенный" и затем приостанавливается до того момента, когда процесс A освободит данный буфер.
В конце концов процесс A освобождает буфер и замечает, что он запрошен. Тогда процесс A "будит" все процессы, приостановленные по событию "буфер становится свободным", включая и процесс B. Когда же ядро вновь запустит на выполнение процесс B, процесс B должен будет убедиться в том, что буфер свободен. Возможно, что третий процесс, C, ждал освобождения этого же буфера, и ядро запланировало активизацию процесса C раньше B; при этом процесс C мог приостановиться и оставить буфер заблокированным. Следовательно, процесс B должен проверить то, что блок действительно свободен.
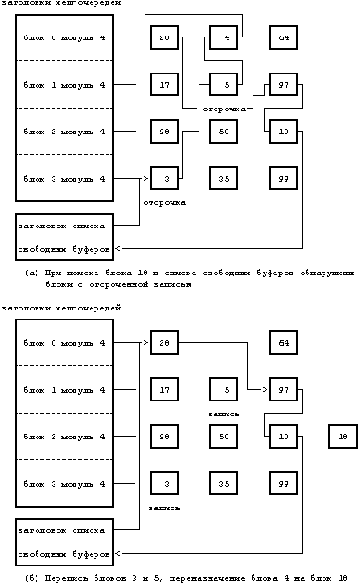
Рисунок 3.8. Третий случай выделения буфера
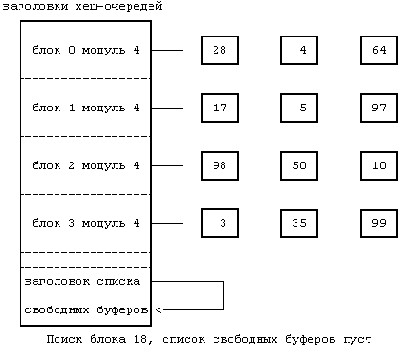
Рисунок 3.9. Четвертый случай выделения буфера
Процесс B также должен убедиться в том, что в буфере содержится первоначально затребованный дисковый блок, поскольку процесс C мог выделить данный буфер другому блоку, как в случае 2. При выполнении процесса B может обнаружиться, что он ждал освобождения буфера не с тем содержимым, поэтому процессу B придется вновь заниматься поисками блока. Если же его настроить на автоматическое выделение буфера из списка свободных буферов, он может упустить из виду возможность того, что какой-либо другой процесс уже выделил буфер для данного блока.
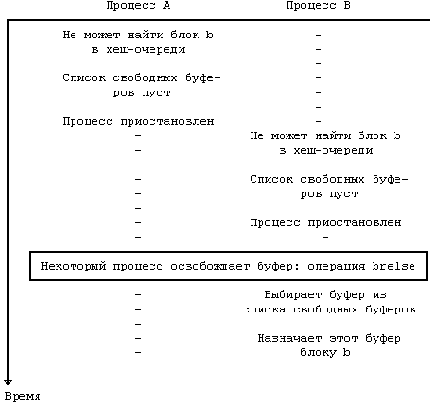
Рисунок 3.10. Состязание за свободный буфер
В конце концов, процесс B найдет этот блок, при необходимости выбрав новый буфер из списка свободных буферов, как в случае 2. Пусть некоторый процесс, осуществляя поиск блока 99 (Рисунок 3.11), обнаружил этот блок в хеш-очереди, однако он оказался занятым. Процесс приостанавливается до момента освобождения блока, после чего он запускает весь алгоритм с самого начала. На Рисунке показано содержимое занятого буфера.
Алгоритм выделения буфера должен быть надежным; процессы не должны "засыпать" навсегда и рано или поздно им нужно выделить буфер. Ядро гарантирует такое положение, при котором все процессы, ожидающие выделения буфера, продолжат свое выполнение, благодаря тому, что ядро распределяет буферы во время обработки обращений к операционной системе и освобождает их перед возвратом управления процессам . В режиме задачи процессы непосредственно не контролируют выделение буферов ядром системы, поэтому они не могут намеренно "захватывать" буферы. Ядро теряет контроль над буфером только тогда, когда ждет завершения операции ввода-вывода между буфером и диском. Было задумано так, что если дисковод испорчен, он не может прерывать работу центрального процессора, и тогда ядро никогда не освободит буфер. Дисковод должен следить за работой аппаратных средств в таких случаях и возвращать ядру код ошибки, сообщая о плохой работе диска. Короче говоря, ядро может гарантировать, что процессы, приостановленные в ожидании буфера, в конце концов возобновят свое выполнение.
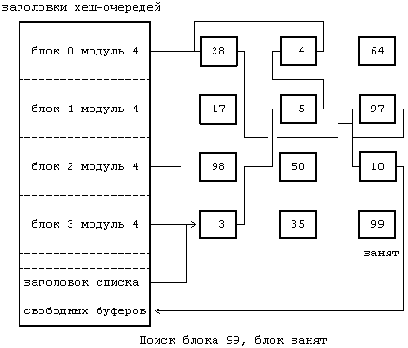
Рисунок 3.11. Пятый случай выделения буфера
Можно также представить себе ситуацию, когда процесс "зависает" в ожидании получения доступа к буферу. В четвертом случае, например, если несколько процессов приостанавливаются, ожидая освобождения буфера, ядро не гарантирует, что они получат доступ к буферу в той очередности, в которой они запросили доступ. Процесс может приостановить и возобновить свое выполнение, когда буфер станет свободным, только для того, чтобы приостановиться вновь из -за того, что другой процесс получил управление над буфером первым. Теоретически, так может продолжаться вечно, но практически такой проблемы не возникает в связи с тем, что в системе обычно заложено большое количество буферов.
(**) Из предыдущей главы напомним, что все операции ядра производятся в контексте процесса, выполняемого в режиме ядра. Таким образом, слова "другие процессы" относятся к процессам, тоже выполняющимся в режиме ядра. Эти слова мы будем использовать и тогда, когда будем говорить о взаимодействии нескольких процессов, работающих в режиме ядра; и будем говорить "ядро", когда взаимодействие между процессами будет отсутствовать.
(***) Исключением является системная операция mount, которая захватывает буфер до тех пор, пока не будет исполнена операция umount. Это исключение не является существенным, поскольку общее количество буферов намного превышает число активных монтированных файловых систем.
Comments:
Copyright ©
МОНТИРОВАНИЕ И ДЕМОНТИРОВАНИЕ ФАЙЛОВЫХ СИСТЕМ
Физический диск состоит из нескольких логических разделов, на которые он разбит дисковым драйвером, причем каждому разделу соответствует файл устройства, имеющий определенное имя. Процессы обращаются к данным раздела, открывая соответствующий файл устройства и затем ведя запись и чтение из этого "файла", представляя его себе в виде последовательности дисковых блоков. Это взаимодействие во всех деталях рассматривается в . Раздел диска может содержать логическую файловую систему, состоящую из блока начальной загрузки, суперблока, списка индексов и информационных блоков (). Системная функция mount (монтировать) связывает файловую систему из указанного раздела на диске с существующей иерархией файловых систем, а функция umount (демонтировать) выключает файловую систему из иерархии. Функция mount, таким образом, дает пользователям возможность обращаться к данным в дисковом разделе как к файловой системе, а не как к последовательности дисковых блоков.
Синтаксис вызова функции mount: mount(special pathname,directory pathname,options);
где special pathname - имя специального файла устройства, соответствующего дисковому разделу с монтируемой файловой системой, directory pathname - каталог в существующей иерархии, где будет монтироваться файловая система (другими словами, точка или место монтирования), а options указывает, следует ли монтировать файловую систему "только для чтения" (при этом не будут выполняться такие функции, как write и creat, которые производят запись в файловую систему). Например, если процесс вызывает функцию mount следующим образом: mount("/dev/dsk1","/usr",0);
ядро присоединяет файловую систему, находящуюся в дисковом разделе с именем "/dev/dsk1", к каталогу "/usr" в существующем дереве файловых систем (). Файл "/dev/dsk1" является блочным специальным файлом, т.е. он носит имя устройства блочного типа, обычно имя раздела на диске. Ядро предполагает, что раздел на диске с указанным именем содержит файловую систему с суперблоком, списком индексов и корневым индексом. После выполнения функции mount к корню смонтированной файловой системы можно обращаться по имени "/usr". Процессы могут обращаться к файлам в монтированной файловой системе и игнорировать тот факт, что система может отсоединяться. Только системная функция link контролирует файловую систему, так как в версии V не разрешаются связи между файлами, принадлежащими разным файловым системам ().
Рисунок 5.22. Дерево файловых систем до и после выполнения функции mount
Ядро поддерживает таблицу монтирования с записями о каждой монтированной файловой системе. В каждой записи таблицы монтирования содержатся:
номер устройства, идентифицирующий монтированную файловую систему (упомянутый выше логический номер файловой системы); указатель на буфер, где находится суперблок файловой системы; указатель на корневой индекс монтированной файловой системы ("/" для файловой системы с именем "/dev/dsk1" на Рисунке 5.22); указатель на индекс каталога, ставшего точкой монтирования (на Рисунке 5.22 это каталог "usr", принадлежащий корневой файловой системе).
Связь индекса точки монтирования с корневым индексом монтированной файловой системы, возникшая в результате выполнения системной функции mount, дает ядру возможность легко двигаться по иерархии файловых систем без получения от пользователей дополнительных сведений.
| алгоритм mount входная информация: имя блочного специального файла имя каталога точки монтирования опции ("только для чтения") выходная информация: отсутствует { если (пользователь не является суперпользователем) возвратить (ошибку); получить индекс для блочного специального файла (алго- ритм namei); проверить допустимость значений параметров; получить индекс для имени каталога, где производится монтирование (алгоритм namei); если (индекс не является индексом каталога или счетчик ссылок имеет значение > 1) { освободить индексы (алгоритм iput); возвратить (ошибку); } найти свободное место в таблице монтирования; запустить процедуру открытия блочного устройства для данного драйвера; получить свободный буфер из буферного кеша; считать суперблок в свободный буфер; проинициализировать поля суперблока; получить корневой индекс монтируемой системы (алгоритм iget), сохранить его в таблице монтирования; сделать пометку в индексе каталога о том, что каталог является точкой монтирования; освободить индекс специального файла (алгоритм iput); снять блокировку с индекса каталога точки монтирования; } |
Рисунок 5.23. Алгоритм монтирования файловой системы
На Рисунке 5. 23 показан алгоритм монтирования файловой системы. Ядро позволяет монтировать и демонтировать файловые системы только тем процессам, владельцем которых является суперпользователь. Предоставление возможности выполнять функции mount и umount всем пользователям привело бы к внесению с их стороны хаоса в работу файловой системы, как умышленному, так и явившемуся результатом неосторожности. Суперпользователи могут разрушить систему только случайно.
Ядро находит индекс специального файла, представляющего файловую систему, подлежащую монтированию, извлекает старший и младший номера, которые идентифицируют соответствующий дисковый раздел, и выбирает индекс каталога, в котором файловая система будет смонтирована. Счетчик ссылок в индексе каталога должен иметь значение, не превышающее 1 (и меньше 1 он не должен быть - почему?), в связи с наличием потенциально опасных побочных эффектов (). Затем ядро назначает свободное место в таблице монтирования, помечает его для использования и присваивает значение полю номера устройства в таблице. Вышеуказанные назначения производятся немедленно, поскольку вызывающий процесс может приостановиться, следуя процедуре открытия устройства или считывая суперблок файловой системы, а другой процесс тем временем попытался бы смонтировать файловую систему. Пометив для использования запись в таблице монтирования, ядро не допускает использования в двух вызовах функции mount одной и той же записи таблицы. Запоминая номер устройства с монтируемой системой, ядро может воспрепятствовать повторному монтированию одной и той же системы другими процессами, которое, будь оно допущено, могло бы привести к непредсказуемым последствиям ().
Ядро вызывает процедуру открытия для блочного устройства, содержащего файловую систему, точно так же, как оно делает это при непосредственном открытии блочного устройства (). Процедура открытия устройства обычно проверяет существование такого устройства, иногда производя инициализацию структур данных драйвера и посылая команды инициализации аппаратуре. Затем ядро выделяет из буферного пула свободный буфер (вариант алгоритма getblk) для хранения суперблока монтируемой файловой системы и считывает суперблок, используя один из вариантов алгоритма read. Ядро сохраняет указатель на индекс каталога, в котором монтируется система, давая возможность маршрутам поиска файловых имен, содержащих имя "..", пересекать точку монтирования, как мы увидим дальше. Оно находит корневой индекс монтируемой файловой системы и запоминает указатель на индекс в таблице монтирования. С точки зрения пользователя, место (точка) монтирования и корень файловой системы логически эквивалентны, и ядро упрочивает эту эквивалентность благодаря их сосуществованию в одной записи таблицы монтирования. Процессы больше не могут обращаться к индексу каталога - точки монтирования.
Ядро инициализирует поля в суперблоке файловой системы, очищая поля для списка свободных блоков и списка свободных индексов и устанавливая число свободных индексов в суперблоке равным 0. Целью инициализации (задания начальных значений полей) является сведение к минимуму опасности разрушить файловую систему, если монтирование осуществляется после аварийного завершения работы системы. Если ядро заставить думать, что в суперблоке отсутствуют свободные индексы, то это приведет к запуску алгоритма ialloc, ведущего поиск на диске свободных индексов. К сожалению, если список свободных дисковых блоков испорчен, ядро не исправляет этот список изнутри ( о сопровождении файловой системы). Если пользователь монтирует файловую систему только для чтения, запрещая проведение всех операций записи в системе, ядро устанавливает в суперблоке соответствующий флаг. Наконец, ядро помечает индекс каталога как "точку монтирования", чтобы другие процессы позднее могли ссылаться на нее. На представлен вид различных структур данных по завершении выполнения функции mount.
НАЗНАЧЕНИЕ ИНДЕКСА НОВОМУ ФАЙЛУ
Для выделения известного индекса, то есть индекса, для которого предварительно определен собственный номер (и номер файловой системы), ядро использует алгоритм iget. В алгоритме namei, например, ядро определяет номер индекса, устанавливая соответствие между компонентой имени пути поиска и именем в каталоге. Другой алгоритм, ialloc, выполняет назначение дискового индекса вновь создаваемому файлу.
Как уже говорилось , в файловой системе имеется линейный список индексов. Индекс считается свободным, если поле его типа хранит нулевое значение. Если процессу понадобился новый индекс, ядро теоретически могло бы произвести поиск свободного индекса в списке индексов. Однако, такой поиск обошелся бы дорого, поскольку потребовал бы по меньшей мере одну операцию чтения (допустим, с диска) на каждый индекс. Для повышения производительности в суперблоке файловой системы хранится массив номеров свободных индексов в файловой системе.
| алгоритм ialloc /* выделение индекса */ входная информация: файловая система выходная информация: заблокированный индекс { выполнить { если (суперблок заблокирован) { приостановиться (пока суперблок не освободится); продолжить; /* цикл с условием продолжения */ } если (список индексов в суперблоке пуст) { заблокировать суперблок; выбрать запомненный индекс для поиска свободных индексов; искать на диске свободные индексы до тех пор, пока суперблок не заполнится, или пока не будут най- дены все свободные индексы (алгоритмы bread и brelse); снять блокировку с суперблока; возобновить выполнение процесса (как только супер- блок освободится); если (на диске отсутствуют свободные индексы) возвратить (нет индексов); запомнить индекс с наибольшим номером среди най- денных для последующих поисков свободных индек- сов; } /* список индексов в суперблоке не пуст */ выбрать номер индекса из списка индексов в супербло- ке; получить индекс (алгоритм iget); если (индекс после всего этого не свободен) /* !!! */ { переписать индекс на диск; освободить индекс (алгоритм iput); продолжить; /* цикл с условием продолжения */ } /* индекс свободен */ инициализировать индекс; переписать индекс на диск; уменьшить счетчик свободных индексов в файловой сис- теме; возвратить (индекс); } } |
На приведен алгоритм ialloc назначения новых индексов. По причинам, о которых пойдет речь ниже, ядро сначала проверяет, не заблокировал ли какой-либо процесс своим обращением список свободных индексов в суперблоке. Если список номеров индексов в суперблоке не пуст, ядро назначает номер следующего индекса, выделяет для вновь назначенного дискового индекса свободный индекс в памяти, используя алгоритм iget (читая индекс с диска, если необходимо), копирует дисковый индекс в память, инициализирует поля в индексе и возвращает индекс заблокированным. Затем ядро корректирует дисковый индекс, указывая, что к индексу произошло обращение. Ненулевое значение поля типа файла говорит о том, что дисковый индекс назначен. В простейшем случае с индексом все в порядке, но в условиях конкуренции делается необходимым проведение дополнительных проверок, на чем мы еще кратко остановимся. Грубо говоря, конкуренция возникает, когда несколько процессов вносят изменения в общие информационные структуры, так что результат зависит от очередности выполнения процессов, пусть даже все процессы будут подчиняться протоколу блокировки. Здесь предполагается, например, что процесс мог бы получить уже используемый индекс. Конкуренция связана с проблемой взаимного исключения, описанной в главе 2, с одним замечанием: различные схемы блокировки решают проблему взаимного исключения, но не могут сами по себе решить все проблемы конкуренции.
Если список свободных индексов в суперблоке пуст, ядро просматривает диск и помещает в суперблок как можно больше номеров свободных индексов. При этом ядро блок за блоком считывает индексы с диска и наполняет список номеров индексов в суперблоке до отказа, запоминая индекс с номером, наибольшим среди найденных. Назовем этот индекс "запомненным"; это последний индекс, записанный в суперблок. В следующий раз, когда ядро будет искать на диске свободные индексы, оно использует запомненный индекс в качестве стартовой точки, благодаря чему гарантируется, что ядру не придется зря тратить время на считывание дисковых блоков, в которых свободные индексы наверняка отсутствуют. После формирования нового набора номеров свободных индексов ядро запускает алгоритм назначения индекса с самого начала. Всякий раз, когда ядро назначает дисковый индекс, оно уменьшает значение счетчика свободных индексов, записанное в суперблоке.
Рассмотрим две пары массивов номеров свободных индексов (Рисунок 4.13). Если список свободных индексов в суперблоке имеет вид первого массива на Рисунке 4.13(а) при назначении индекса ядром, то значение указателя на следующий номер индекса уменьшается до 18 и выбирается индекс с номером 48. Если же список выглядит как первый массив на Рисунке 4.13(б), ядро заметит, что массив пуст и обратится в поисках свободных индексов к диску, при этом поиск будет производиться, начиная с индекса с номером 470, который был ранее запомнен. Когда ядро заполнит список свободных индексов в суперблоке до отказа, оно запомнит последний индекс в качестве начальной точки для последующих просмотров диска. Ядро производит назначение файлу только что выбранного с диска индекса (под номером 471 на рисунке) и продолжает прерванную обработку.
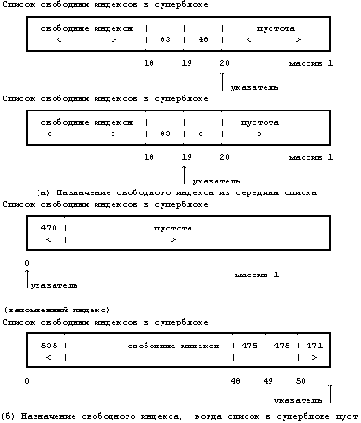
Рисунок 4.13. Два массива номеров свободных индексов
| алгоритм ifree /* освобождение индекса */ входная информация: номер индекса в файловой системе выходная информация: отсутствует { увеличить на 1 счетчик свободных индексов в файловой системе; если (суперблок заблокирован) возвратить управление; если (список индексов заполнен) { если (номер индекса меньше номера индекса, запом- ненного для последующего просмотра) запомнить для последующего просмотра номер введенного индекса; } в противном случае сохранить номер индекса в списке индексов; возвратить управление; } |
Алгоритм освобождения индекса построен значительно проще. Увеличив на единицу общее количество доступных в файловой системе индексов, ядро проверяет наличие блокировки у суперблока. Если он заблокирован, ядро, чтобы предотвратить конкуренцию, немедленно сообщает: номер индекса отсутствует в суперблоке, но индекс может быть найден на диске и доступен для переназначения. Если список не заблокирован, ядро проверяет, имеется ли место для новых номеров индексов и если да, помещает номер индекса в список и выходит из алгоритма. Если список полон, ядро не сможет в нем сохранить вновь освобожденный индекс. Оно сравнивает номер освобожденного индекса с номером запомненного индекса. Если номер освобожденного индекса меньше номера запомненного, ядро запоминает номер вновь освобожденного индекса, выбрасывая из суперблока номер старого запомненного индекса. Индекс не теряется, поскольку ядро может найти его, просматривая список индексов на диске. Ядро поддерживает структуру списка в суперблоке таким образом, что последний номер, выбираемый им из списка, и есть номер запомненного индекса. В идеале не должно быть свободных индексов с номерами, меньшими, чем номер запомненного индекса, но возможны и исключения.
Рассмотрим два примера освобождения индексов. Если в списке свободных индексов в суперблоке еще есть место для новых номеров свободных индексов (как на Рисунке 4.13(а)), ядро помещает в список новый номер, переставляет указатель на следующий свободный индекс и продолжает выполнение процесса. Но если список свободных индексов заполнен (Рисунок 4.15), ядро сравнивает номер освобожденного индекса с номером запомненного индекса, с которого начнется просмотр диска в следующий раз. Если вначале список свободных индексов имел вид, как на Рисунке 4.15(а), то когда ядро освобождает индекс с номером 499, оно запоминает его и выталкивает номер 535 из списка. Если затем ядро освобождает индекс с номером 601, содержимое списка свободных индексов не изменится. Когда позднее ядро использует все индексы из списка свободных индексов в суперблоке, оно обратится в поисках свободных индексов к диску, при этом, начав просмотр с индекса с номером 499, оно снова обнаружит индексы 535 и 601.
Рисунок 4.15. Размещение номеров свободных индексов в суперблоке

Рисунок 4.16. Конкуренция в назначении индексов
В предыдущем параграфе описывались простые случаи работы алгоритмов. Теперь рассмотрим случай, когда ядро назначает новый индекс и затем копирует его в память. В алгоритме предполагается, что ядро может и обнаружить, что индекс уже назначен. Несмотря на редкость такой ситуации, обсудим этот случай (с помощью Рисунков 4.16 и 4.17). Пусть у нас есть три процесса, A, B и C, и пусть ядро, действуя от имени процесса A , назначает индекс I, но приостанавливает выполнение процесса перед тем, как скопировать дисковый индекс в память. Алгоритмы iget (вызванный алгоритмом ialloc) и bread (вызванный алгоритмом iget) дают процессу A достаточно возможностей для приостановления своей работы. Предположим, что пока процесс A приостановлен, процесс B пытается назначить новый индекс, но обнаруживает, что список свободных индексов в суперблоке пуст. Процесс B просматривает диск в поисках свободных индексов, и начинает это делать с индекса, имеющего меньший номер по сравнению с индексом, назначенным процессом A. Возможно, что процесс B обнаружит индекс I на диске свободным, так как процесс A все еще приостановлен, а ядро еще не знает, что этот индекс собираются назначить. Процесс B, не осознавая опасности, заканчивает просмотр диска, заполняет суперблок свободными (предположительно) индексами, назначает индекс и уходит со сцены. Однако, индекс I остается в списке номеров свободных индексов в суперблоке. Когда процесс A возобновляет выполнение, он заканчивает назначение индекса I. Теперь допустим, что процесс C затем затребовал индекс и случайно выбрал индекс I из списка в суперблоке. Когда он обратится к копии индекса в памяти, он обнаружит из установки типа файла, что индекс уже назначен. Ядро проверяет это условие и, обнаружив, что этот индекс назначен, пытается назначить другой. Немедленная перепись скорректированного индекса на диск после его назначения в соответствии с алгоритмом ialloc снижает опасность конкуренции, поскольку поле типа файла будет содержать пометку о том, что индекс использован.
Рисунок 4.17. Конкуренция в назначении индексов (продолжение)
Блокировка списка индексов в суперблоке при чтении с диска устраняет другие возможности для конкуренции. Если суперблок не заблокирован, процесс может обнаружить, что он пуст, и попытаться заполнить его с диска, время от времени приостанавливая свое выполнение до завершения операции ввода-вывода. Предположим, что второй процесс так же пытается назначить новый индекс и обнаруживает, что список пуст. Он тоже попытается заполнить список с диска. В лучшем случае, оба процесса продублируют друг друга и потратят энергию центрального процессора. В худшем, участится конкуренция, подобная той, которая описана в предыдущем параграфе. Сходным образом, если процесс, освобождая индекс, не проверил наличие блокировки списка, он может затереть номера индексов уже в списке свободных индексов, пока другой процесс будет заполнять этот список информацией с диска. И опять участится конкуренция вышеописанного типа. Несмотря на то, что ядро более или менее удачно управляется с ней, производительность системы снижается. Установка блокировки для списка свободных индексов в суперблоке устраняет такую конкуренцию.
(***) Как и в предыдущей главе, здесь под "процессом" имеется ввиду "ядро, действующее от имени процесса".
Comments:
Copyright ©
Назначение операторского терминала
Операторский терминал - это терминал, с которого пользователь регистрируется в системе, он управляет процессами, запущенными пользователем с терминала. Когда процесс открывает терминал, драйвер терминала открывает строковый интерфейс. Если процесс возглавляет группу процессов как результат выполнения системной функции setpgrp и если процесс не связан с одним из операторских терминалов, строковый интерфейс делает открываемый терминал операторским. Он сохраняет старший и младший номера устройства для файла терминала в адресном пространстве, выделенном процессу, а номер группы процессов, связанной с открываемым процессом, в структуре данных терминального драйвера. Открываемый процесс становится управляющим процессом, обычно входным (начальным) командным процессором, что мы увидим далее.
Операторский терминал играет важную роль в обработке сигналов. Когда пользователь нажимает клавиши "delete" (удаления), "break" (прерывания), стирания или выхода, программа обработки прерываний загружает строковый интерфейс, который посылает соответствующий сигнал всем процессам в группе. Подобно этому, когда пользователь "зависает", программа обработки прерываний от терминала получает информацию о "зависании" от аппаратуры, и строковый интерфейс посылает соответствующий сигнал всем процессам в группе. Таким образом, все процессы, запущенные с конкретного терминала, получают сигнал о "зависании"; реакцией по умолчанию для большинства процессов будет выход из программы по получении сигнала; это похоже на то, как при завершении работы пользователя с терминалом из системы удаляются побочные процессы. После посылки сигнала о "зависании" программа обработки прерываний от терминала разъединяет терминал с группой процессов, чтобы процессы из этой группы не могли больше получать сигналы, возникающие на терминале.
Области
Ядро в версии V делит виртуальное адресное пространство процесса на совокупность логических областей. Область - это непрерывная зона виртуального адресного пространства процесса, рассматриваемая в качестве отдельного объекта для совместного использования и защиты. Таким образом, команды, данные и стек обычно образуют автономные области, принадлежащие процессу. Несколько процессов могут использовать одну и ту же область. Например, если несколько процессов выполняют одну и ту же программу, вполне естественно, что они используют одну и ту же область команд. Точно так же, несколько процессов могут объединиться и использовать общую область разделяемой памяти.
Ядро поддерживает таблицу областей и выделяет запись в таблице для каждой активной области в системе. В описываются поля таблицы областей и операции над областями более подробно, но на данный момент предположим, что таблица областей содержит информацию, позволяющую определить местоположение области в физической памяти. Каждый процесс имеет частную таблицу областей процесса. Записи этой таблицы могут располагаться, в зависимости от конкретной реализации, в таблице процессов, в адресном пространстве процесса или в отдельной области памяти; для простоты предположим, что они являются частью таблицы процессов. Каждая запись частной таблицы областей содержит указатель на соответствующую запись общей таблицы областей и первый виртуальный адрес процесса в данной области. Разделяемые области могут иметь разные виртуальные адреса в каждом процессе. Запись частной таблицы областей также содержит поле прав доступа, в котором указывается тип доступа, разрешенный процессу: только чтение, только запись или только исполнение. Частная таблица областей и структура области аналогичны таблице файлов и структуре индекса в файловой системе: несколько процессов могут совместно использовать адресное пространство через область, подобно тому, как они разделяют доступ к файлу с помощью индекса; каждый процесс имеет доступ к области благодаря использованию записи в частной таблице областей, точно так же он обращается к индексу, используя соответствующие записи в таблице пользовательских дескрипторов файла и в таблице файлов, принадлежащей ядру.
На Рисунке 6.2 изображены два процесса, A и B, показаны их области, частные таблицы областей и виртуальные адреса, в которых эти области соединяются. Процессы разделяют область команд 'a' с виртуальными адресами 8К и 4К соответственно. Если процесс A читает ячейку памяти с адресом 8К, а процесс
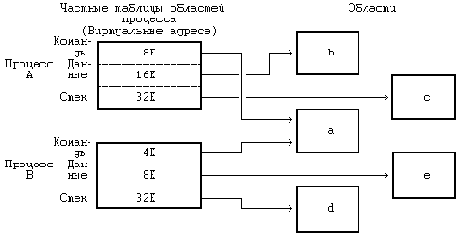
Рисунок 6.2. Процессы и области
B читает ячейку с адресом 4К, то они читают одну и ту же ячейку в области 'a'. Область данных и область стека у каждого процесса свои.
Область является понятием, не зависящим от способа реализации управления памятью в операционной системе. Управление памятью представляет собой совокупность действий, выполняемых ядром с целью повышения эффективности совместного использования оперативной памяти процессами. Примерами способов управления памятью могут служить рассматриваемые в замещение страниц памяти и подкачка по обращению. Понятие области также не зависит и от собственно распределения памяти: например, от того, делится ли память на страницы или на сегменты. С тем, чтобы заложить фундамент для перехода к описанию алгоритмов подкачки по обращению (), все приводимые здесь рассуждения относятся, в первую очередь, к организации памяти, базирующейся на страницах, однако это не предполагает, что система управления памятью основывается на указанных алгоритмах.
Обработка сигналов
Ядро обрабатывает сигналы в контексте того процесса, который получает их, поэтому чтобы обработать сигналы, нужно запустить процесс. Существует три способа обработки сигналов: процесс завершается по получении сигнала, не обращает внимание на сигнал или выполняет особую (пользовательскую) функцию по его получении. Реакцией по умолчанию со стороны процесса, исполняемого в режиме ядра, является вызов функции exit, однако с помощью функции signal процесс может указать другие специальные действия, принимаемые по получении тех или иных сигналов.
Синтаксис вызова системной функции signal: oldfunction = signal(signum,function);
где signum - номер сигнала, при получении которого будет выполнено действие, связанное с запуском пользовательской функции, function - адрес функции, oldfunction - возвращаемое функцией значение. Вместо адреса функции процесс может передавать вызываемой процедуре signal числа 1 и 0: если function = 1, процесс будет игнорировать все последующие поступления сигнала с номером signum (особый случай, связанный с игнорированием сигнала "гибель потомка", рассматривается в ), если = 0 (значение по умолчанию), процесс по получении сигнала в режиме ядра завершается. В пространстве процесса поддерживается массив полей для обработки сигналов, по одному полю на каждый определенный в системе сигнал. В поле, соответствующем сигналу с указанным номером, ядро сохраняет адрес пользовательской функции, вызываемой по получении сигнала процессом. Способ обработки сигналов одного типа не влияет на обработку сигналов других типов.
| алгоритм psig /* обработка сигналов после проверки их существования */ входная информация: отсутствует выходная информация: отсутствует { выбрать номер сигнала из записи таблицы процессов; очистить поле с номером сигнала; если (пользователь ранее вызывал функцию signal, с по- мощью которой сделал указание игнорировать сигнал дан- ного типа) возвратить управление; если (пользователь указал функцию, которую нужно выпол- нить по получении сигнала) { из пространства процесса выбрать пользовательский виртуальный адрес функции обработки сигнала; /* следующий оператор имеет нежелательные побочные эффекты */ очистить поле в пространстве процесса, содержащее адрес функции обработки сигнала; внести изменения в пользовательский контекст: искусственно создать в стеке задачи запись, ими- тирующую обращение к функции обработки сигнала; внести изменения в системный контекст: записать адрес функции обработки сигнала в поле счетчика команд, принадлежащее сохраненному ре- гистровому контексту задачи; возвратить управление; } если (сигнал требует дампирования образа процесса в па- мяти) { создать в текущем каталоге файл с именем "core"; переписать в файл "core" содержимое пользовательско- го контекста; } немедленно запустить алгоритм exit; } |
Рисунок 7.8. Алгоритм обработки сигналов
Обрабатывая сигнал (), ядро определяет тип сигнала и очищает (гасит) разряд в записи таблицы процессов, соответствующий данному типу сигнала и установленный в момент получения сигнала процессом. Если функции обработки сигнала присвоено значение по умолчанию, ядро в отдельных случаях перед завершением процесса сбрасывает на внешний носитель (дампирует) образ процесса в памяти (см. ). Дампирование удобно для программистов тем, что позволяет установить причину завершения процесса и посредством этого вести отладку программ. Ядро дампирует состояние памяти при поступлении сигналов, которые сообщают о каких-нибудь ошибках в выполнении процессов, как например, попытка исполнения запрещенной команды или обращение к адресу, находящемуся за пределами виртуального адресного пространства процесса. Ядро не дампирует состояние памяти, если сигнал не связан с программной ошибкой. Например, прерывание, вызванное нажатием клавиш "delete" или "break" на терминале, имеет своим результатом посылку сигнала, который сообщает о том, что пользователь хочет раньше времени завершить процесс, в то время как сигнал о "зависании" является свидетельством нарушения связи с регистрационным терминалом. Эти сигналы не связаны с ошибками в протекании процесса. Сигнал о выходе (quit), однако, вызывает сброс состояния памяти, несмотря на то, что он возникает за пределами выполняемого процесса. Этот сигнал, обычно вызываемый одновременным нажатием клавиш <Ctrl/|>, дает программисту возможность получать дамп состояния памяти в любой момент после запуска процесса, что бывает необходимо, если процесс попадает в бесконечный цикл выполнения одних и тех же команд (зацикливается).
Если процесс получает сигнал, на который было решено не обращать внимание, выполнение процесса продолжается так, словно сигнала и не было. Поскольку ядро не сбрасывает значение соответствующего поля, свидетельствующего о необходимости игнорирования сигнала данного типа, то когда сигнал поступит вновь, процесс опять не обратит на него внимание. Если процесс получает сигнал, реагирование на который было признано необходимым, сразу по возвращении процесса в режим задачи выполняется заранее условленное действие, однако прежде чем перевести процесс в режим задачи, ядро еще должно предпринять следующие шаги:
Ядро обращается к сохраненному регистровому контексту задачи и выбирает значения счетчика команд и указателя вершины стека, которые будут возвращены пользовательскому процессу. Сбрасывает в пространстве процесса прежнее значение поля функции обработки сигнала и присваивает ему значение по умолчанию. Создает новую запись в стеке задачи, в которую, при необходимости выделяя дополнительную память, переписывает значения счетчика команд и указателя вершины стека, выбранные ранее из сохраненного регистрового контекста задачи. Стек задачи будет выглядеть так, как будто процесс произвел обращение к пользовательской функции (обработки сигнала) в той точке, где он вызывал системную функцию или где ядро прервало его выполнение (перед опознанием сигнала). Вносит изменения в сохраненный регистровый контекст задачи: устанавливает значение счетчика команд равным адресу функции обработки сигнала, а значение указателя вершины стека равным глубине стека задачи.
Таким образом, по возвращении из режима ядра в режим задачи процесс приступит к выполнению функции обработки сигнала; после ее завершения управление будет передано на то место в программе пользователя, где было произведено обращение к системной функции или произошло прерывание, тем самым как бы имитируется выход из системной функции или прерывания.
В качестве примера можно привести программу (), которая принимает сигналы о прерывании (SIGINT) и сама посылает их (в результате выполнения функции kill). На представлены фрагменты программного кода, полученные в результате дисассемблирования загрузочного модуля в операционной среде VAX 11/780. При выполнении процесса обращение к библиотечной процедуре kill имеет адрес (шестнадцатеричный) ee; эта процедура в свою очередь, прежде чем вызвать системную функцию kill, исполняет команду chmk (перевести процесс в режим ядра) по адресу 10a. Адрес возврата из системной функции - 10c. Во время исполнения системной функции ядро посылает процессу сигнал о прерывании. Ядро обращает внимание на этот сигнал тогда, когда процесс собирается вернуться в режим задачи, выбирая из сохраненного регистрового контекста адрес возврата 10c и помещая его в стек задачи. При этом адрес функции обработки сигнала, 104, ядро помещает в сохраненный регистровый контекст задачи. На показаны различные состояния стека задачи и сохраненного регистрового контекста.
В рассмотренном алгоритме обработки сигналов имеются некоторые несоответствия. Первое из них и наиболее важное связано с очисткой перед возвращением процесса в режим задачи того поля в пространстве процесса, которое содержит адрес пользовательской функции обработки сигнала. Если процессу снова понадобится обработать сигнал, ему опять придется прибегнуть к помощи системной функции signal. При этом могут возникнуть нежелательные последствия: например, могут создаться условия для конкуренции, если второй раз сигнал поступит до того, как процесс получит возможность запустить системную функцию. Поскольку процесс выполняется в режиме задачи, ядру следовало бы произвести переключение контекста, чтобы увеличить тем самым шансы процесса на получение сигнала до момента сброса значения поля функции обработки сигнала.
|
#include <signal.h> main() { extern catcher(); signal(SIGINT,catcher); kill(0,SIGINT); } catcher() { } |
|
**** VAX DISASSEMBLER **** _main() e4: e6: pushab Ox18(pc) ec: pushl $Ox2 # в следующей строке вызывается функция signal ee: calls $Ox2,Ox23(pc) f5: pushl $Ox2 f7: clrl -(sp) # в следующей строке вызывается библиотечная процеду- ра kill f9: calls $Ox2,Ox8(pc) 100: ret 101: halt 102: halt 103: halt _catcher() 104: 106: ret 107: halt _kill() 108: # в следующей строке вызывается внутреннее прерывание операционной системы 10a: chmk $Ox25 10c: bgequ Ox6 <Ox114> 10e: jmp Ox14(pc) 114: clrl r0 116: ret | |

Рисунок 7.11. Стек задачи и область сохранения структур ядра до и после получения сигнала
Эту ситуацию можно разобрать на примере программы, представленной на . Процесс обращается к системной функции signal для того, чтобы дать указание принимать сигналы о прерываниях и исполнять по их получении функцию sigcatcher. Затем он порождает новый процесс, запускает системную функцию nice, позволяющую сделать приоритет запуска процесса-родителя ниже приоритета его потомка (см. , и входит в бесконечный цикл. Порожденный процесс задерживает свое выполнение на 5 секунд, чтобы дать родительскому процессу время исполнить системную функцию nice и снизить свой приоритет. После этого порожденный процесс входит в цикл, в каждой итерации которого он посылает родительскому процессу сигнал о прерывании (посредством обращения к функции kill). Если в результате ошибки, например, из-за того, что родительский процесс больше не существует, kill завершается, то завершается и порожденный процесс. Вся идея состоит в том, что родительскому процессу следует запускать функцию обработки сигнала при каждом получении сигнала о прерывании. Функция обработки сигнала выводит сообщение и снова обращается к функции signal при очередном появлении сигнала о прерывании, родительский же процесс продолжает исполнять циклический набор команд.
Однако, возможна и следующая очередность наступления событий:
Порожденный процесс посылает родительскому процессу сигнал о прерывании. Родительский процесс принимает сигнал и вызывает функцию обработки сигнала, но резервируется ядром, которое производит переключение контекста до того, как функция signal будет вызвана повторно. Снова запускается порожденный процесс, который посылает родительскому процессу еще один сигнал о прерывании. Родительский процесс получает второй сигнал о прерывании, но перед тем он не успел сделать никаких распоряжений относительно способа обработки сигнала. Когда выполнение родительского процесса будет возобновлено, он завершится.
|
#include <signal.h> sigcatcher() { printf("PID %d принял сигнал\n",getpid()); /* печать PID */ signal(SIGINT,sigcatcher); } main() { int ppid; signal(SIGINT,sigcatcher); if (fork() == 0) { /* дать процессам время для выполнения установок */ sleep(5); /* библиотечная функция приостанова на 5 секунд */ ppid = getppid(); /* получить идентификатор родите- ля */ for (;;) if (kill(ppid,SIGINT) == -1) exit(); } /* чем ниже приоритет, тем выше шансы возникновения кон- куренции */ nice(10); for (;;) ; } |
В программе описывается именно такое поведение процессов, поскольку вызов родительским процессом функции nice приводит к тому, что ядро будет чаще запускать на выполнение порожденный процесс.
По словам Ричи (эти сведения были получены в частной беседе), сигналы были задуманы как события, которые могут быть как фатальными, так и проходящими незаметно, которые не всегда обрабатываются, поэтому в ранних версиях системы конкуренция процессов, связанная с посылкой сигналов, не фиксировалась. Тем не менее, она представляет серьезную проблему в тех программах, где осуществляется прием сигналов. Эта проблема была бы устранена, если бы поле описания сигнала не очищалось по его получении. Однако, такое решение породило бы новую проблему: если поступающий сигнал принимается, а поле очищено, вложенные обращения к функции обработки сигнала могут переполнить стек. С другой стороны, ядро могло бы сбросить значение функции обработки сигнала, тем самым делая распоряжение игнорировать сигналы данного типа до тех пор, пока пользователь вновь не укажет, что нужно делать по получении подобных сигналов. Такое решение предполагает потерю информации, так как процесс не в состоянии узнать, сколько сигналов им было получено. Однако, информации при этом теряется не больше, чем в том случае, когда процесс получает большое количество сигналов одного типа до того, как получает возможность их обработать. В системе BSD, наконец, процесс имеет возможность блокировать получение сигналов и снимать блокировку при новом обращении к системной функции; когда процесс снимает блокировку сигналов, ядро посылает процессу все сигналы, отложенные (повисшие) с момента установки блокировки. Когда процесс получает сигнал, ядро автоматически блокирует получение следующего сигнала до тех пор, пока функция обработки сигнала не закончит работу. В этих действиях ядра наблюдается аналогия с тем, как ядро реагирует на аппаратные прерывания: оно блокирует появление новых прерываний на время обработки предыдущих.
Второе несоответствие в обработке сигналов связано с приемом сигналов, поступающих во время исполнения системной функции, когда процесс приостановлен с допускающим прерывания приоритетом. Сигнал побуждает процесс выйти из приостанова (с помощью longjump), вернуться в режим задачи и вызвать функцию обработки сигнала. Когда функция обработки сигнала завершает работу, происходит то, что процесс выходит из системной функции с ошибкой, сообщающей о прерывании ее выполнения. Узнав об ошибке, пользователь запускает системную функцию повторно, однако более удобно было бы, если бы это действие автоматически выполнялось ядром, как в системе BSD.
Третье несоответствие проявляется в том случае, когда процесс игнорирует поступивший сигнал. Если сигнал поступает в то время, когда процесс находится в состоянии приостанова с допускающим прерывания приоритетом, процесс возобновляется, но не выполняет longjump. Другими словами, ядро узнает о том, что процесс проигнорировал поступивший сигнал только после возобновления его выполнения. Логичнее было бы оставить процесс в состоянии приостанова. Однако, в момент посылки сигнала к пространству процесса, в котором ядро хранит адрес функции обработки сигнала, может отсутствовать доступ. Эта проблема может быть решена путем запоминания адреса функции обработки сигнала в записи таблицы процессов, обращаясь к которой, ядро получало бы возможность решать вопрос о необходимости возобновления процесса по получении сигнала. С другой стороны, процесс может немедленно вернуться в состояние приостанова (по алгоритму sleep), если обнаружит, что в его возобновлении не было необходимости. Однако, пользовательские процессы не имеют возможности осознавать собственное возобновление, поскольку ядро располагает точку входа в алгоритм sleep внутри цикла с условием продолжения (см. ), переводя процесс вновь в состояние приостанова, если ожидаемое процессом событие в действительности не имело места.
Ко всему сказанному выше следует добавить, что ядро обрабатывает сигналы типа "гибель потомка" не так, как другие сигналы. В частности, когда процесс узнает о получении сигнала "гибель потомка", он выключает индикацию сигнала в соответствующем поле записи таблицы процессов и по умолчанию действует так, словно никакого сигнала и не поступало. Назначение сигнала "гибель потомка" состоит в возобновлении выполнения процесса, приостановленного с допускающим прерывания приоритетом. Если процесс принимает такой сигнал, он, как и во всех остальных случаях, запускает функцию обработки сигнала. Действия, предпринимаемые ядром в том случае, когда процесс игнорирует поступивший сигнал этого типа, будут описаны в . Наконец, когда процесс вызвал функцию signal с параметром "гибель потомка" (death of child), ядро посылает ему соответствующий сигнал, если он имеет потомков, прекративших существование. В на этом моменте мы остановимся более подробно.
